Analysera data med Azure Machine Learning
I den här självstudien används Azure Machine Learning-designern för att skapa en förutsägelsemodell för maskininlärning. Modellen baseras på data som lagras i Azure Synapse. Scenariot för självstudiekursen är att förutsäga om en kund sannolikt kommer att köpa en cykel eller inte så att Adventure Works, cykelbutiken, kan bygga en riktad marknadsföringskampanj.
Förutsättningar
För att gå igenom de här självstudierna, behöver du:
- en SQL-pool som är förinstallerad med AdventureWorksDW-exempeldata. Information om hur du etablerar den här SQL-poolen finns i Skapa en SQL-pool och välj att läsa in exempeldata. Om du redan har ett informationslager men inte har exempeldata kan du läsa in exempeldata manuellt.
- en Azure Machine Learning-arbetsyta. Följ den här självstudien för att skapa en ny.
Hämta data
De data som används finns i vyn dbo.vTargetMail i AdventureWorksDW. Om du vill använda Datastore i den här självstudien exporteras data först till Azure Data Lake Storage-kontot eftersom Azure Synapse för närvarande inte stöder datauppsättningar. Azure Data Factory kan användas för att exportera data från informationslagret till Azure Data Lake Storage med hjälp av kopieringsaktiviteten. Använd följande fråga för import:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
När data är tillgängliga i Azure Data Lake Storage används datalager i Azure Machine Learning för att ansluta till Azure Storage-tjänster. Följ stegen nedan för att skapa ett datalager och en motsvarande datauppsättning:
Starta Azure Machine Learning-studio antingen från Azure Portal eller logga in på Azure Machine Learning-studio.
Klicka på Datalager i det vänstra fönstret i avsnittet Hantera och klicka sedan på Nytt datalager.
Ange ett namn för dataarkivet, välj typen som "Azure Blob Storage", ange plats och autentiseringsuppgifter. Klicka på Skapa.
Klicka sedan på Datauppsättningar i den vänstra rutan i avsnittet Tillgångar . Välj Skapa datauppsättning med alternativet Från datalager.
Ange namnet på datauppsättningen och välj den typ som ska vara Tabell. Klicka sedan på Nästa för att gå vidare.
I avsnittet Välj eller skapa ett datalager väljer du alternativet Tidigare skapat datalager. Välj det datalager som skapades tidigare. Klicka på Nästa och ange sökvägen och filinställningarna. Se till att ange kolumnrubriken om filerna innehåller en.
Klicka slutligen på Skapa för att skapa datauppsättningen.
Konfigurera designerexperiment
Följ sedan stegen nedan för designerkonfiguration:
Klicka på fliken Designer i det vänstra fönstret i avsnittet Författare .
Välj Lättanvända fördefinierade komponenter för att skapa en ny pipeline.
I inställningsfönstret till höger anger du namnet på pipelinen.
Välj också ett målberäkningskluster för hela experimentet i inställningsknappen till ett tidigare etablerat kluster. Stäng fönstret Inställningar.
