Snabbstart: Transformera data med apache Spark-jobbdefinition
I den här snabbstarten använder du Azure Synapse Analytics för att skapa en pipeline med hjälp av Apache Spark-jobbdefinition.
Förutsättningar
- Azure-prenumeration: Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt Azure-konto innan du börjar.
- Azure Synapse-arbetsyta: Skapa en Synapse-arbetsyta med hjälp av Azure Portal enligt anvisningarna i Snabbstart: Skapa en Synapse-arbetsyta.
- Apache Spark-jobbdefinition: Skapa en Apache Spark-jobbdefinition på Synapse-arbetsytan enligt anvisningarna i Självstudie: Skapa Apache Spark-jobbdefinition i Synapse Studio.
Navigera till Synapse Studio
När din Azure Synapse-arbetsyta har skapats kan du öppna Synapse Studio på två sätt:
- Öppna Synapse-arbetsytan i Azure Portal. Välj Öppna på kortet Öppna Synapse Studio under Komma igång.
- Öppna Azure Synapse Analytics och logga in på din arbetsyta.
I den här snabbstarten använder vi arbetsytan med namnet "sampletest" som exempel.
Skapa en pipeline med en Apache Spark-jobbdefinition
En pipeline innehåller det logiska flödet för en körning av en uppsättning aktiviteter. I det här avsnittet skapar du en pipeline som innehåller en Apache Spark-jobbdefinitionsaktivitet.
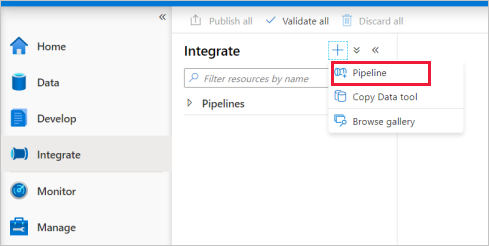
Gå till fliken Integrera . Välj plusikonen bredvid pipelinehuvudet och välj Pipeline.
På sidan Egenskaper inställningar i pipelinen anger du demo för Namn.
Under Synapse i fönstret Aktiviteter drar du Spark-jobbdefinitionen till pipelinearbetsytan.
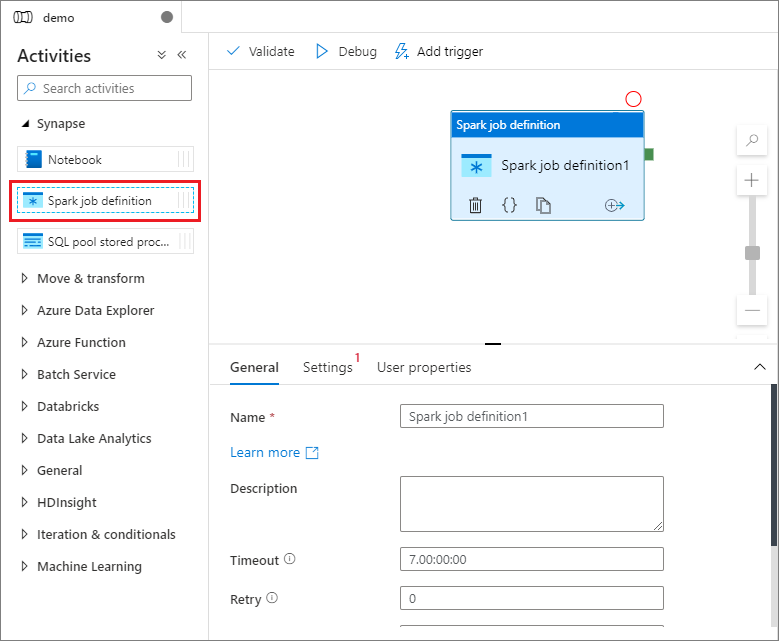
Ange Arbetsyta för Apache Spark-jobbdefinition
När du har skapat apache Spark-jobbdefinitionen skickas du automatiskt till Arbetsytan för Spark-jobbdefinition.
Allmänna inställningar
Välj modulen för spark-jobbdefinition på arbetsytan.
På fliken Allmänt anger du exempel för Namn.
(Alternativ) Du kan också ange en beskrivning.
Tidsgräns: Maximal tid som en aktivitet kan köras. Standardvärdet är sju dagar, vilket också är den maximala tillåtna tiden. Formatet finns i D.HH:MM:SS.
Försök igen: Maximalt antal återförsök.
Återförsöksintervall: Antalet sekunder mellan varje återförsök.
Säkra utdata: När den är markerad registreras inte utdata från aktiviteten i loggningen.
Säkra indata: När den är markerad registreras inte indata från aktiviteten i loggningen.
