Hantera bibliotek för Apache Spark-pooler i Azure Synapse Analytics
När du har identifierat De Scala-, Java-, R- (förhandsversion) eller Python-paket som du vill använda eller uppdatera för ditt Spark-program kan du installera eller ta bort dem från en Spark-pool. Bibliotek på poolnivå är tillgängliga för alla notebook-filer och jobb som körs i poolen.
Det finns två huvudsakliga sätt att installera ett bibliotek på en Spark-pool:
- Installera ett arbetsytebibliotek som har laddats upp som ett arbetsytepaket.
- Om du vill uppdatera Python-bibliotek tillhandahåller du en requirements.txt - eller Conda-environment.yml miljöspecifikationsfil för att installera paket från lagringsplatser som PyPI eller Conda-Forge. Mer information finns i avsnittet Miljöspecifikationsformat .
När ändringarna har sparats kör ett Spark-jobb installationen och cachelagrar den resulterande miljön för senare återanvändning. När jobbet är klart använder nya Spark-jobb eller notebook-sessioner de uppdaterade poolbiblioteken.
Viktigt!
- Om paketet du installerar är stort eller tar lång tid att installera påverkas starttiden för Spark-instansen.
- Det går inte att ändra versionen PySpark, Python, Scala/Java, .NET, R eller Spark.
- Installation av paket från externa lagringsplatser som PyPI, Conda-Forge eller standardkanalerna för Conda stöds inte i dataexfiltreringsskyddsaktiverade arbetsytor.
Hantera paket från Synapse Studio eller Azure Portal
Spark-poolbibliotek kan hanteras antingen från Synapse Studio eller Azure Portal.
I Azure Portal navigerar du till din Azure Synapse Analytics-arbetsyta.
I avsnittet Analyspooler väljer du fliken Apache Spark-pooler och väljer en Spark-pool i listan.
Välj paket i avsnittet Inställningar i Spark-poolen.
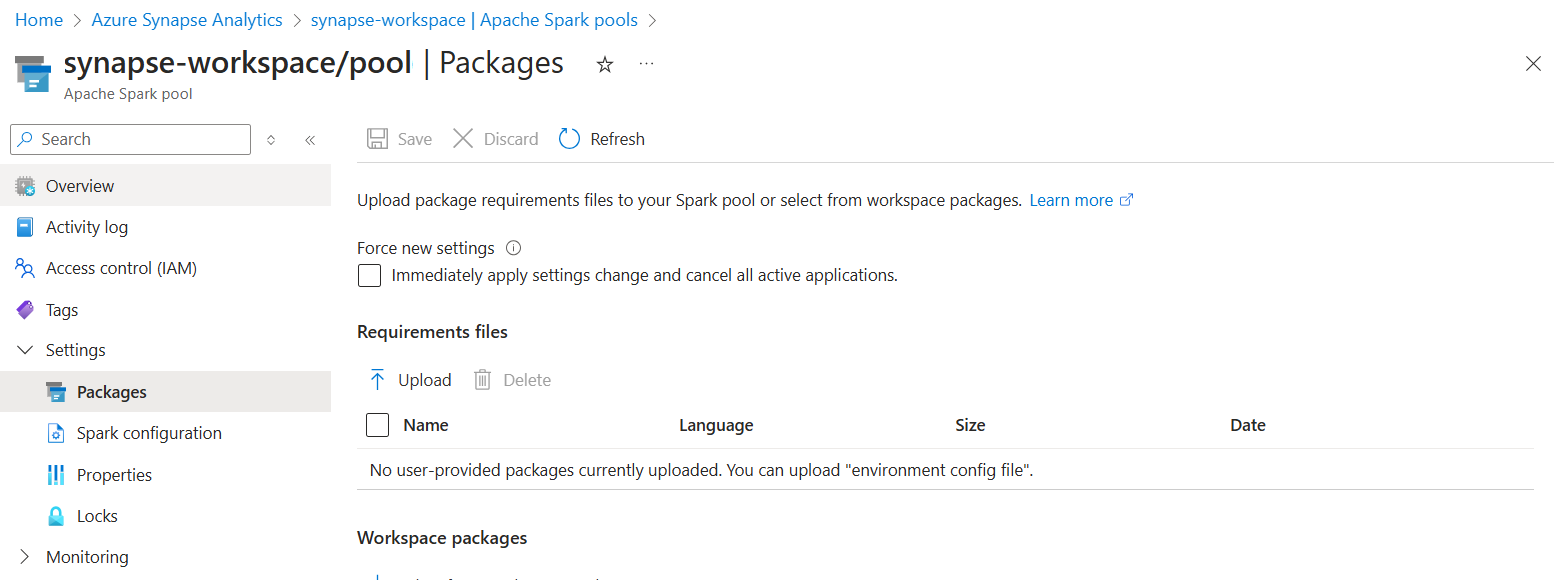
För Python-feedbibliotek laddar du upp miljökonfigurationsfilen med hjälp av filväljaren i avsnittet Paket på sidan.
Du kan också välja ytterligare arbetsytepaket för att lägga till Jar-, Wheel- eller Tar.gz-filer i poolen.
Du kan också ta bort inaktuella paket från avsnittet Arbetsytepaket och sedan bifogar din pool inte längre dessa paket.
När du har sparat ändringarna utlöses ett systemjobb för att installera och cachelagrat de angivna biblioteken. Den här processen hjälper till att minska den totala starttiden för sessioner.
När jobbet har slutförts hämtar alla nya sessioner de uppdaterade poolbiblioteken.


Viktigt!
Genom att välja alternativet Framtvinga nya inställningar avslutar du alla aktuella sessioner för den valda Spark-poolen. När sessionerna har avslutats måste du vänta tills poolen startas om.
Om den här inställningen är avmarkerad måste du vänta tills den aktuella Spark-sessionen avslutas eller stoppa den manuellt. När sessionen är slut måste du låta poolen startas om.
Spåra installationsförlopp
Ett systemreserverade Spark-jobb initieras varje gång en pool uppdateras med en ny uppsättning bibliotek. Med hjälp av det här Spark-jobbet kan du övervaka biblioteksinstallationens status. Om installationen misslyckas på grund av bibliotekskonflikter eller andra problem återgår Spark-poolen till sitt tidigare eller standardtillstånd.
Dessutom kan användarna granska installationsloggarna för att identifiera beroendekonflikter eller se vilka bibliotek som installerades under pooluppdateringen.
Så här visar du dessa loggar:
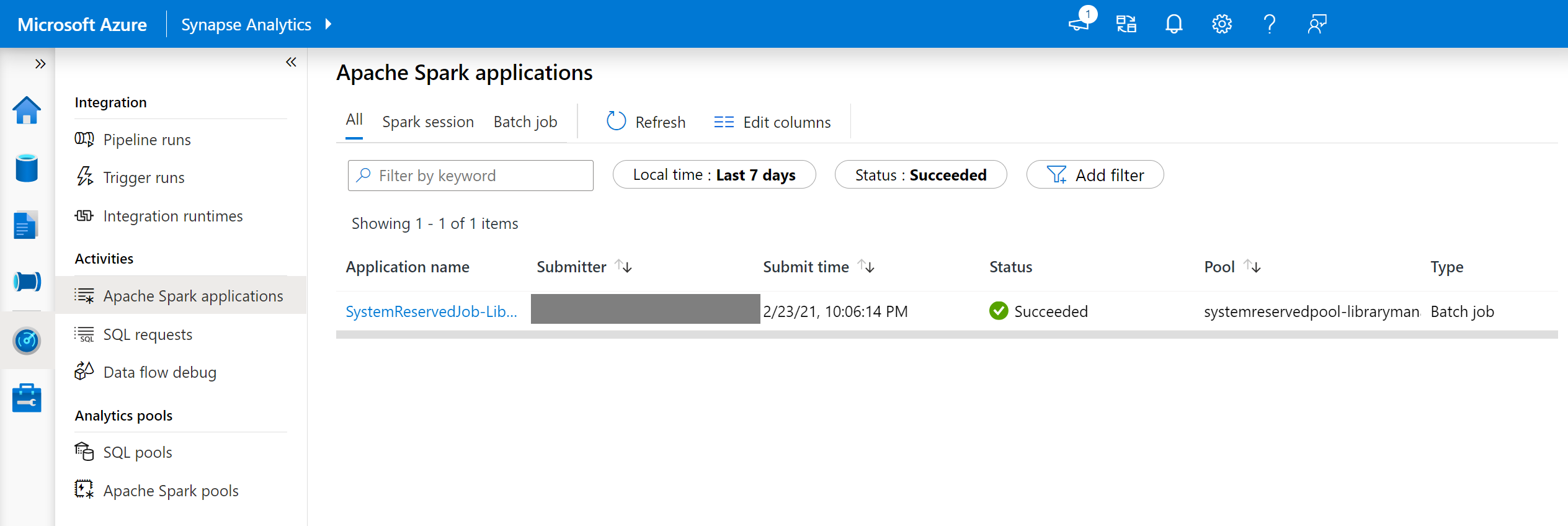
I Synapse Studio navigerar du till listan Med Spark-program på fliken Övervaka .
Välj det Spark-systemprogramjobb som motsvarar din pooluppdatering. Dessa systemjobb körs under namnet SystemReservedJob-LibraryManagement.
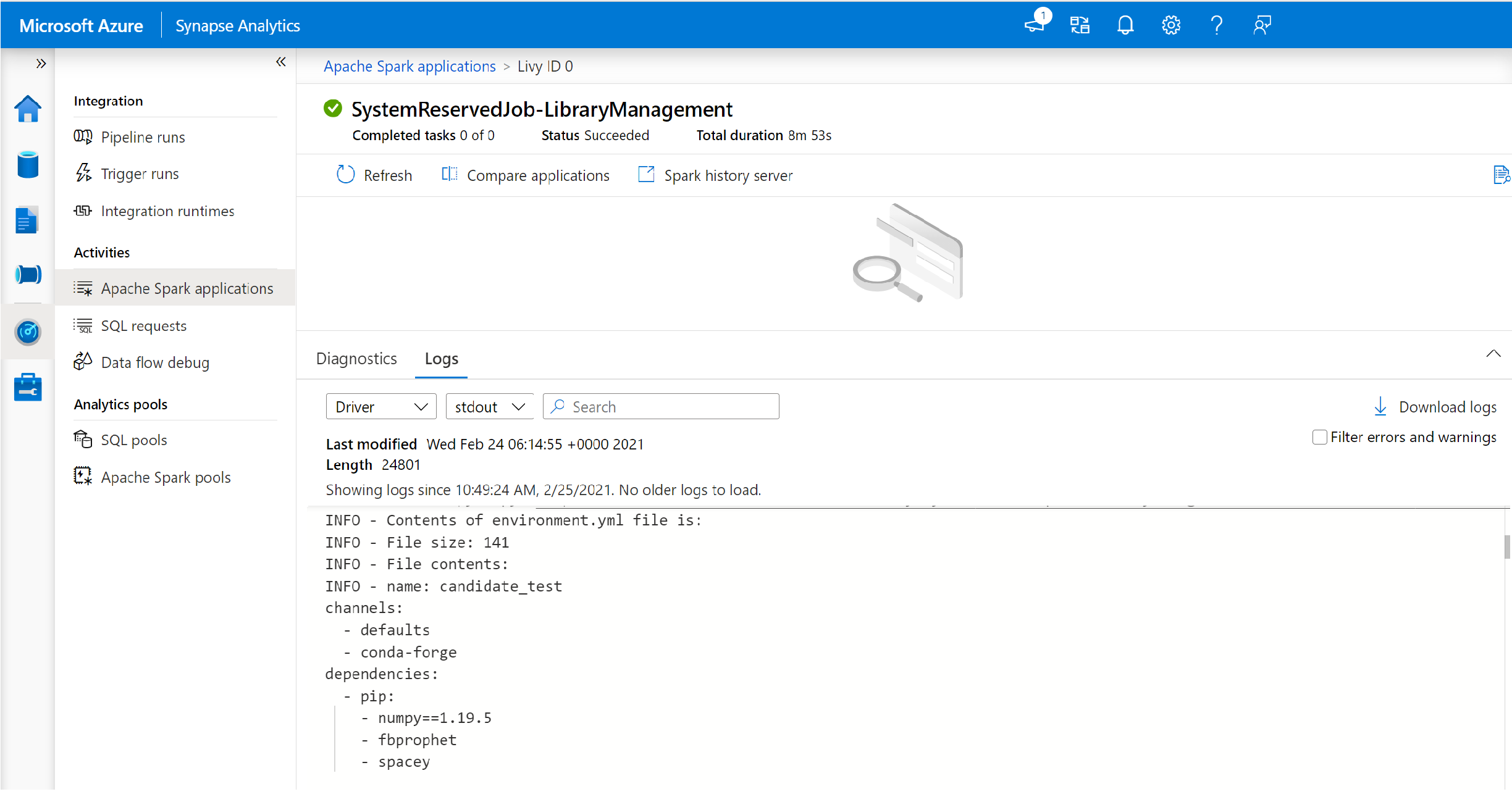
Växla för att visa drivrutins- och stdout-loggarna.
Resultatet innehåller loggarna som är relaterade till installationen av dina beroenden.


Format för miljöspecifikation
PIP-requirements.txt
En requirements.txt fil (utdata från pip freeze kommandot) kan användas för att uppgradera miljön. När en pool uppdateras laddas paketen som anges i den här filen ned från PyPI. De fullständiga beroendena cachelagras sedan och sparas för senare återanvändning av poolen.
Följande kodfragment visar formatet för kravfilen. PyPI-paketnamnet visas tillsammans med en exakt version. Den här filen följer det format som beskrivs i referensdokumentationen för pip freeze .
Det här exemplet fäster en specifik version.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
YML-format
Dessutom kan du ange en environment.yml fil för att uppdatera poolmiljön. Paketen som anges i den här filen laddas ned från conda-standardkanalerna Conda-Forge och PyPI. Du kan ange andra kanaler eller ta bort standardkanalerna med hjälp av konfigurationsalternativen.
Det här exemplet anger kanaler och Conda/PyPI-beroenden.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Mer information om hur du skapar en miljö från den här environment.yml filen finns i Aktivera en miljö.