Analysera data med Apache Spark
I den här självstudien får du lära dig hur du utför undersökande dataanalys med hjälp av Azure Open Datasets och Apache Spark. Du kan sedan visualisera resultatet i en Synapse Studio notebook-fil i Azure Synapse Analytics.
I synnerhet analyserar vi datamängden New York City (NYC) Taxi . Data är tillgängliga via Azure Open Datasets. Den här delmängden av datamängden innehåller information om gula taxiresor: information om varje resa, start- och sluttid och platser, kostnaden och andra intressanta attribut.
Innan du börjar
Skapa en Apache Spark-pool genom att följa självstudien Skapa en Apache Spark-pool.
Ladda ned och förbereda data
Skapa en notebook-fil med hjälp av PySpark-kerneln. Anvisningar finns i Skapa en anteckningsbok.
Anteckning
På grund av PySpark-kerneln behöver du inte skapa några kontexter explicit. Spark-kontexten skapas automatiskt åt dig när du kör den första kodcellen.
I den här självstudien använder vi flera olika bibliotek för att visualisera datauppsättningen. Om du vill göra den här analysen importerar du följande bibliotek:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdEftersom rådata är i Parquet-format kan du använda Spark-kontexten för att hämta filen till minnet som en DataFrame direkt. Skapa en Spark DataFrame genom att hämta data via API:et Open Datasets. Här använder vi Spark DataFrame-schemat för läsegenskaper för att härleda datatyper och scheman.
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())När data har lästs vill vi göra en inledande filtrering för att rensa datauppsättningen. Vi kan ta bort onödiga kolumner och lägga till kolumner som extraherar viktig information. Dessutom filtrerar vi bort avvikelser i datauppsättningen.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analysera data
Som dataanalytiker har du ett brett utbud av verktyg som hjälper dig att extrahera insikter från data. I den här delen av självstudien går vi igenom några användbara verktyg i Azure Synapse Analytics-notebook-filer. I den här analysen vill vi förstå de faktorer som ger högre taxitips för vår valda period.
Apache Spark SQL Magic
Först utför vi undersökande dataanalys av Apache Spark SQL och magiska kommandon med Azure Synapse notebook-fil. När vi har vår fråga visualiserar vi resultatet med hjälp av den inbyggda chart options funktionen.
Skapa en ny cell i anteckningsboken och kopiera följande kod. Med den här frågan vill vi förstå hur de genomsnittliga tipsbeloppen har ändrats under den period vi har valt. Den här frågan hjälper oss också att identifiera andra användbara insikter, inklusive minsta/högsta tipsbelopp per dag och genomsnittligt prisbelopp.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCNär frågan har körts kan vi visualisera resultatet genom att växla till diagramvyn. Det här exemplet skapar ett linjediagram genom att
day_of_monthange fältet som nyckel ochavgTipAmountsom värde. När du har gjort valen väljer du Använd för att uppdatera diagrammet.
Visualisera data
Förutom de inbyggda diagramalternativen för notebook-filer kan du använda populära bibliotek med öppen källkod för att skapa egna visualiseringar. I följande exempel använder vi Seaborn och Matplotlib. Dessa är vanliga Python-bibliotek för datavisualisering.
Anteckning
Som standard innehåller varje Apache Spark-pool i Azure Synapse Analytics en uppsättning vanliga bibliotek och standardbibliotek. Du kan visa den fullständiga listan över bibliotek i Azure Synapse-körningsdokumentationen. Om du vill göra kod från tredje part eller lokalt byggd tillgänglig för dina program kan du dessutom installera ett bibliotek på en av dina Spark-pooler.
