Självstudie: Skapa ett Apache Spark-program med IntelliJ med hjälp av en Synapse-arbetsyta
Den här självstudien visar hur du använder Plugin-programmet Azure Toolkit for IntelliJ för att utveckla Apache Spark-program, som är skrivna i Scala, och sedan skickar dem till en serverlös Apache Spark-pool direkt från IntelliJ Integrated Development Environment (IDE). Du kan använda plugin-programmet på några sätt:
- Utveckla och skicka ett Scala Spark-program i en Spark-pool.
- Få åtkomst till dina Spark-poolresurser.
- Utveckla och köra ett Scala Spark-program lokalt.
I den här självstudien lär du dig att:
- Använda plugin-programmet Azure Toolkit for IntelliJ
- Utveckla Apache Spark-program
- Skicka programmet till Spark-pooler
Förutsättningar
Plugin-programmet Azure toolkit 3.27.0-2019.2 – Installera från IntelliJ-plugin-lagringsplatsen
Scala Plugin – Installera från IntelliJ Plugin-lagringsplatsen.
Följande krav gäller endast för Windows-användare:
När du kör det lokala Spark Scala-programmet på en Windows-dator kan du få ett undantag, enligt beskrivningen i SPARK-2356. Undantaget beror på att WinUtils.exe saknas i Windows. Lös det här felet genom att ladda ned den körbara WinUtils-filen till en plats som C:\WinUtils\bin. Lägg sedan till miljövariabeln HADOOP_HOME och ange värdet för variabeln till C:\WinUtils.
Skapa ett Spark Scala-program för en Spark-pool
Starta IntelliJ IDEA och välj Skapa nytt projekt för att öppna fönstret Nytt projekt.
Välj Apache Spark/HDInsight i det vänstra fönstret.
Välj Spark-projekt med exempel (Scala) i huvudfönstret.
Välj någon av följande typer i listrutan Build tool (Skapa verktyg ):
- Maven för guidestöd när du skapar Scala-projekt.
- SBT för att hantera beroenden när du skapar Scala-projektet.
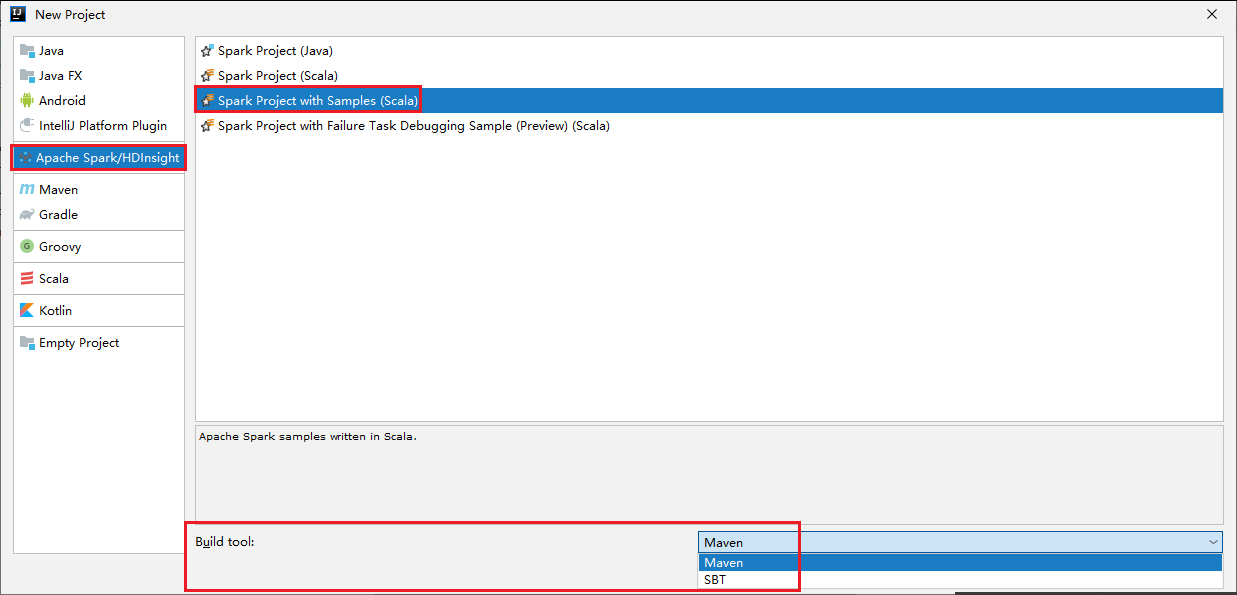
Välj Nästa.