Importera data
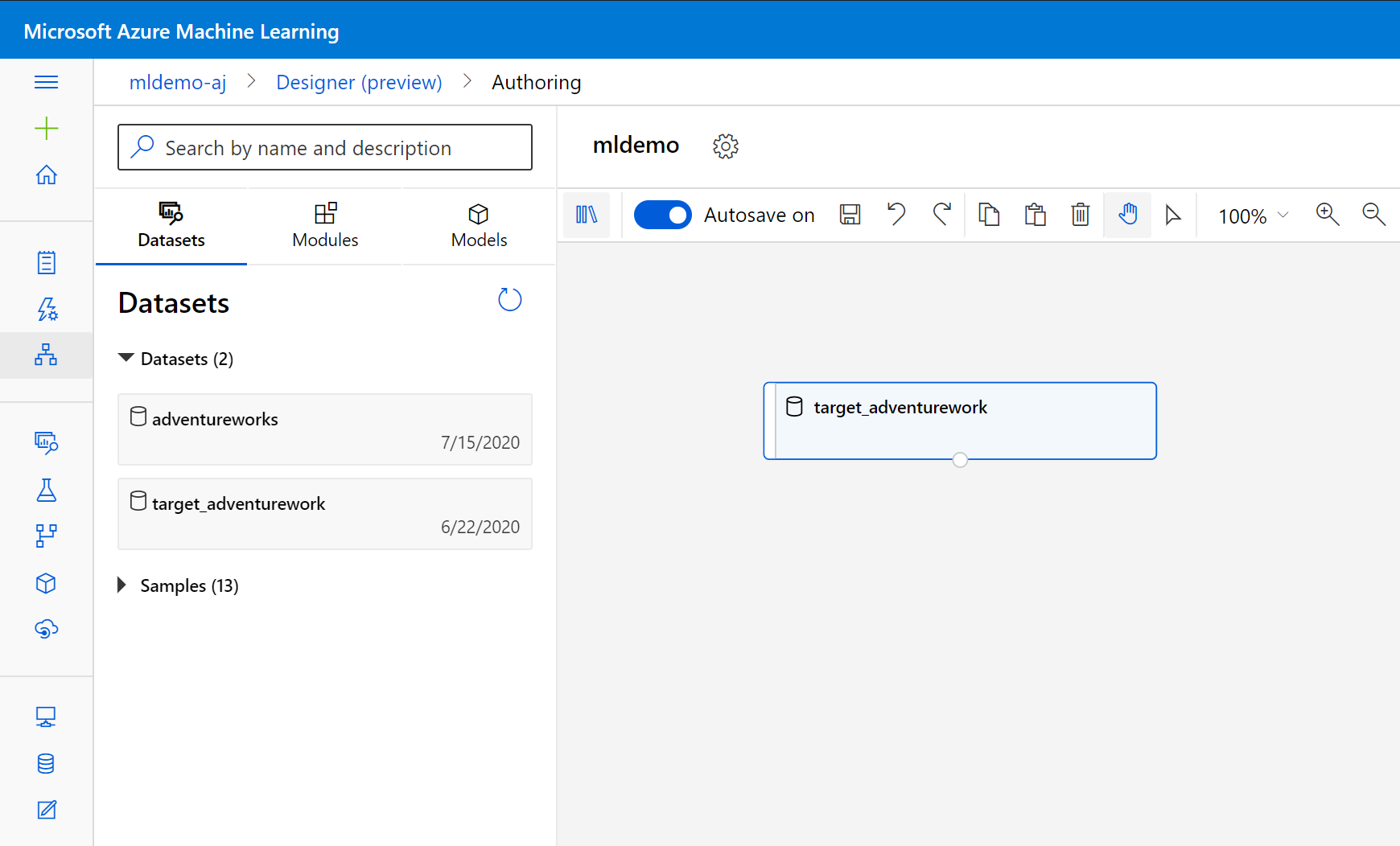
Välj underfliken Datauppsättningar i det vänstra fönstret under sökrutan.
Dra datauppsättningen som du skapade tidigare till arbetsytan.
Rensa data
Rensa data genom att släppa kolumner som inte är relevanta för modellen. Följ stegen nedan:
Välj underfliken Komponenter i den vänstra rutan.
