Optimera Apache Spark-jobb i Azure Synapse Analytics
Lär dig hur du optimerar en Apache Spark-klusterkonfiguration för din specifika arbetsbelastning. Den vanligaste utmaningen är minnesbelastning på grund av felaktiga konfigurationer (särskilt utförare i fel storlek), långvariga åtgärder och uppgifter som resulterar i kartesiska operationer. Du kan påskynda jobb med lämplig cachelagring och genom att tillåta datasnedvridning. För bästa prestanda kan du övervaka och granska tidskrävande och resurskrävande Spark-jobbkörningar.
I följande avsnitt beskrivs vanliga Spark-jobboptimeringar och rekommendationer.
Välj dataabstraktion
Tidigare Spark-versioner använder RDD:er för att abstrahera data, Spark 1.3 och 1.6 introducerade DataFrames respektive DataSets. Tänk på följande relativa fördelar:
- DataFrames
- Bästa valet i de flesta situationer.
- Ger frågeoptimering via Catalyst.
- Kodgenerering i hela fasen.
- Direkt minnesåtkomst.
- Låg skräpinsamling (GC) overhead.
- Inte lika utvecklarvänligt som DataSets, eftersom det inte finns några kompileringstidskontroller eller domänobjektprogrammering.
- Datamängder
- Bra i komplexa ETL-pipelines där prestandapåverkan är acceptabel.
- Inte bra i sammansättningar där prestandapåverkan kan vara betydande.
- Ger frågeoptimering via Catalyst.
- Utvecklarvänlig genom att tillhandahålla domänobjektprogrammering och kompileringstidskontroller.
- Lägger till serialisering/deserialiseringskostnader.
- Höga GC-omkostnader.
- Bryter kodgenereringen i hela fasen.
- RDD:ar
- Du behöver inte använda RDD:er, såvida du inte behöver skapa en ny anpassad RDD.
- Ingen frågeoptimering via Catalyst.
- Ingen kodgenerering i hela fasen.
- Höga GC-omkostnader.
- Måste använda Äldre API:er för Spark 1.x.
Använd optimalt dataformat
Spark stöder många format, till exempel csv, json, xml, parquet, orc och avro. Spark kan utökas för att stödja många fler format med externa datakällor – mer information finns i Apache Spark-paket.
Det bästa formatet för prestanda är parquet med snabb komprimering, vilket är standard i Spark 2.x. Parquet lagrar data i kolumnformat och är mycket optimerad i Spark. Dessutom kan snabb komprimering resultera i större filer än t.ex. gzip-komprimering. På grund av den splittable karaktären av dessa filer, kommer de att dekomprimera snabbare.
Använd cachen
Spark har egna interna cachelagringsmekanismer som kan användas med olika metoder som .persist(), .cache()och CACHE TABLE. Den här interna cachelagringen är effektiv med små datamängder och i ETL-pipelines där du behöver cachelagra mellanliggande resultat. Den inbyggda Spark-cachelagringen fungerar dock för närvarande inte bra med partitionering, eftersom en cachelagrad tabell inte behåller partitioneringsdata.
Använd minnet effektivt
Spark fungerar genom att placera data i minnet, så att hantera minnesresurser är en viktig aspekt av att optimera körningen av Spark-jobb. Det finns flera tekniker som du kan använda för att använda klustrets minne effektivt.
Föredrar mindre datapartitioner och konto för datastorlek, typer och distribution i partitioneringsstrategin.
I Synapse Spark (Runtime 3.1 eller senare) aktiveras Kryo-data serialisering som standard för Kryo-data serialisering.
Du kan anpassa buffertstorleken för kryoserializer med hjälp av Spark-konfigurationen baserat på dina arbetsbelastningskrav:
// Set the desired property spark.conf.set("spark.kryoserializer.buffer.max", "256m")Övervaka och justera Spark-konfigurationsinställningar.