För att göra utvecklingen enklare och billigare minskar vi datamängden. Vi använder den inbyggda Apache Spark-samplingsfunktionen. Dessutom kräver både Seaborn och Matplotlib en Pandas DataFrame- eller NumPy-matris. Om du vill hämta en Pandas DataFrame använder du
toPandas()kommandot för att konvertera DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Vi vill förstå fördelningen av tips i vår datauppsättning. Vi använder Matplotlib för att skapa ett histogram som visar fördelningen av tipsmängd och antal. Baserat på fördelningen kan vi se att tipsen är skeva mot belopp som är mindre än eller lika med 10 USD.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()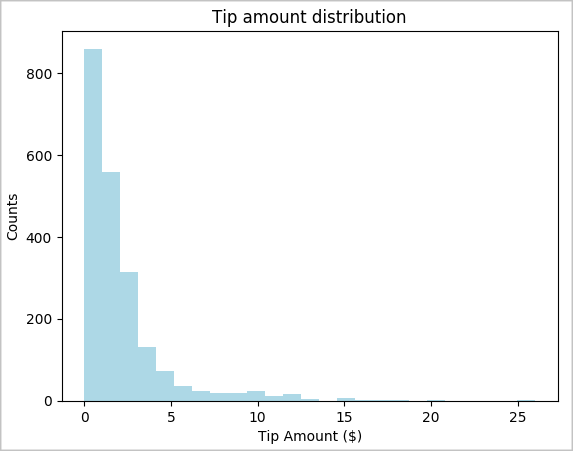
Sedan vill vi förstå relationen mellan tipsen för en viss resa och veckodagen. Använd Seaborn för att skapa ett låddiagram som sammanfattar trenderna för varje dag i veckan.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()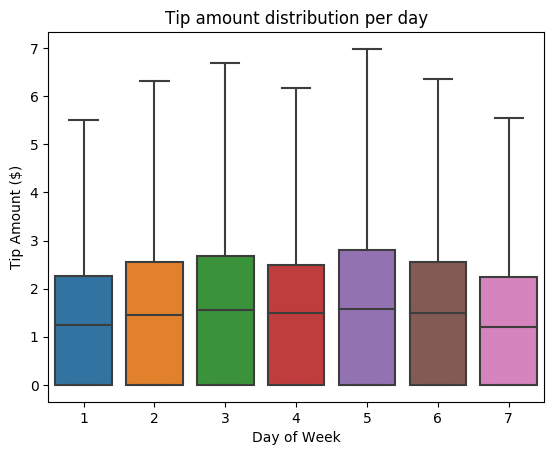
En annan hypotes hos oss kan vara att det finns ett positivt förhållande mellan antalet passagerare och den totala taxitipsmängden. Kontrollera den här relationen genom att köra följande kod för att generera ett låddiagram som illustrerar fördelningen av tips för varje antal passagerare.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()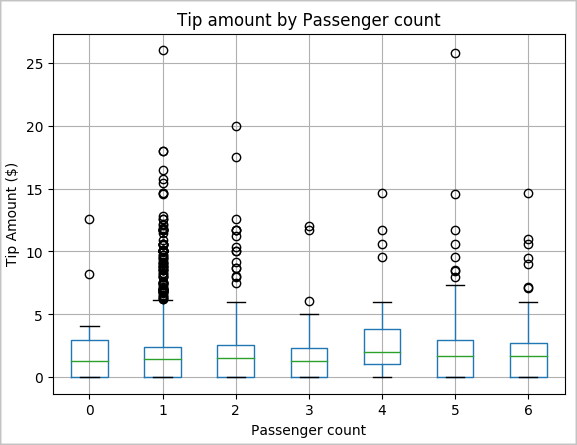
Slutligen vill vi förstå förhållandet mellan biljettpriset och tipsbeloppet. Baserat på resultaten kan vi se att det finns flera observationer där personer inte tipsar. Men vi ser också ett positivt samband mellan det totala priset och dricksbeloppen.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()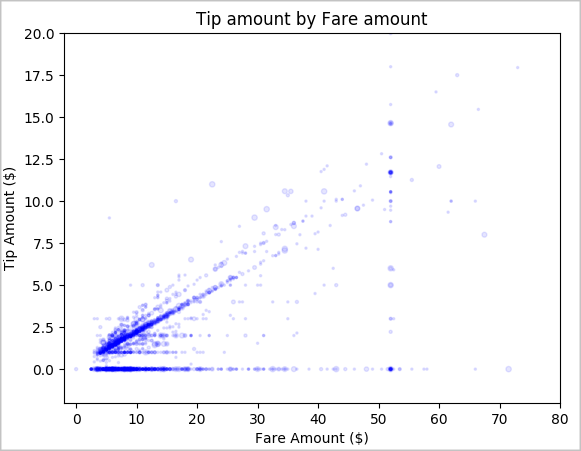
Stäng av Spark-instansen
När du har kört programmet stänger du av anteckningsboken för att frigöra resurserna. Stäng antingen fliken eller välj Avsluta session från statuspanelen längst ned i anteckningsboken.
Se även
- Översikt: Apache Spark på Azure Synapse Analytics
- Skapa en maskininlärningsmodell med Apache SparkML