Skapa och använda vyer med hjälp av en serverlös SQL-pool i Azure Synapse Analytics
I det här avsnittet får du lära dig hur du skapar och använder vyer för att omsluta serverlösa SQL-poolfrågor. Med vyer kan du återanvända dessa frågor. Vyer behövs också om du vill använda verktyg, till exempel Power BI, tillsammans med en serverlös SQL-pool.
Förutsättningar
Det första steget är att skapa en databas där vyn skapas och initiera de objekt som behövs för att autentisera i Azure Storage genom att köra installationsskriptet på databasen. Alla frågor i den här artikeln körs på exempeldatabasen.
Vyer över externa data
Du kan skapa vyer på samma sätt som du skapar vanliga SQL Server-vyer. Följande fråga skapar en vy som läser population.csv fil.
Kommentar
Ändra den första raden i frågan, t.ex. [mydbname], så att du använder databasen som du skapade.
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
Vyn använder en EXTERNAL DATA SOURCE med en rot-URL för lagringen, som en DATA_SOURCE och lägger till en relativ filsökväg till filerna.
Utsikt över Delta Lake
Om du skapar vyerna ovanpå Delta Lake-mappen måste du ange platsen till rotmappen BULK efter alternativet i stället för att ange filsökvägen.
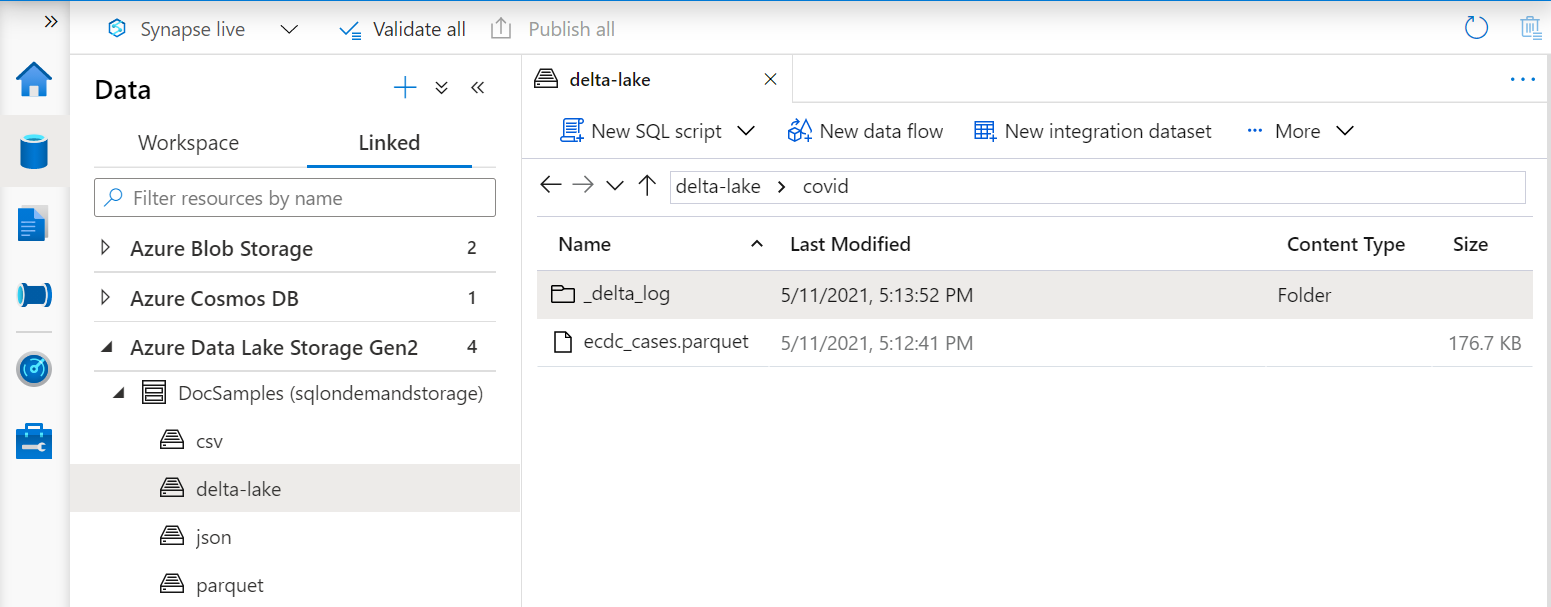
Funktionen OPENROWSET som läser data från Mappen Delta Lake undersöker mappstrukturen och identifierar automatiskt filplatserna.
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
Mer information finns på sidan med självhjälp för Synapse-serverlös SQL-pool och kända problem med Azure Synapse Analytics.
Partitionerade vyer
Om du har en uppsättning filer som är partitionerade i den hierarkiska mappstrukturen kan du beskriva partitionsmönstret med jokertecken i filsökvägen.
FILEPATH Använd funktionen för att exponera delar av mappsökvägen som partitioneringskolumner.
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
Partitionerade vyer kan förbättra prestandan för dina frågor genom att utföra partitionseliminering när du frågar dem med filter på partitioneringskolumnerna. Alla frågor stöder dock inte partitionseliminering, så det är viktigt att följa några metodtips.
Undvik att använda underfrågor i filter för att säkerställa partitionseliminering eftersom de kan störa möjligheten att eliminera partitioner. Skicka i stället resultatet av underfrågan som en variabel till filtret.
När du använder JOIN i SQL-frågor deklarerar du filterpredikatet som NVARCHAR för att minska frågeplanens komplexitet och öka sannolikheten för korrekt partitionseliminering. Partitionskolumner härleds vanligtvis som NVARCHAR(1024), så att använda samma typ för predikatet undviker behovet av en implicit gjutning, vilket kan öka frågeplanskomplexiteten.
Partitionerade vyer i Delta Lake
Om du skapar de partitionerade vyerna ovanpå Delta Lake Storage kan du bara ange en Delta Lake-rotmapp och inte uttryckligen exponera partitioneringskolumnerna med hjälp av FILEPATH funktionen:
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
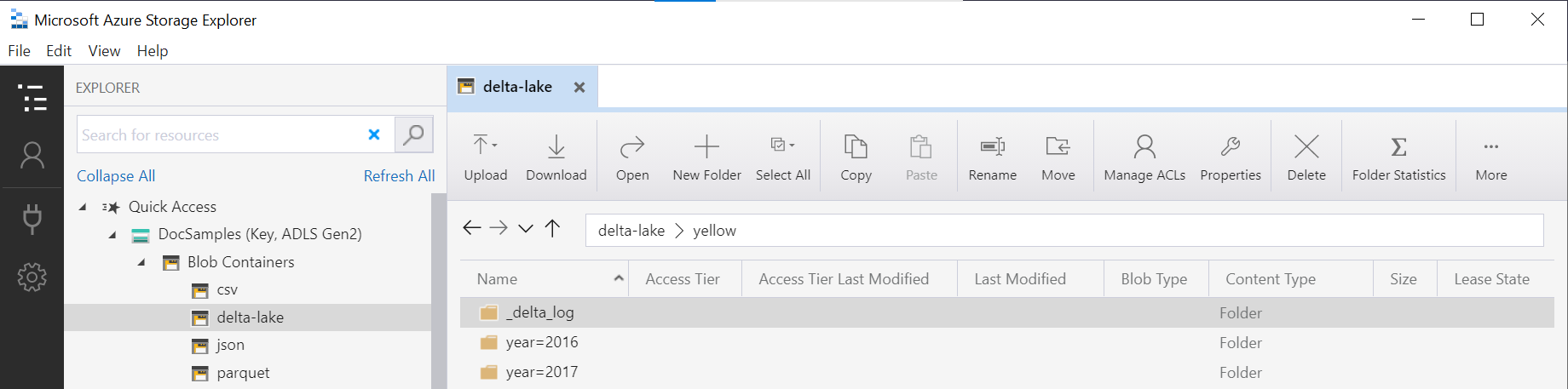
Funktionen OPENROWSET undersöker strukturen för den underliggande Delta Lake-mappen och identifierar och exponerar automatiskt partitioneringskolumnerna. Partitionseliminering görs automatiskt om du placerar partitioneringskolumnen WHERE i satsen för en fråga.
Mappnamnet i OPENROWSET funktionen (yellow i det här exemplet) som sammanfogas med den LOCATION URI som definierats i DeltaLakeStorage datakällan måste referera till rotmappen Delta Lake som innehåller en undermapp med namnet _delta_log.
Mer information finns på sidan med självhjälp för Synapse-serverlös SQL-pool och kända problem med Azure Synapse Analytics.
JSON-vyer
Vyerna är det bästa valet om du behöver utföra lite extra bearbetning ovanpå resultatuppsättningen som hämtas från filerna. Ett exempel kan vara att parsa JSON-filer där vi behöver använda JSON-funktionerna för att extrahera värdena från JSON-dokumenten:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
Funktionen OPENJSON parsar varje rad från JSONL-filen som innehåller ett JSON-dokument per rad i textformat.
Azure Cosmos DB-vyer på containrar
Vyerna kan skapas ovanpå Azure Cosmos DB-containrarna om Azure Cosmos DB-analyslagringen är aktiverad i containern. Azure Cosmos DB-kontonamnet, databasnamnet och containernamnet bör läggas till som en del av vyn och den skrivskyddade åtkomstnyckeln ska placeras i databasens begränsade autentiseringsuppgifter som vyn refererar till.
Det här exempelskriptet använder en databas och container som du kan konfigurera genom att följa dessa instruktioner.
Viktigt!
I skriptet ersätter du dessa värden med dina egna värden:
- your-cosmosdb – namnet på ditt Cosmos DB-konto
- access-key – din Cosmos DB-kontonyckel
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
Mer information finns i Fråga Azure Cosmos DB-data med en serverlös SQL-pool i Azure Synapse Link.
Använda en vy
Du kan använda vyer i dina frågor på samma sätt som du använder vyer i SQL Server-frågor.
Följande fråga visar hur du använder population_csv vy som vi skapade i Skapa en vy. Den returnerar namn på land/region med sin befolkning 2019 i fallande ordning.
Kommentar
Ändra den första raden i frågan, t.ex. [mydbname], så att du använder databasen som du skapade.
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
När du frågar vyn kan det uppstå fel eller oväntade resultat. Det innebär förmodligen att vyn refererar till kolumner eller objekt som har ändrats eller inte längre finns. Du måste justera vydefinitionen manuellt så att den överensstämmer med de underliggande schemaändringarna.
Relaterat innehåll
Information om hur du kör frågor mot olika filtyper finns i artiklarna Query Single CSV-fil, Query Parquet-filer och Query JSON-filer .