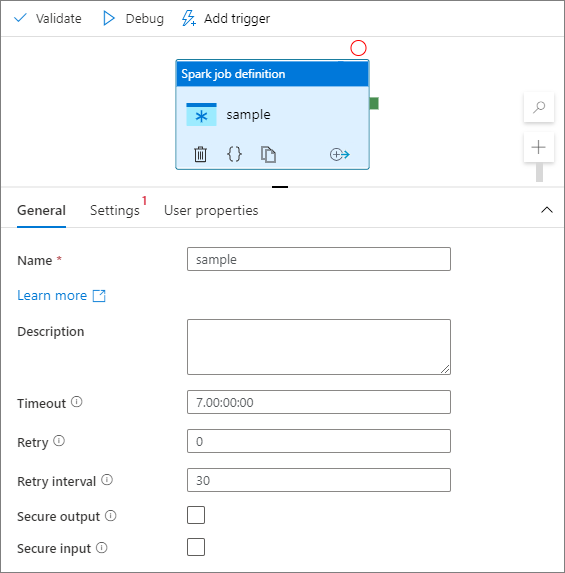
Fliken Inställningar
I den här panelen kan du referera till Spark-jobbdefinitionen som ska köras.
Expandera listan med Spark-jobbdefinitioner. Du kan välja en befintlig Apache Spark-jobbdefinition. Du kan också skapa en ny Apache Spark-jobbdefinition genom att välja knappen Ny för att referera till Spark-jobbdefinitionen som ska köras.
(Valfritt) Du kan fylla i information för Apache Spark-jobbdefinitionen. Om följande inställningar är tomma används inställningarna för själva spark-jobbdefinitionen för att köras. Om följande inställningar inte är tomma ersätter dessa inställningar inställningarna för själva spark-jobbdefinitionen.
Property beskrivning Huvuddefinitionsfil Huvudfilen som används för jobbet. Välj en PY/JAR/ZIP-fil från lagringen. Du kan välja Ladda upp fil för att ladda upp filen till ett lagringskonto.
Exempel:abfss://…/path/to/wordcount.jarReferenser från undermappar Genom att skanna undermappar från rotmappen i huvuddefinitionsfilen läggs dessa filer till som referensfiler. Mapparna med namnet "jars", "pyFiles", "files" eller "archives" genomsöks och mappnamnet är skiftlägeskänsligt. Huvudklassnamn Den fullständigt kvalificerade identifieraren eller huvudklassen som finns i huvuddefinitionsfilen.
Exempel:WordCountKommandoradsargument Du kan lägga till kommandoradsargument genom att klicka på knappen Nytt . Observera att tillägg av kommandoradsargument åsidosätter de kommandoradsargument som definieras av Spark-jobbdefinitionen.
Prov:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultApache Spark-pool Du kan välja Apache Spark-pool i listan. Python-kodreferens Andra Python-kodfiler som används som referens i huvuddefinitionsfilen.