I fönstret Nytt projekt anger du följande information:
Property beskrivning Projektnamn Ange ett namn. I den här självstudien används myApp.Projektplats Ange önskad plats för att spara projektet. Projekt-SDK Det kan vara tomt vid din första användning av IDEA. Välj Nytt... och navigera till din JDK. Spark-version Skapandeguiden integrerar rätt version för Spark SDK och Scala SDK. Här kan du välja den Spark-version som du behöver. 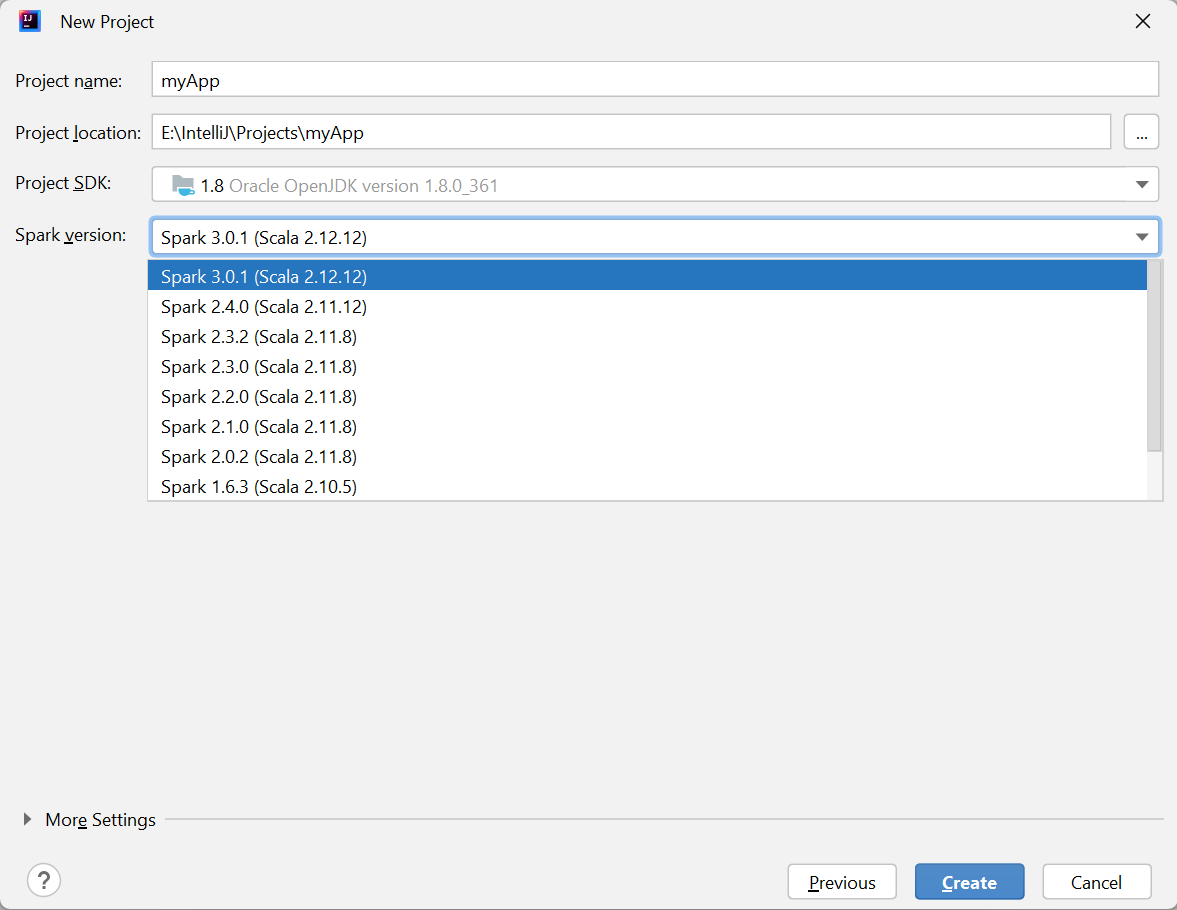
Välj Slutför. Det kan ta några minuter innan projektet blir tillgängligt.
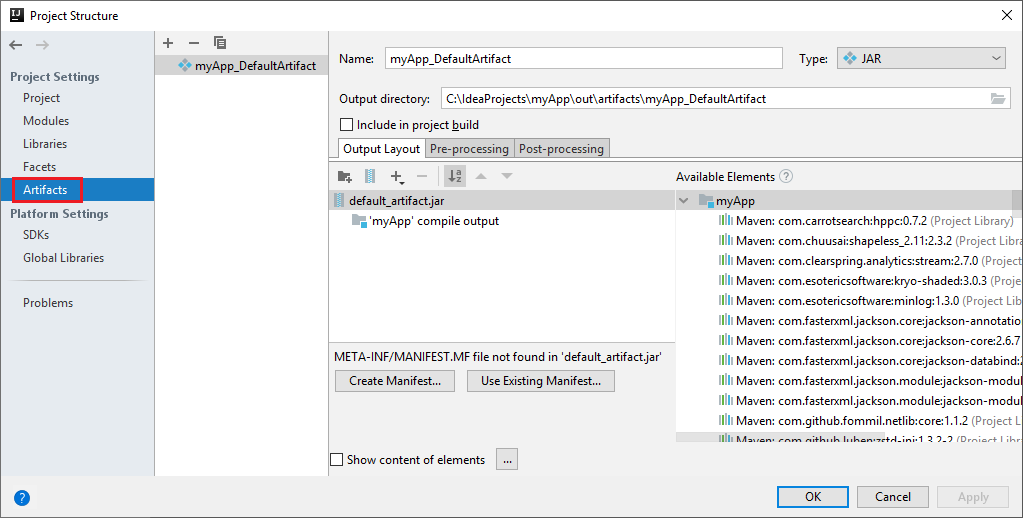
Spark-projektet skapar automatiskt en artefakt åt dig. Gör följande för att visa artefakten:
a. Från menyraden går du till Filprojektstruktur>....