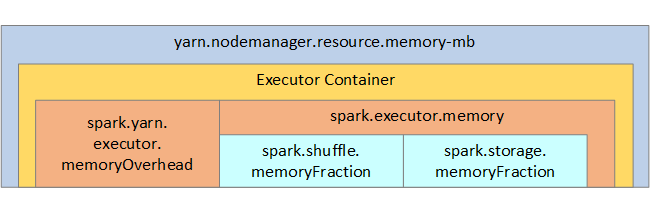
Som referens visas Spark-minnesstrukturen och några nyckelexekutorminnesparametrar i nästa bild.
Överväganden för Spark-minne
Apache Spark i Azure Synapse använder YARN Apache Hadoop YARN, YARN styr den maximala mängden minne som används av alla containrar på varje Spark-nod. Följande diagram visar nyckelobjekten och deras relationer.
Om du vill ta itu med meddelanden om "slut på minne" provar du:
- Granska DAG Management Shuffles. Minska genom att minska källdata på kartsidan, förpartitionera (eller bucketisera) källdata, maximera enskilda blandningar och minska mängden data som skickas.
- Föredrar
ReduceByKeymed sin fasta minnesgräns tillGroupByKey, vilket ger aggregeringar, fönster och andra funktioner, men den har en obegränsad minnesgräns. - Föredrar
TreeReduce, vilket gör mer arbete på exekutorer eller partitioner, tillReduce, som fungerar alla på drivrutinen. - Använd DataFrames i stället för RDD-objekt på lägre nivå.
- Skapa ComplexTypes som kapslar in åtgärder, till exempel "Top N", olika sammansättningar eller fönsteråtgärder.
Optimera dataserialiseringen
Spark-jobb distribueras, så lämplig data serialisering är viktigt för bästa prestanda. Det finns två serialiseringsalternativ för Spark:
- Java-serialisering
- Kryo-serialisering är standard. Det är ett nyare format och kan resultera i snabbare och mer kompakt serialisering än Java. Kryo kräver att du registrerar klasserna i ditt program, och det har ännu inte stöd för alla Serializable-typer.
Använd bucket
Bucketing liknar datapartitionering, men varje bucket kan innehålla en uppsättning kolumnvärden i stället för bara en. Bucketing fungerar bra för partitionering på stora (i miljoner eller fler) antal värden, till exempel produktidentifierare. En bucket bestäms genom att du hashar bucketnyckeln för raden. Bucketade tabeller erbjuder unika optimeringar eftersom de lagrar metadata om hur de bucketades och sorterades.
Några avancerade bucketningsfunktioner är:
- Frågeoptimering baserat på bucketing meta-information.
- Optimerade sammansättningar.
- Optimerade kopplingar.
Du kan använda partitionering och bucketing samtidigt.
Optimera kopplingar och blandningar
Om du har långsamma jobb på en koppling eller shuffle är orsaken förmodligen datasnedvridning, vilket är asymmetri i dina jobbdata. Ett kartjobb kan till exempel ta 20 sekunder, men det tar timmar att köra ett jobb där data kopplas till eller blandas. Om du vill åtgärda datasnedvridning bör du salta hela nyckeln eller använda ett isolerat salt för endast en delmängd nycklar. Om du använder ett isolerat salt bör du filtrera ytterligare för att isolera din delmängd av saltade nycklar i kartkopplingar. Ett annat alternativ är att introducera en bucketkolumn och föraggregera i bucketar först.
En annan faktor som orsakar långsamma kopplingar kan vara kopplingstypen. Som standard använder Spark kopplingstypen SortMerge . Den här typen av koppling passar bäst för stora datamängder, men är annars beräkningsmässigt dyr eftersom den först måste sortera vänster och höger sida av data innan de slås samman.
En Broadcast koppling passar bäst för mindre datamängder, eller där den ena sidan av kopplingen är mycket mindre än den andra sidan. Den här typen av koppling sänder en sida till alla utförare och kräver därför mer minne för sändningar i allmänhet.