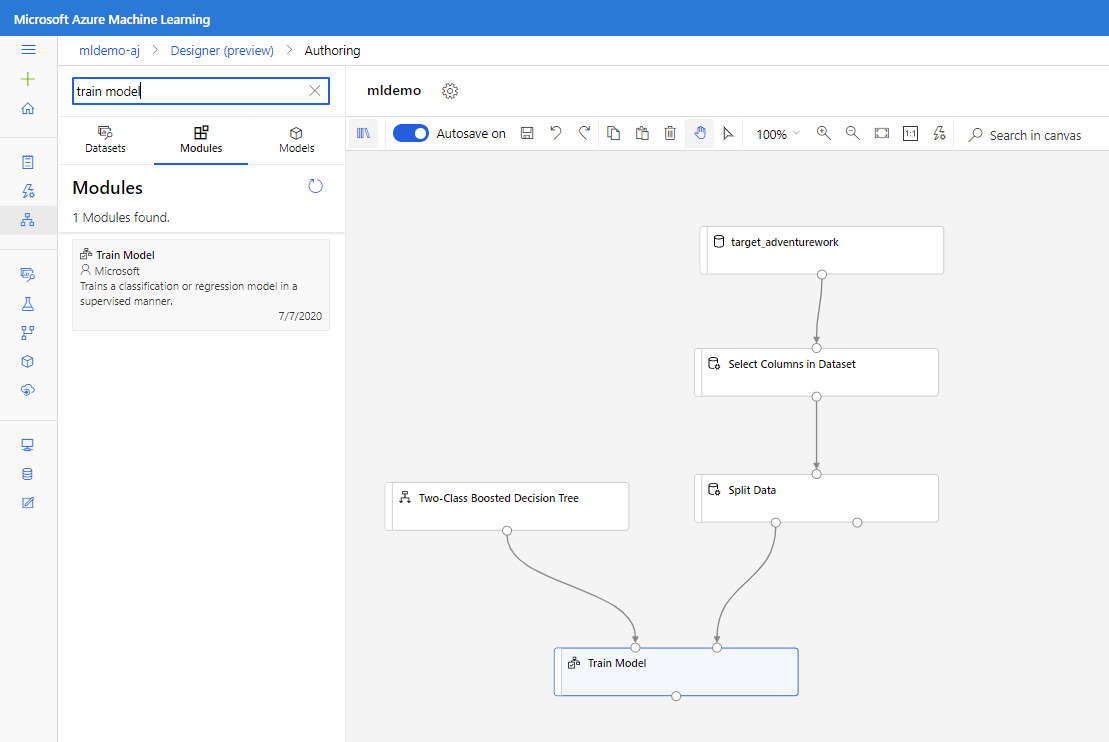
Dra komponenten Select Columns in Dataset (Välj kolumner i datauppsättning) under Datatransformeringsmanipulering < till arbetsytan. Anslut den här komponenten till datamängdskomponenten .
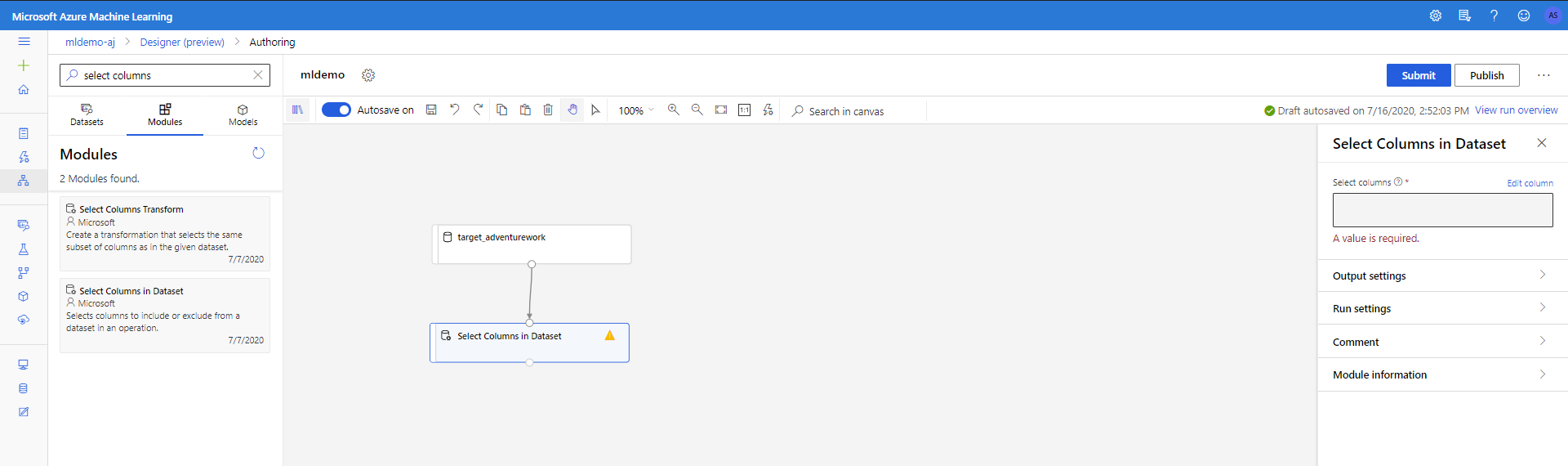
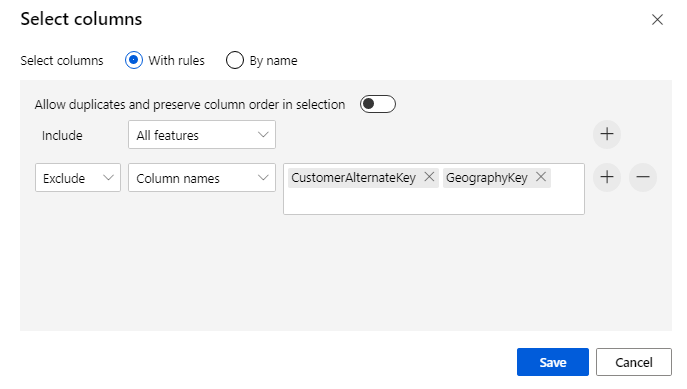
Klicka på komponenten för att öppna egenskapsfönstret. Klicka på Redigera kolumn för att ange vilka kolumner du vill släppa.
Exkludera två kolumner: CustomerAlternateKey och GeographyKey. Klicka på Spara

Bygga modellen
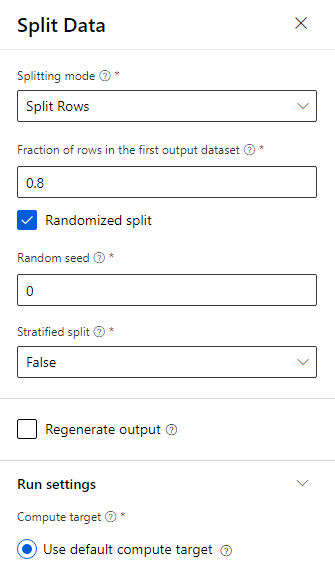
Data delas 80–20: 80 % för att träna en maskininlärningsmodell och 20 % för att testa modellen. "Tvåklassalgoritmer" används i det här binära klassificeringsproblemet.
Dra komponenten Dela data till arbetsytan.
I egenskapsfönstret anger du 0,8 för Bråk av rader i den första utdatauppsättningen.
Dra komponenten Tvåklassigt förbättrat beslutsträd till arbetsytan.
Dra komponenten Träna modell till arbetsytan. Ange indata genom att ansluta den till ML-algoritmen (Two-Class Boosted Decision Tree ) och Dela data (data som algoritmen ska tränas på).
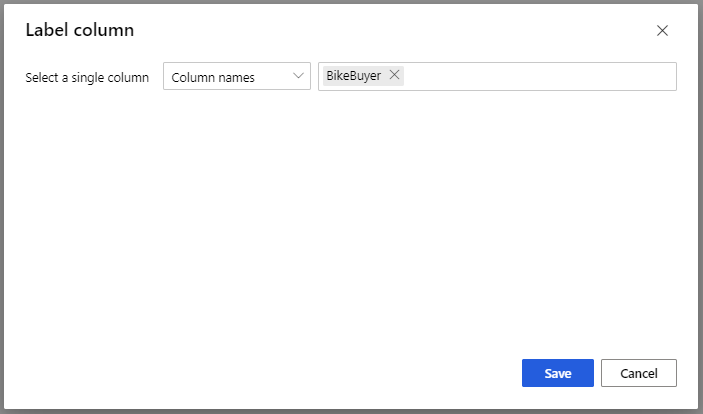
För Träna modellmodell går du till kolumnalternativet Etikett i fönstret Egenskaper och väljer Redigera kolumn. Välj kolumnen BikeBuyer som kolumn för att förutsäga och välj Spara.