b. I fönstret Projektstruktur väljer du Artefakter.
c. Välj Avbryt när du har sett artefakten.
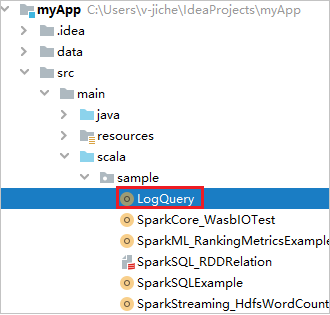
Hitta LogQuery från myApp>src>main>scala>sample>LogQuery. Den här självstudien använder LogQuery för att köra.
Ansluta till dina Spark-pooler
Logga in på Azure-prenumerationen för att ansluta till dina Spark-pooler.
Logga in till din Azure-prenumeration
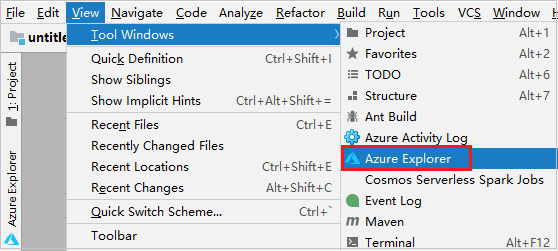
Från menyraden går du till Visa>verktyg Windows>Azure Explorer.
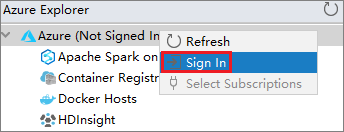
Högerklicka på Azure-noden i Azure Explorer och välj sedan Logga in.
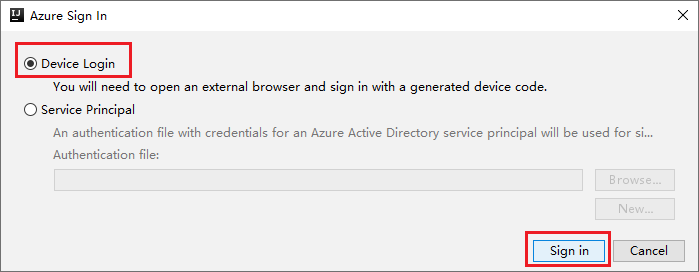
I dialogrutan Azure-inloggning väljer du Enhetsinloggning och sedan Logga in.
I dialogrutan Azure Device Login (Azure-enhetsinloggning) väljer du Kopiera och öppna.
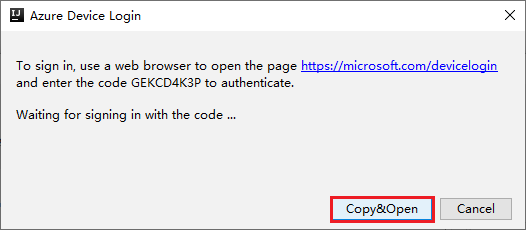
I webbläsargränssnittet klistrar du in koden och väljer sedan Nästa.
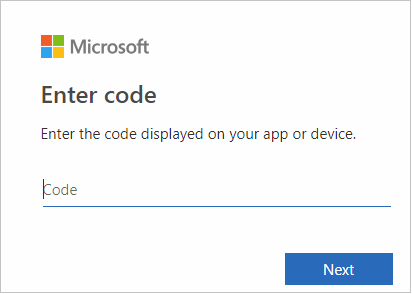
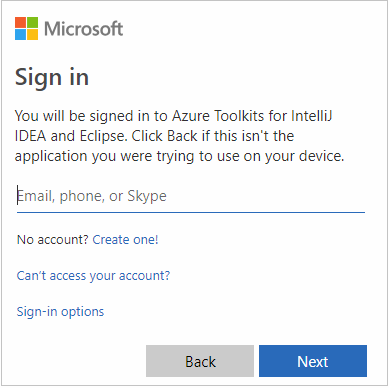
Ange dina Azure-autentiseringsuppgifter och stäng sedan webbläsaren.
När du har loggat in visas alla Azure-prenumerationer som är associerade med autentiseringsuppgifterna i dialogrutan Välj prenumerationer . Välj din prenumeration och välj sedan Välj.
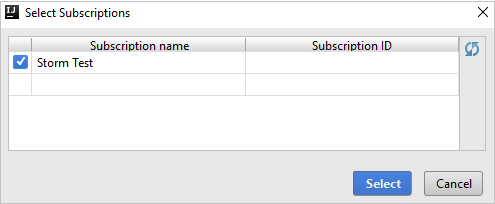
Från Azure Explorer expanderar du Apache Spark i Synapse för att visa de arbetsytor som finns i dina prenumerationer.
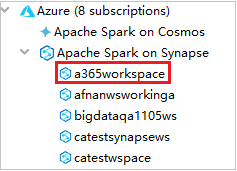
Om du vill visa Spark-poolerna kan du expandera en arbetsyta ytterligare.
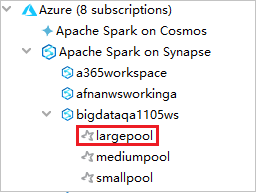
Fjärrkör ett Spark Scala-program i en Spark-pool
När du har skapat ett Scala-program kan du fjärrköra det.
Öppna fönstret Kör/felsöka konfigurationer genom att välja ikonen .
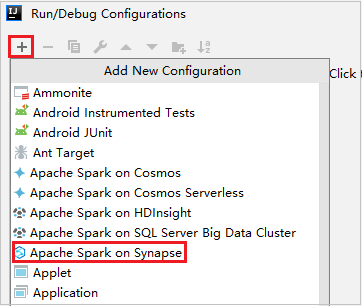
I dialogrutan Kör/felsöka konfigurationer väljer du +och väljer sedan Apache Spark i Synapse.
I fönstret Kör/felsöka konfigurationer anger du följande värden och väljer sedan OK:
Property Värde Spark-pooler Välj de Spark-pooler som du vill köra programmet på. Välj en artefakt som ska skickas Låt standardinställningen vara kvar. Huvudklassnamn Standardvärdet är huvudklassen från den valda filen. Du kan ändra klassen genom att välja ellipsen(...) och välja en annan klass. Jobbkonfigurationer Du kan ändra standardnyckeln och standardvärdena. Mer information finns i Apache Livy REST API. Kommandoradsargument Du kan ange argument avgränsade med blanksteg för huvudklassen om det behövs. Refererade jars och refererade filer Du kan ange sökvägarna för de refererade jar-filerna och filerna om det finns några. Du kan också bläddra bland filer i det virtuella Azure-filsystemet, som för närvarande endast stöder ADLS Gen2-kluster. Mer information: Apache Spark-konfiguration och Hur du laddar upp resurser till kluster. Lagring för jobbuppladdning Expandera för att visa ytterligare alternativ. Lagringstyp Välj Använd Azure Blob för att ladda upp eller Använd klusterstandardlagringskonto för att ladda upp från listrutan. Lagringskonto Ange ditt lagringskonto. Lagringsnyckel Ange lagringsnyckeln. Lagringscontainer Välj din lagringscontainer i listrutan när lagringskontot och lagringsnyckeln har angetts. 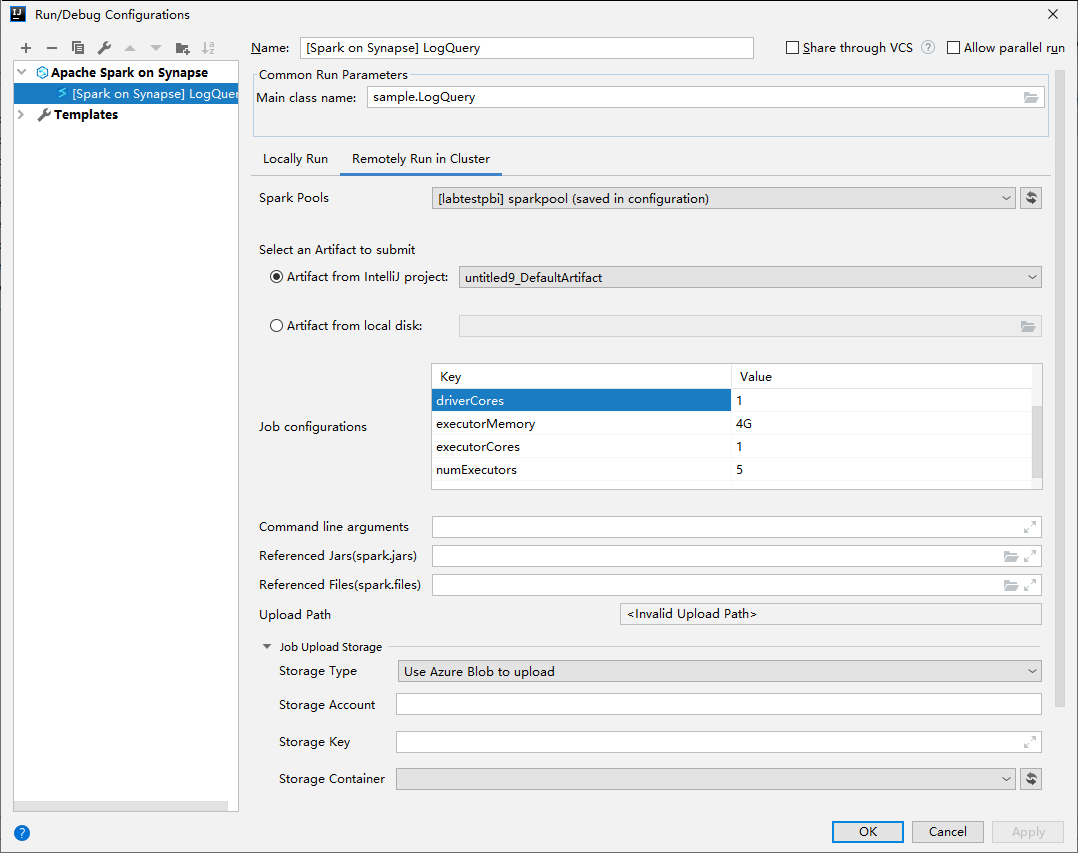
Välj SparkJobRun-ikonen för att skicka projektet till den valda Spark-poolen. Fliken Fjärr-Spark-jobb i kluster visar jobbkörningens förlopp längst ned. Du kan stoppa programmet genom att välja den röda knappen.

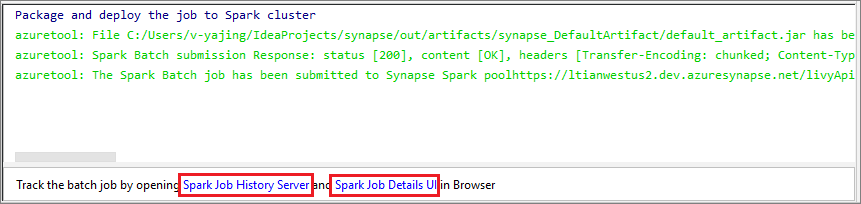
Lokala Kör/felsöka Apache Spark-program
Du kan följa anvisningarna nedan för att konfigurera din lokala körning och lokala felsökning för ditt Apache Spark-jobb.
Scenario 1: Kör lokalt
Öppna dialogrutan Kör/felsöka konfigurationer och välj plustecknet (+). Välj sedan alternativet Apache Spark på Synapse . Ange information för Namn, Huvudklassnamn att spara.
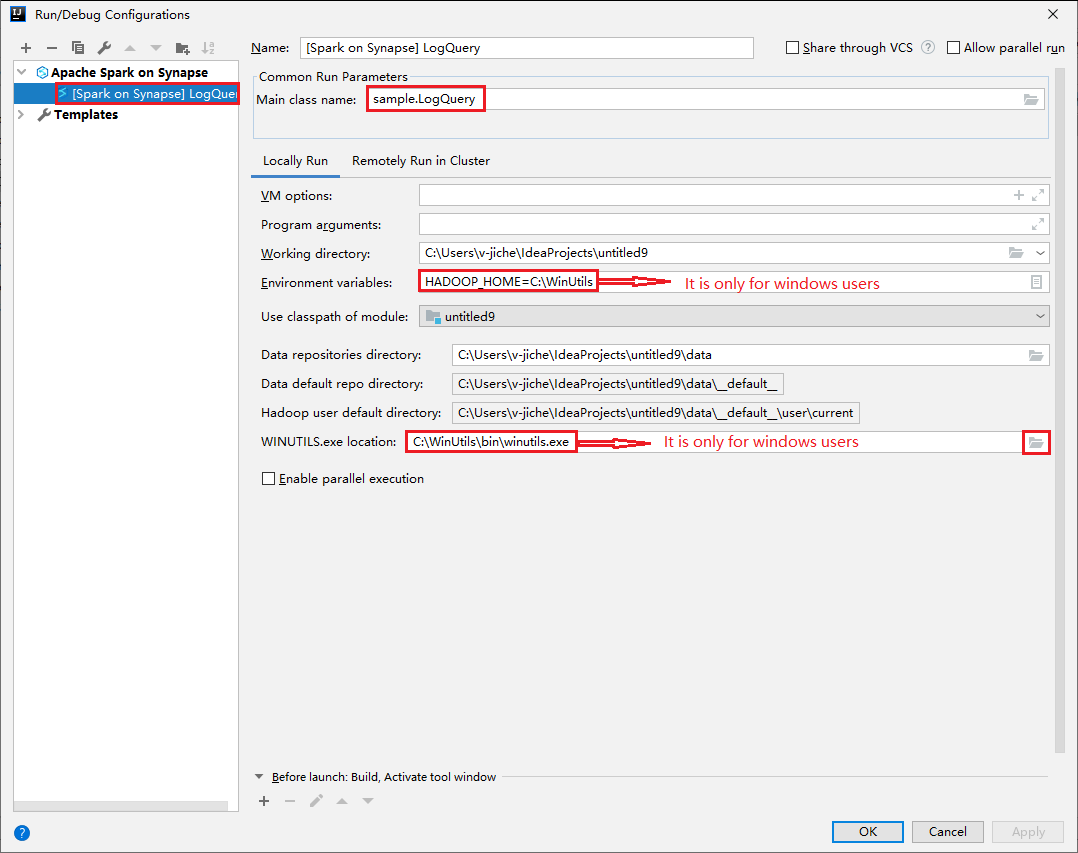
- Miljövariabler och WinUtils.exe Plats är endast för Windows-användare.