Du kan ändra kopplingstypen i konfigurationen genom att ange spark.sql.autoBroadcastJoinThreshold, eller så kan du ange ett kopplingstips med hjälp av DataFrame-API:erna (dataframe.join(broadcast(df2))).
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
Om du använder bucketade tabeller har du en tredje kopplingstyp, Merge kopplingen. En korrekt förpartitionerad och försorterad datauppsättning hoppar över den dyra sorteringsfasen från en SortMerge koppling.
Ordningen på kopplingar är viktig, särskilt i mer komplexa frågor. Börja med de mest selektiva kopplingarna. Flytta kopplingar som ökar antalet rader efter aggregeringar när det är möjligt.
Om du vill hantera parallellitet för kartesiska kopplingar kan du lägga till kapslade strukturer, fönster och kanske hoppa över ett eller flera steg i ditt Spark-jobb.
Välj rätt körstorlek
När du bestämmer konfigurationen av din exekutor bör du tänka på kostnaderna för Java-skräpinsamling (GC).
Faktorer för att minska körstorleken:
- Minska heapstorleken under 32 GB för att hålla GC-omkostnaderna < 10 %.
- Minska antalet kärnor för att hålla GC-omkostnaderna < 10 %.
Faktorer för att öka körstorleken:
- Minska kommunikationskostnaderna mellan körarna.
- Minska antalet öppna anslutningar mellan utförare (N2) i större kluster (>100 köre).
- Öka heapstorleken för minnesintensiva uppgifter.
- Valfritt: Minska minneskostnaderna per exekutor.
- Valfritt: Öka användningen och samtidigheten genom att överprenumerera CPU.
Som en allmän tumregel när du väljer storlek på exekutor:
- Börja med 30 GB per köre och distribuera tillgängliga maskinkärnor.
- Öka antalet exekutorkärnor för större kluster (> 100 exekutorer).
- Ändra storlek baserat både på utvärderingskörningar och på föregående faktorer, till exempel GC-omkostnader.
Tänk på följande när du kör samtidiga frågor:
- Börja med 30 GB per köre och alla maskinkärnor.
- Skapa flera parallella Spark-program genom att överprenumerera CPU (cirka 30 % fördröjningsförbättring).
- Distribuera frågor mellan parallella program.
- Ändra storlek baserat både på utvärderingskörningar och på föregående faktorer, till exempel GC-omkostnader.
Övervaka frågeprestanda för extremvärden eller andra prestandaproblem genom att titta på tidslinjevyn, SQL-grafen, jobbstatistiken och så vidare. Ibland är en eller några av körarna långsammare än de andra, och aktiviteterna tar mycket längre tid att köra. Detta händer ofta i större kluster (> 30 noder). I det här fallet delar du upp arbetet i ett större antal aktiviteter så att schemaläggaren kan kompensera för långsamma aktiviteter.
Du kan till exempel ha minst dubbelt så många uppgifter som antalet körkärnor i programmet. Du kan också aktivera spekulativ körning av uppgifter med conf: spark.speculation = true.
Optimera jobbkörningen
- Cachelagrat efter behov, till exempel om du använder data två gånger och cachelagrat dem.
- Sända variabler till alla utförare. Variablerna serialiseras bara en gång, vilket resulterar i snabbare sökningar.
- Använd trådpoolen på drivrutinen, vilket resulterar i snabbare åtgärder för många uppgifter.
Nyckeln till Spark 2.x-frågeprestanda är tungstensmotorn, som är beroende av kodgenerering i hela fasen. I vissa fall kan kodgenereringen i hela fasen inaktiveras.
Om du till exempel använder en icke-föränderlig typ (string) i aggregeringsuttrycket SortAggregate visas i stället för HashAggregate. Om du till exempel vill ha bättre prestanda kan du prova följande och sedan återaktivera kodgenereringen:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))