Poängsätta modellen
Testa nu hur modellen fungerar på testdata. Två olika algoritmer jämförs för att se vilken som presterar bättre. Följ stegen nedan:
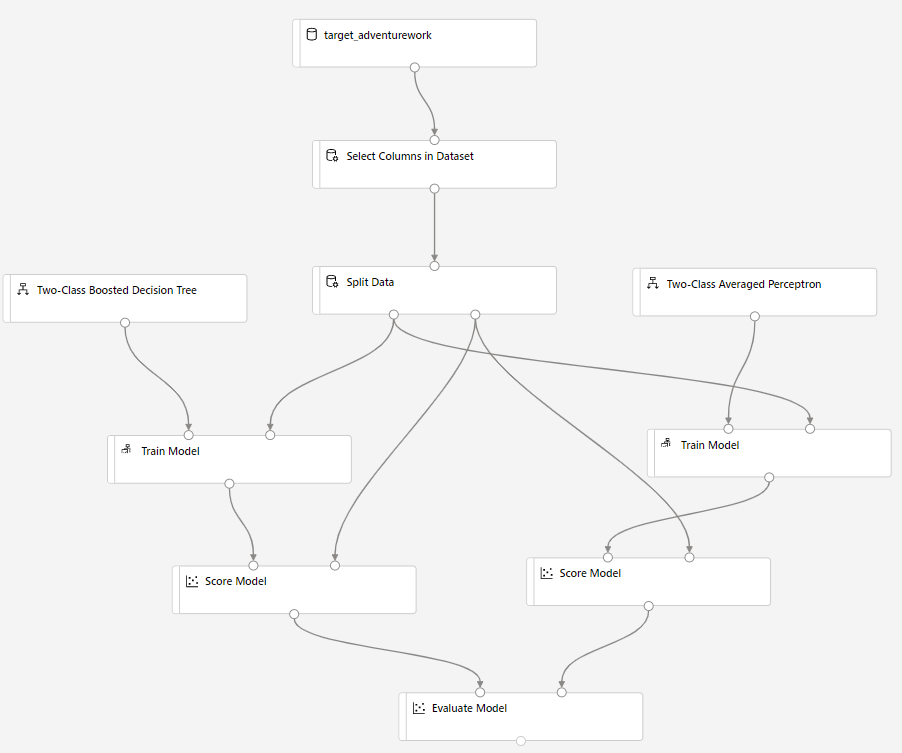
Dra Komponenten Poängsätta modell till arbetsytan och anslut den till komponenterna Träna modell och Dela data .
Dra Bayes Averaged Perceptron med två klasser till experimentarbetsytan. Du jämför hur den här algoritmen presterar i jämförelse med beslutsträdet med två klasser.
Kopiera och klistra in komponenterna Träna modell och Poängsätta modell på arbetsytan.
Dra komponenten Utvärdera modell till arbetsytan för att jämföra de två algoritmerna.
Klicka på Skicka för att konfigurera pipelinekörningen.
När körningen är klar högerklickar du på komponenten Utvärdera modell och klickar på Visualisera utvärderingsresultat.
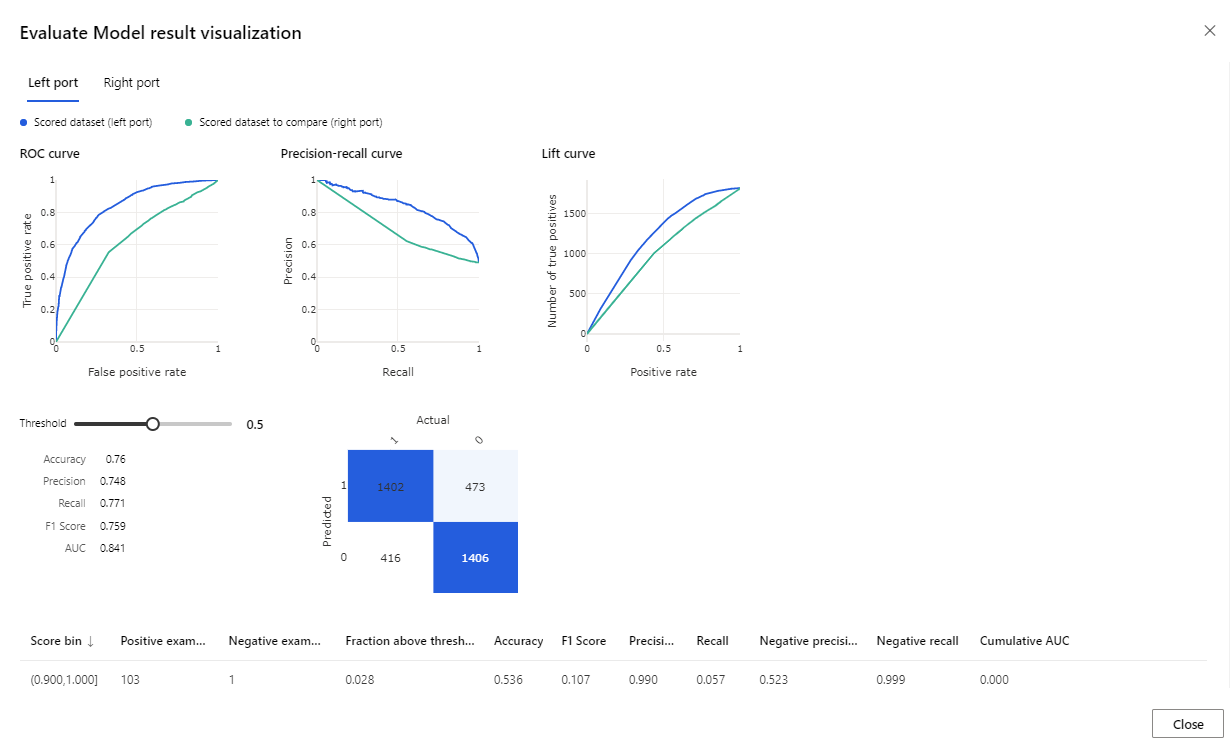

De mått som anges är ROC-kurvan, precisionsåterkallningsdiagrammet och lyftkurvan. Titta på dessa mått för att se att den första modellen presterade bättre än den andra. Om du vill titta på vad den första modellen förutsade högerklickar du på komponenten Poängsätta modell och klickar på Visualisera poängsatt datamängd för att se de förutsagda resultaten.
Du ser ytterligare två kolumner som har lagts till i testdatauppsättningen.
- Poängsatt sannolikhet: sannolikheten att en kund är en cykelköpare.
- Poängsatta etiketter: klassificering utförd av modellen – cykelköpare (1) eller inte (0). Det här sannolikhetströskelvärdet för etikettering anges till 50 % och kan justeras.
Jämför kolumnen BikeBuyer (faktisk) med Poängsatta etiketter (förutsägelse) för att se hur bra modellen har presterat. Sedan kan du använda den här modellen för att göra förutsägelser för nya kunder. Du kan publicera den här modellen som en webbtjänst eller skriva resultat tillbaka till Azure Synapse.
Nästa steg
Mer information om Azure Machine Learning finns i Introduktion till Machine Learning i Azure.
Lär dig mer om inbyggd bedömning i informationslagret här.