- Miljövariabler: Systemmiljövariabeln kan identifieras automatiskt om du har angett den tidigare och inte behöver lägga till den manuellt.
- WinUtils.exe Plats: Du kan ange platsen WinUtils genom att välja mappikonen till höger.
Välj sedan den lokala uppspelningsknappen.

När den lokala körningen är klar kan du kontrollera utdatafilen från standarddata> om skriptet innehåller utdata.
Scenario 2: Utför lokal felsökning
Öppna LogQuery-skriptet och ange brytpunkter.
Välj ikonen Lokal felsökning för att utföra lokal felsökning.

Få åtkomst till och hantera Synapse-arbetsyta
Du kan utföra olika åtgärder i Azure Explorer i Azure Toolkit for IntelliJ. Från menyraden går du till Visa>verktyg Windows>Azure Explorer.
Starta arbetsyta
Från Azure Explorer går du till Apache Spark i Synapse och expanderar det.
Högerklicka på en arbetsyta och välj sedan Starta arbetsyta. Webbplatsen öppnas.
Spark-konsolen
Du kan köra Spark Local Console (Scala) eller köra Spark Livy Interactive Session Console (Scala).
Lokal Spark-konsol (Scala)
Kontrollera att du har uppfyllt WINUTILS.EXE förutsättning.
Från menyraden går du till Kör>Redigera konfigurationer....
I fönstret Kör/felsöka konfigurationer går du till Apache Spark på Synapse>[Spark på Synapse] myApp i den vänstra rutan.
I huvudfönstret väljer du fliken Lokalt kör .
Ange följande värden och välj sedan OK:
Property Värde Miljövariabler Kontrollera att värdet för HADOOP_HOME är korrekt. WINUTILS.exe plats Kontrollera att sökvägen är korrekt. 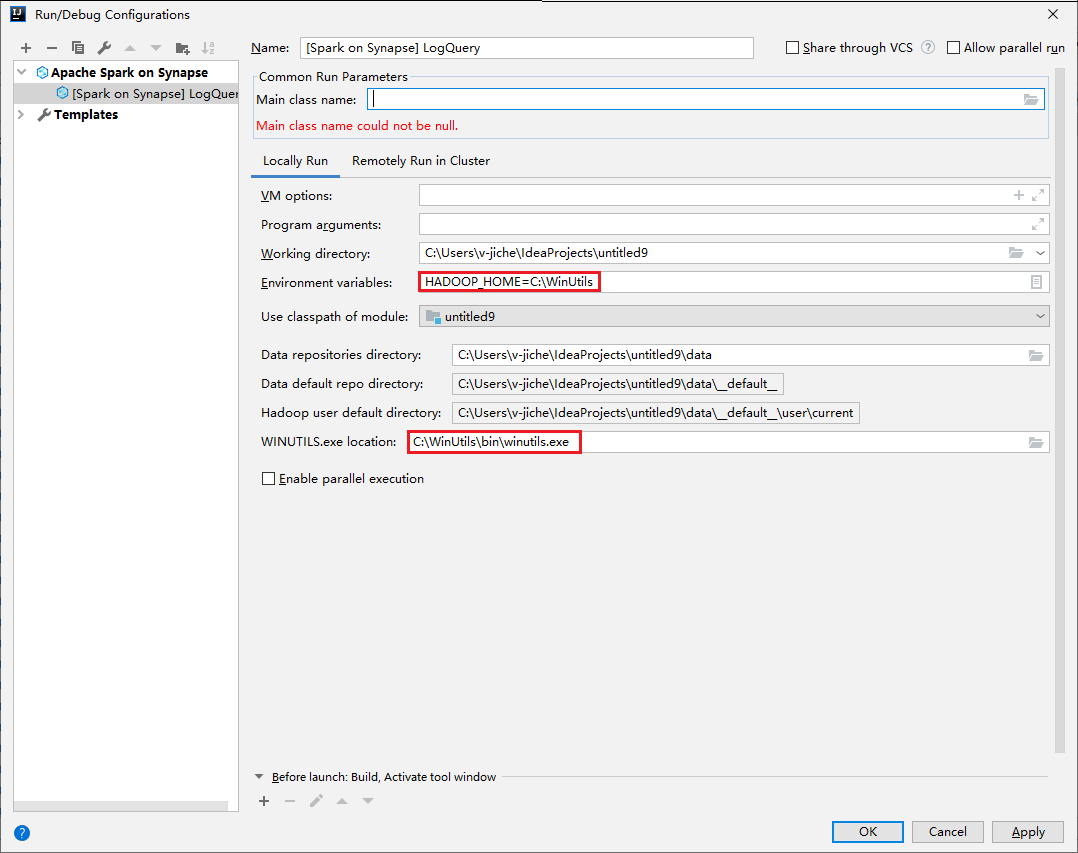
Från Project går du till myApp>src>main>scala>myApp.
Från menyraden går du till Verktyg>Spark-konsolen>Kör Spark Local Console(Scala).
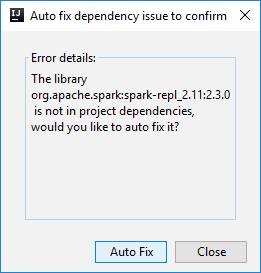
Sedan kan två dialogrutor visas för att fråga dig om du vill åtgärda beroenden automatiskt. I så fall väljer du Automatisk korrigering.
Konsolen bör se ut ungefär som bilden nedan. I konsolfönstret skriver du
sc.appNameoch trycker sedan på ctrl+Retur. Resultatet visas. Du kan stoppa den lokala konsolen genom att välja röd knapp.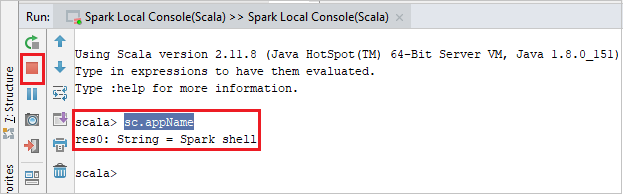
Interaktiv Spark Livy-sessionskonsol (Scala)
Det stöds bara på IntelliJ 2018.2 och 2018.3.
Från menyraden går du till Kör>Redigera konfigurationer....
Gå till Apache Spark på synapse[Spark on synapse>] myApp i fönstret Kör/Felsöka konfigurationer i det vänstra fönstret.
I huvudfönstret väljer du fliken Fjärrkörning i kluster .
Ange följande värden och välj sedan OK:
Property Värde Huvudklassnamn Välj huvudklassnamnet. Spark-pooler Välj de Spark-pooler som du vill köra programmet på. 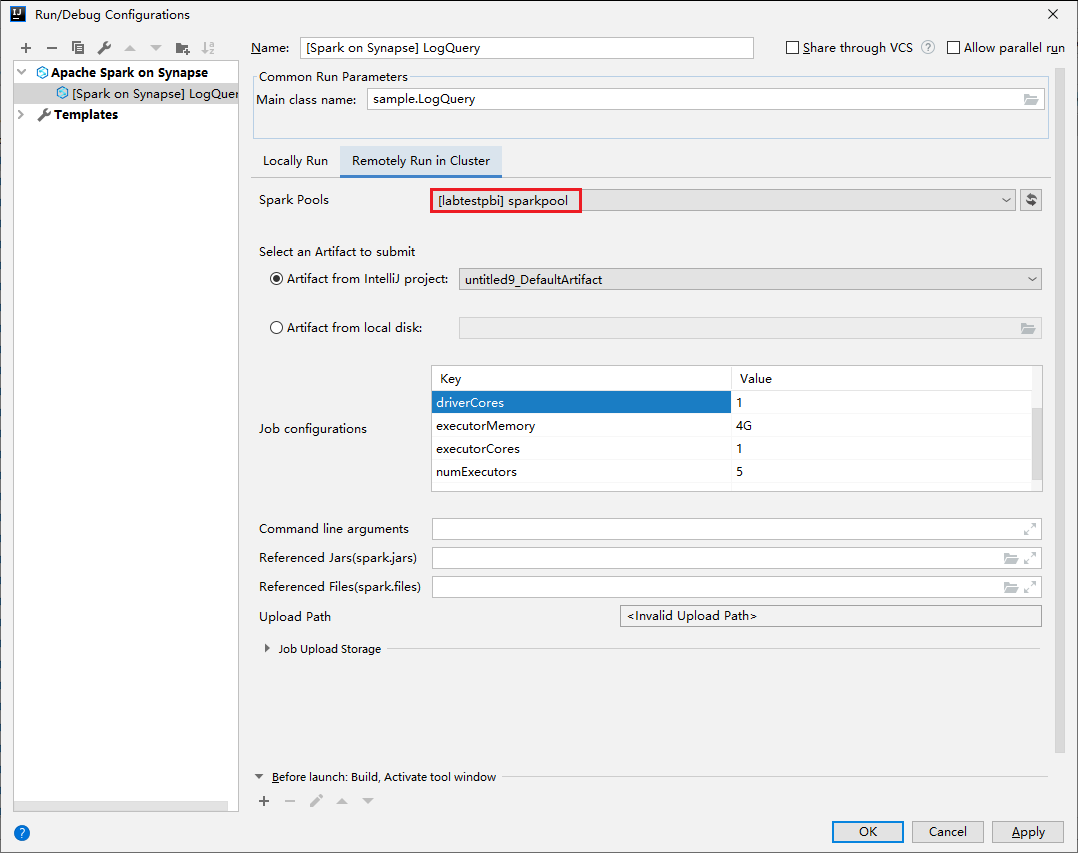
Från Project går du till myApp>src>main>scala>myApp.
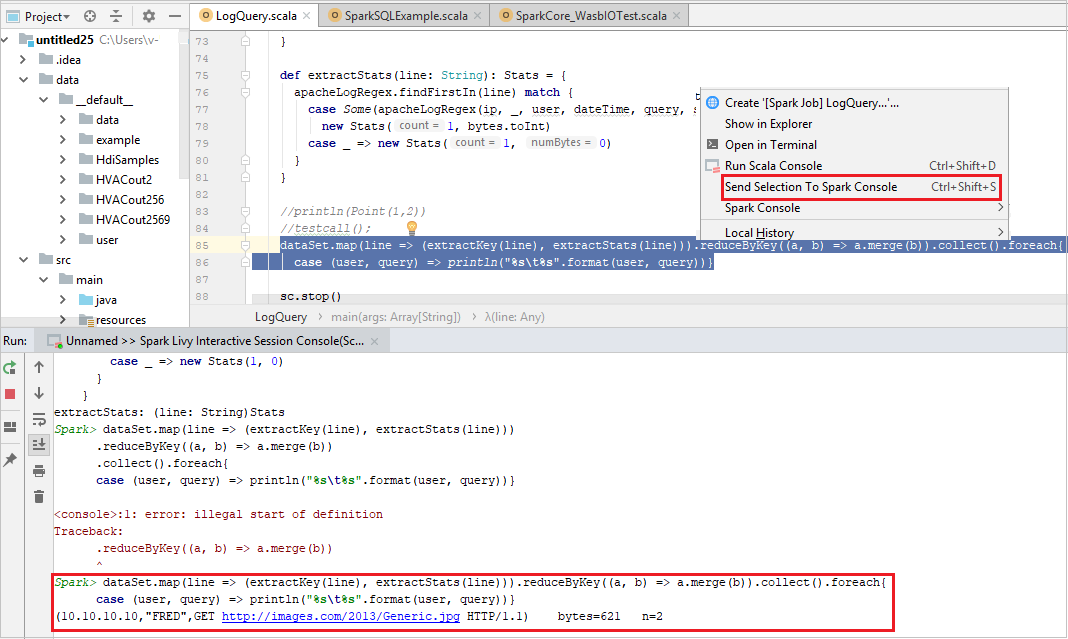
Från menyraden går du till Verktyg>Spark-konsolen>Kör Spark Livy Interactive Session Console(Scala).
Konsolen bör se ut ungefär som bilden nedan. I konsolfönstret skriver du
sc.appNameoch trycker sedan på ctrl+Retur. Resultatet visas. Du kan stoppa den lokala konsolen genom att välja röd knapp.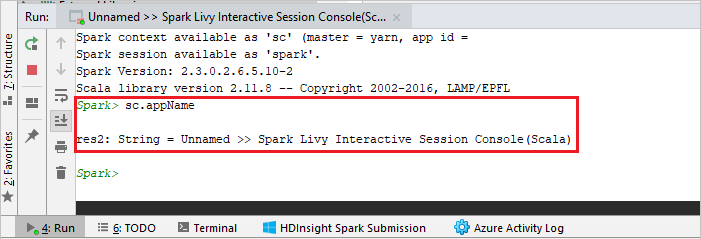
Skicka markeringen till Spark-konsolen
Du kanske vill se skriptresultatet genom att skicka kod till den lokala konsolen eller Livy Interactive Session Console (Scala). Om du vill göra det kan du markera kod i Scala-filen och sedan högerklicka på Skicka markering till Spark-konsolen. Den valda koden skickas till konsolen och görs. Resultatet visas efter koden i konsolen. Konsolen kontrollerar de befintliga felen.