Den stöder överföring av filer (.py, .py3, .zip) till egenskapen "pyFiles". Den åsidosätter egenskapen "pyFiles" som definierats i Spark-jobbdefinitionen.Referensfiler Andra filer som används som referens i huvuddefinitionsfilen. Dynamiskt allokera köre Den här inställningen mappar till den dynamiska allokeringsegenskapen i Spark-konfigurationen för Spark Application Executors-allokering. Minsta körbara filer Minsta antal utförare som ska allokeras i den angivna Spark-poolen för jobbet. Maximalt antal körbara filer Maximalt antal utförare som ska allokeras i den angivna Spark-poolen för jobbet. Drivrutinsstorlek Antal kärnor och minne som ska användas för drivrutinen som anges i den angivna Apache Spark-poolen för jobbet. Apache Spark-konfiguration Ange värden för Spark-konfigurationsegenskaper som anges i artikeln: Spark-konfiguration – Programegenskaper. Användare kan använda standardkonfiguration och anpassad konfiguration. 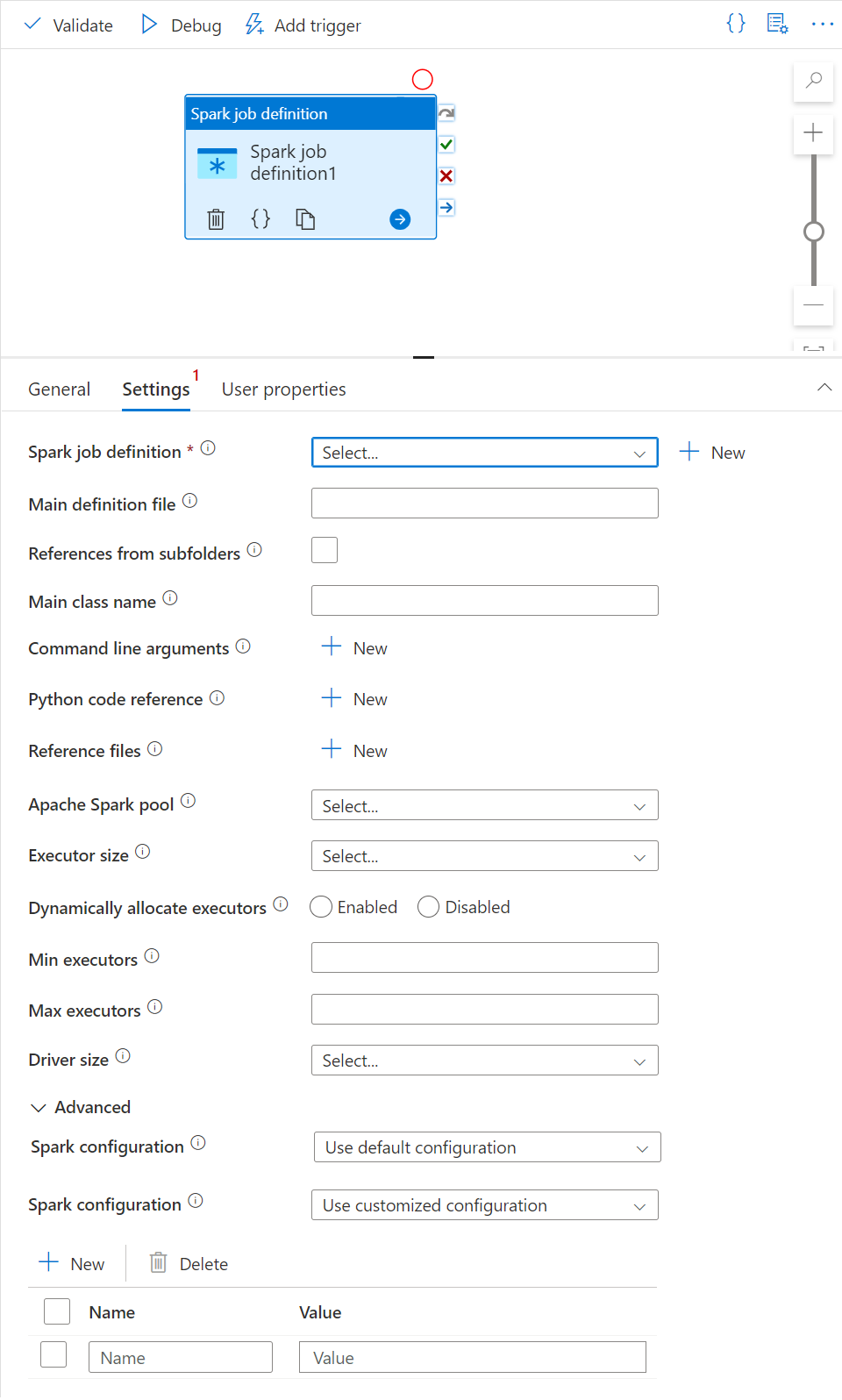
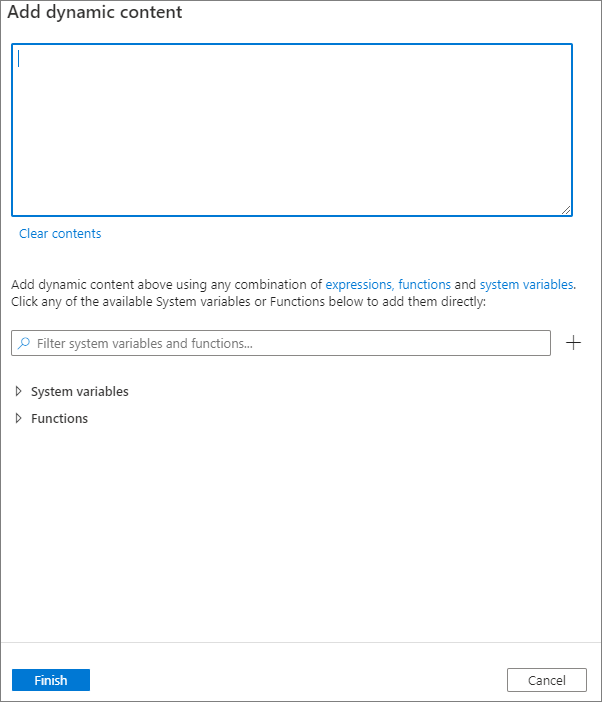
Du kan lägga till dynamiskt innehåll genom att klicka på knappen Lägg till dynamiskt innehåll eller genom att trycka på kortkommandot Alt+Shift+D. På sidan Lägg till dynamiskt innehåll kan du använda valfri kombination av uttryck, funktioner och systemvariabler för att lägga till dynamiskt innehåll.
Fliken Användaregenskaper
Du kan lägga till egenskaper för Apache Spark-jobbdefinitionsaktivitet i den här panelen.

Relaterat innehåll
Gå vidare till följande artiklar för att lära dig mer om Azure Synapse Analytics-stöd: