Utöver Teradata-migrering implementerar du ett modernt informationslager i Microsoft Azure
Den här artikeln är del sju i en serie i sju delar som ger vägledning om hur du migrerar från Teradata till Azure Synapse Analytics. Fokus i den här artikeln är metodtips för att implementera moderna informationslager.
Utöver migrering av informationslager till Azure
En viktig orsak till att migrera ditt befintliga informationslager till Azure Synapse Analytics är att använda en globalt säker, skalbar analysdatabas med låg kostnad och molnbaserad analysdatabas som du betalar per användning. Med Azure Synapse kan du integrera ditt migrerade informationslager med hela Microsoft Azure-analysekosystemet för att dra nytta av andra Microsoft-tekniker och modernisera ditt migrerade informationslager. Dessa tekniker omfattar:
Azure Data Lake Storage för kostnadseffektiv datainmatning, mellanlagring, rensning och transformering. Data Lake Storage kan frigöra den informationslagerkapacitet som upptas av snabbväxande mellanlagringstabeller.
Azure Data Factory för samarbete mellan IT och självbetjäningsdataintegrering med anslutningsappar till molnbaserade och lokala datakällor och strömmande data.
Common Data Model för att dela konsekventa betrodda data över flera tekniker, inklusive:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- Azure IoT
- Microsoft ISV-partner
Microsofts datavetenskapstekniker, inklusive:
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (Spark som en tjänst)
- Jupyter Notebook
- RStudio
- ML.NET
- .NET för Apache Spark, som låter dataexperter använda Azure Synapse-data för att träna maskininlärningsmodeller i stor skala.
Azure HDInsight för att bearbeta stora mängder data och för att koppla stordata till Azure Synapse-data genom att skapa ett logiskt informationslager med polybase.
Azure Event Hubs, Azure Stream Analytics och Apache Kafka för att integrera liveuppspelningsdata från Azure Synapse.
Tillväxten av stordata har lett till en akut efterfrågan på maskininlärning för att möjliggöra specialbyggda, tränade maskininlärningsmodeller för användning i Azure Synapse. Maskininlärningsmodeller gör det möjligt för analys i databasen att köras i stor skala i batch, på händelsedriven basis och på begäran. Möjligheten att dra nytta av databasanalys i Azure Synapse från flera BI-verktyg och program garanterar även konsekventa förutsägelser och rekommendationer.
Dessutom kan du integrera Azure Synapse med Microsoft-partnerverktyg i Azure för att korta ned tiden till värdet.
Låt oss ta en närmare titt på hur du kan dra nytta av tekniker i Microsofts analytiska ekosystem för att modernisera ditt informationslager när du har migrerat till Azure Synapse.
Avlasta datalagring och ETL-bearbetning till Data Lake Storage och Data Factory
Digital omvandling har skapat en viktig utmaning för företag genom att generera en ström av nya data för insamling och analys. Ett bra exempel är transaktionsdata som skapats genom att öppna OLTP-system (online transactional processing) för tjänståtkomst från mobila enheter. Mycket av dessa data hittar sin väg in i informationslager, och OLTP-system är huvudkällan. Med kunder som nu driver transaktionsfrekvensen snarare än anställda har mängden data i mellanlagringstabeller för informationslager ökat snabbt.
Med den snabba tillströmningen av data till företaget, tillsammans med nya datakällor som Sakernas Internet (IoT), måste företag hitta sätt att skala upp ETL-bearbetning av dataintegrering. En metod är att avlasta inmatning, datarensning, transformering och integrering till en datasjö och bearbeta data i stor skala där, som en del av ett moderniseringsprogram för informationslager.
När du har migrerat ditt informationslager till Azure Synapse kan Microsoft modernisera ETL-bearbetningen genom att mata in och mellanlagra data i Data Lake Storage. Du kan sedan rensa, transformera och integrera dina data i stor skala med hjälp av Data Factory innan du läser in dem parallellt i Azure Synapse med hjälp av PolyBase.
För ELT-strategier bör du överväga att avlasta ELT-bearbetningen till Data Lake Storage för att enkelt skala när din datavolym eller frekvens växer.
Microsoft Azure Data Factory
Azure Data Factory är en tjänst för att betala per användning och hybriddataintegrering för mycket skalbar ETL- och ELT-bearbetning. Data Factory tillhandahåller ett webbaserat användargränssnitt för att skapa dataintegreringspipelines utan kod. Med Data Factory kan du:
Skapa skalbara dataintegreringspipelines utan kod.
Hämta enkelt data i stor skala.
Du betalar bara för det du använder.
Anslut till lokala, molnbaserade och SaaS-baserade datakällor.
Mata in, flytta, rensa, transformera, integrera och analysera molndata och lokala data i stor skala.
Skapa, övervaka och hantera pipelines som omfattar datalager både lokalt och i molnet.
Aktivera utskalning med användningsbaserad betalning i linje med kundtillväxten.
Du kan använda dessa funktioner utan att skriva någon kod eller lägga till anpassad kod i Data Factory-pipelines. Följande skärmbild visar ett exempel på en Data Factory-pipeline.

Dricks
Med Data Factory kan du skapa skalbara dataintegreringspipelines utan kod.
Implementera Data Factory-pipelineutveckling från någon av flera platser, inklusive:
Microsoft Azure Portal.
Microsoft Azure PowerShell.
Programmatiskt från .NET och Python med hjälp av ett SDK med flera språk.
Arm-mallar (Azure Resource Manager).
REST-API:er.
Dricks
Data Factory kan ansluta till lokala data, molndata och SaaS-data.
Utvecklare och dataexperter som föredrar att skriva kod kan enkelt skapa Data Factory-pipelines i Java, Python och .NET med hjälp av de programutvecklingspaket (SDK:er) som är tillgängliga för dessa programmeringsspråk. Data Factory-pipelines kan vara hybriddatapipelines eftersom de kan ansluta, mata in, rensa, transformera och analysera data i lokala datacenter, Microsoft Azure, andra moln och SaaS-erbjudanden.
När du har utvecklat Data Factory-pipelines för att integrera och analysera data kan du distribuera dessa pipelines globalt och schemalägga dem att köras i batch, anropa dem på begäran som en tjänst eller köra dem i realtid på händelsedriven basis. En Data Factory-pipeline kan också köras på en eller flera körningsmotorer och övervaka körningen för att säkerställa prestanda och spåra fel.
Dricks
I Azure Data Factory styr pipelines integreringen och analysen av data. Data Factory är en dataintegreringsprogramvara i företagsklass som riktar sig till IT-proffs och har dataomvandlingsfunktioner för företagsanvändare.
Användningsfall
Data Factory stöder flera användningsfall, till exempel:
Förbereda, integrera och berika data från molnbaserade och lokala datakällor för att fylla i ditt migrerade informationslager och data marts på Microsoft Azure Synapse.
Förbereda, integrera och berika data från molnbaserade och lokala datakällor för att producera träningsdata för användning i utveckling av maskininlärningsmodeller och i omträning av analysmodeller.
Samordna dataförberedelse och analys för att skapa prediktiva och normativa analyspipelines för bearbetning och analys av data i batch, till exempel attitydanalys. Agera antingen på resultatet av analysen eller fyll i informationslagret med resultatet.
Förbereda, integrera och berika data för datadrivna affärsprogram som körs i Azure-molnet ovanpå driftdatalager som Azure Cosmos DB.
Dricks
Skapa träningsdatauppsättningar inom datavetenskap för att utveckla maskininlärningsmodeller.
Datakällor
Med Data Factory kan du använda anslutningsappar från både molnbaserade och lokala datakällor. Agentprogramvara, som kallas en lokalt installerad integrationskörning, har säker åtkomst till lokala datakällor och stöder säker och skalbar dataöverföring.
Transformera data med Hjälp av Azure Data Factory
I en Data Factory-pipeline kan du mata in, rensa, transformera, integrera och analysera alla typer av data från dessa källor. Data kan vara strukturerade, halvstrukturerade som JSON eller Avro eller ostrukturerade.
Utan att skriva någon kod kan professionella ETL-utvecklare använda Data Factory-mappningsdataflöden för att filtrera, dela, ansluta flera typer, sökning, pivot, unpivot, sortera, union och aggregera data. Dessutom stöder Data Factory surrogatnycklar, flera alternativ för skrivbearbetning som insert, upsert, update, table recreation och table truncation och flera typer av måldatalager, även kallade mottagare. ETL-utvecklare kan också skapa aggregeringar, inklusive tidsserieaggregeringar som kräver att ett fönster placeras på datakolumner.
Dricks
Professionella ETL-utvecklare kan använda Data Factory-mappningsdataflöden för att rensa, transformera och integrera data utan att behöva skriva kod.
Du kan köra mappning av dataflöden som transformerar data som aktiviteter i en Data Factory-pipeline, och om det behövs kan du inkludera flera mappningsdataflöden i en enda pipeline. På så sätt kan du hantera komplexiteten genom att dela upp utmanande datatransformerings- och integreringsuppgifter i mindre mappningsdataflöden som kan kombineras. Och du kan lägga till anpassad kod när det behövs. Förutom den här funktionen inkluderar Data Factory-mappning av dataflöden möjligheten att:
Definiera uttryck för att rensa och transformera data, beräkningsaggregeringar och berika data. De här uttrycken kan till exempel utföra funktionsframställning i ett datumfält för att dela upp det i flera fält för att skapa träningsdata under utveckling av maskininlärningsmodeller. Du kan konstruera uttryck från en omfattande uppsättning funktioner som inkluderar matematisk, temporal, split, merge, string concatenation, conditions, pattern match, replace och många andra funktioner.
Hantera schemaavvikelser automatiskt så att datatransformeringspipelines kan undvika att påverkas av schemaändringar i datakällor. Den här möjligheten är särskilt viktig för direktuppspelning av IoT-data, där schemaändringar kan ske utan förvarning om enheter uppgraderas eller när avläsningar missas av gatewayenheter som samlar in IoT-data.
Partitionera data så att transformeringar kan köras parallellt i stor skala.
Granska strömmande data för att visa metadata för en ström som du transformerar.
Dricks
Data Factory stöder möjligheten att automatiskt identifiera och hantera schemaändringar i inkommande data, till exempel i strömmande data.
Följande skärmbild visar ett exempel på dataflödet för Data Factory-mappning.

Datatekniker kan profilera datakvaliteten och visa resultatet av enskilda datatransformeringar genom att aktivera felsökningsfunktionen under utvecklingen.
Dricks
Data Factory kan också partitionera data så att ETL-bearbetning kan köras i stor skala.
Om det behövs kan du utöka datafabrikens transformerings- och analysfunktioner genom att lägga till en länkad tjänst som innehåller din kod i en pipeline. Till exempel kan en Azure Synapse Spark-poolanteckningsbok innehålla Python-kod som använder en tränad modell för att bedöma data som är integrerade i ett mappningsdataflöde.
Du kan lagra integrerade data och eventuella resultat från analys i en Data Factory-pipeline i ett eller flera datalager, till exempel Data Lake Storage, Azure Synapse eller Hive-tabeller i HDInsight. Du kan också anropa andra aktiviteter för att agera på insikter som skapas av en Data Factory-analyspipeline.
Dricks
Data Factory-pipelines är utökningsbara eftersom Data Factory låter dig skriva din egen kod och köra den som en del av en pipeline.
Använda Spark för att skala dataintegrering
Vid körning använder Data Factory internt Azure Synapse Spark-pooler, som är Microsofts Spark som tjänsterbjudande, för att rensa och integrera data i Azure-molnet. Du kan rensa, integrera och analysera högvolymdata med hög hastighet, till exempel klickströmsdata i stor skala. Microsofts avsikt är att även köra Data Factory-pipelines på andra Spark-distributioner. Förutom att köra ETL-jobb på Spark kan Data Factory anropa Pig-skript och Hive-frågor för att komma åt och transformera data som lagras i HDInsight.
Länka dataförberedelser via självbetjäning och Data Factory ETL-bearbetning med hjälp av wrangling-dataflöden
Med dataomvandling kan företagsanvändare, även kallade medborgardataintegratörer och datatekniker, använda plattformen för att visuellt upptäcka, utforska och förbereda data i stor skala utan att skriva kod. Den här Data Factory-funktionen är enkel att använda och liknar Microsoft Excel Power Query eller Microsoft Power BI-dataflöden, där företagsanvändare med självbetjäning använder ett kalkylbladsformat med listrutetransformeringar för att förbereda och integrera data. Följande skärmbild visar ett exempel på dataflödet i Data Factory.

Till skillnad från Excel och Power BI använder Data Factory-dataflöden Power Query för att generera M-kod och översätter den sedan till ett massivt parallellt Spark-jobb i minnet för körning i molnskala. Kombinationen av att mappa dataflöden och omvandla dataflöden i Data Factory gör att professionella ETL-utvecklare och företagsanvändare kan samarbeta för att förbereda, integrera och analysera data för ett gemensamt affärssyfte. Det föregående dataflödesdiagrammet för Data Factory-mappning visar hur både Data Factory- och Azure Synapse Spark-poolanteckningsböcker kan kombineras i samma Data Factory-pipeline. Kombinationen av mappning och vridning av dataflöden i Data Factory hjälper IT- och företagsanvändare att hålla sig medvetna om vilka dataflöden var och en har skapat och stöder återanvändning av dataflöden för att minimera förnyelse och maximera produktiviteten och konsekvensen.
Dricks
Data Factory har stöd för både dataflöden och mappning av dataflöden, så att företagsanvändare och IT-användare kan integrera data i samarbete på en gemensam plattform.
Länka data och analys i analyspipelines
Förutom att rensa och transformera data kan Data Factory kombinera dataintegrering och analys i samma pipeline. Du kan använda Data Factory för att skapa både dataintegrerings- och analyspipelines, där det senare är en förlängning av den förra. Du kan släppa en analysmodell i en pipeline för att skapa en analyspipeline som genererar rena, integrerade data för förutsägelser eller rekommendationer. Sedan kan du agera på förutsägelserna eller rekommendationerna direkt, eller lagra dem i ditt informationslager för att ge nya insikter och rekommendationer som kan visas i BI-verktyg.
Om du vill batchvärdesätta dina data kan du utveckla en analysmodell som du anropar som en tjänst i en Data Factory-pipeline. Du kan utveckla analysmodeller utan kod med Azure Machine Learning-studio eller med Azure Machine Learning SDK med hjälp av Azure Synapse Spark-poolanteckningsböcker eller R i RStudio. När du kör Spark-maskininlärningspipelines i Azure Synapse Spark-poolanteckningsböcker sker analysen i stor skala.
Du kan lagra integrerade data och alla Data Factory-analyspipelines resulterar i ett eller flera datalager, till exempel Data Lake Storage, Azure Synapse eller Hive-tabeller i HDInsight. Du kan också anropa andra aktiviteter för att agera på insikter som skapas av en Data Factory-analyspipeline.
Använda en lake-databas för att dela konsekventa betrodda data
Ett viktigt mål för alla konfigurationer av dataintegrering är möjligheten att integrera data en gång och återanvända dem överallt, inte bara i ett informationslager. Du kanske till exempel vill använda integrerade data i data science. Återanvändning undviker förnyelse och säkerställer konsekventa, allmänt förstådda data som alla kan lita på.
Common Data Model beskriver viktiga dataentiteter som kan delas och återanvändas i hela företaget. För att uppnå återanvändning etablerar Common Data Model en uppsättning vanliga datanamn och definitioner som beskriver logiska dataentiteter. Exempel på vanliga datanamn är Kund, Konto, Produkt, Leverantör, Beställningar, Betalningar och Returer. IT- och företagsproffs kan använda dataintegreringsprogram för att skapa och lagra gemensamma datatillgångar för att maximera återanvändning och skapa konsekvens överallt.
Azure Synapse tillhandahåller branschspecifika databasmallar som hjälper dig att standardisera data i sjön. Lake-databasmallar tillhandahåller scheman för fördefinierade affärsområden, vilket gör att data kan läsas in i en sjödatabas på ett strukturerat sätt. Kraften kommer när du använder programvara för dataintegrering för att skapa vanliga datatillgångar i Lake Database, vilket resulterar i självbeskrivande betrodda data som kan användas av program och analyssystem. Du kan skapa vanliga datatillgångar i Data Lake Storage med hjälp av Data Factory.
Dricks
Data Lake Storage är delad lagring som ligger till grund för Microsoft Azure Synapse, Azure Machine Learning, Azure Synapse Spark och HDInsight.
Power BI, Azure Synapse Spark, Azure Synapse och Azure Machine Learning kan använda vanliga datatillgångar. Följande diagram visar hur en sjödatabas kan användas i Azure Synapse.
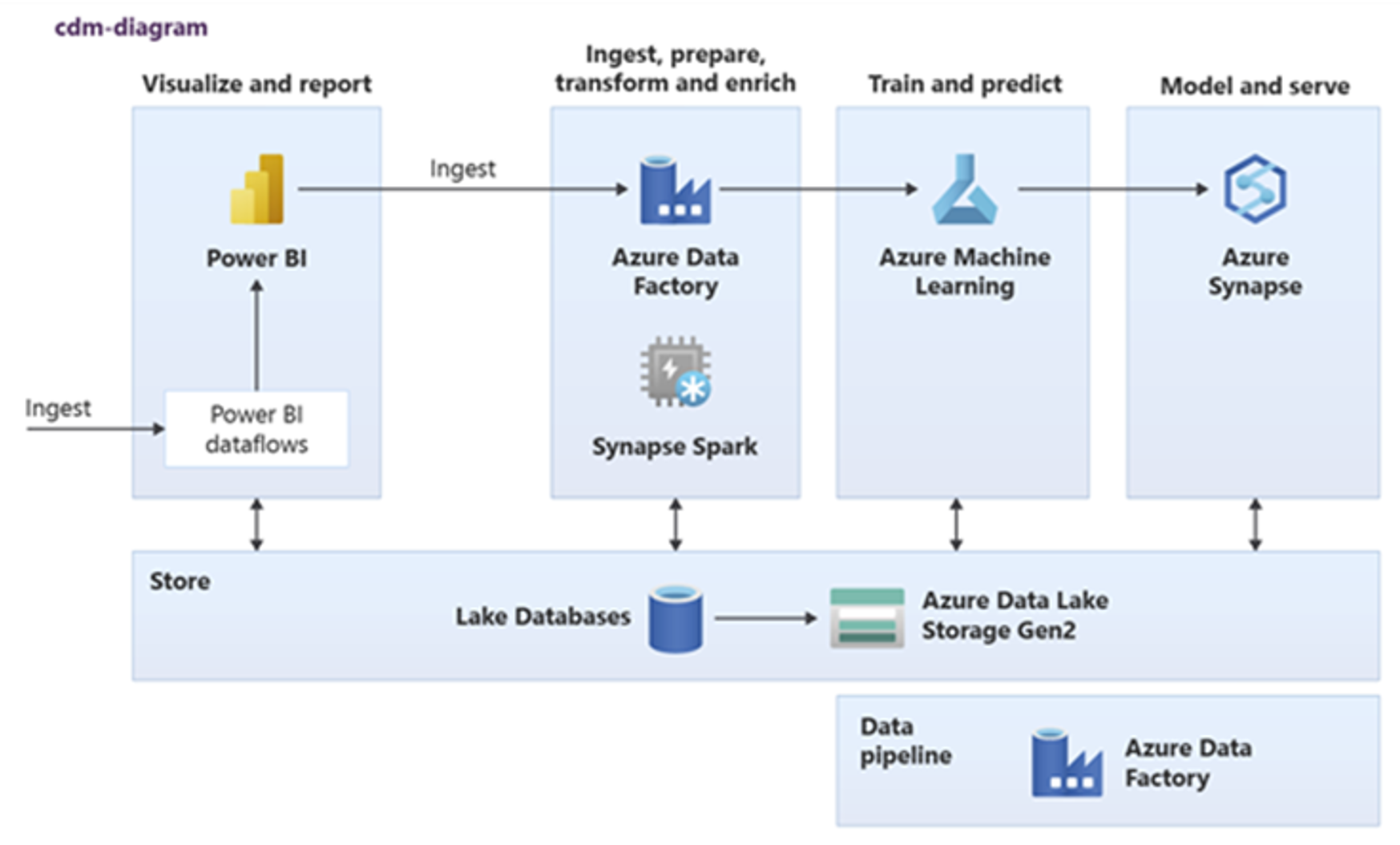
Dricks
Integrera data för att skapa logiska lakedatabasentiteter i delad lagring för att maximera återanvändningen av gemensamma datatillgångar.
Integrering med Microsofts datavetenskapstekniker i Azure
Ett annat viktigt mål när du moderniserar ett informationslager är att skapa insikter för konkurrensfördelar. Du kan skapa insikter genom att integrera ditt migrerade informationslager med Microsoft och datavetenskapstekniker från tredje part i Azure. I följande avsnitt beskrivs maskininlärnings- och datavetenskapsteknik som erbjuds av Microsoft för att se hur de kan användas med Azure Synapse i en modern informationslagermiljö.
Microsoft-tekniker för datavetenskap i Azure
Microsoft erbjuder en rad tekniker som stöder förhandsanalys. Med dessa tekniker kan du skapa förutsägelseanalysmodeller med hjälp av maskininlärning eller analysera ostrukturerade data med hjälp av djupinlärning. Teknikerna omfattar:
Azure Machine Learning Studio
Azure Machine Learning
Azure Synapse Spark-poolanteckningsböcker
ML.NET (API, CLI eller ML.NET Model Builder för Visual Studio)
.NET för Apache Spark
Dataexperter kan använda RStudio (R) och Jupyter Notebooks (Python) för att utveckla analysmodeller, eller använda ramverk som Keras eller TensorFlow.
Dricks
Utveckla maskininlärningsmodeller med hjälp av en no/low-code-metod eller med hjälp av programmeringsspråk som Python, R och .NET.
Azure Machine Learning Studio
Azure Machine Learning-studio är en fullständigt hanterad molntjänst som gör att du kan skapa, distribuera och dela förutsägelseanalyser med hjälp av ett dra och släpp-webbaserat användargränssnitt. Följande skärmbild visar användargränssnittet för Azure Machine Learning-studio.

Azure Machine Learning
Azure Machine Learning tillhandahåller en SDK och tjänster för Python som stöder kan hjälpa dig att snabbt förbereda data och även träna och distribuera maskininlärningsmodeller. Du kan använda Azure Machine Learning i Azure Notebooks med Hjälp av Jupyter Notebook, med ramverk med öppen källkod, till exempel PyTorch, TensorFlow, scikit-learn eller Spark MLlib – maskininlärningsbiblioteket för Spark.
Dricks
Azure Machine Learning tillhandahåller en SDK för utveckling av maskininlärningsmodeller med flera ramverk med öppen källkod.
Du kan också använda Azure Machine Learning för att skapa maskininlärningspipelines som hanterar arbetsflöden från slutpunkt till slutpunkt, skala programmatiskt i molnet och distribuera modeller både till molnet och gränsen. Azure Machine Learning innehåller arbetsytor, som är logiska utrymmen som du kan skapa programmatiskt eller manuellt i Azure Portal. Dessa arbetsytor håller beräkningsmål, experiment, datalager, tränade maskininlärningsmodeller, Docker-avbildningar och distribuerade tjänster på ett och samma ställe så att teamen kan arbeta tillsammans. Du kan använda Azure Machine Learning i Visual Studio med Visual Studio for AI-tillägget.
Dricks
Organisera och hantera relaterade datalager, experiment, tränade modeller, Docker-avbildningar och distribuerade tjänster på arbetsytor.
Azure Synapse Spark-poolanteckningsböcker
En Azure Synapse Spark-poolanteckningsbok är en Azure-optimerad Apache Spark-tjänst. Med Azure Synapse Spark-poolanteckningsböcker:
Datatekniker kan skapa och köra skalbara dataförberedelsejobb med hjälp av Data Factory.
Dataexperter kan skapa och köra maskininlärningsmodeller i stor skala med notebook-filer skrivna på språk som Scala, R, Python, Java och SQL för att visualisera resultat.
Dricks
Azure Synapse Spark är en dynamiskt skalbar Spark som ett tjänsterbjudande från Microsoft, Spark erbjuder skalbar körning av förberedelse av data, modellutveckling och distribuerad modellkörning.
Jobb som körs i Azure Synapse Spark-poolanteckningsböcker kan hämta, bearbeta och analysera data i stor skala från Azure Blob Storage, Data Lake Storage, Azure Synapse, HDInsight och strömmande datatjänster som Apache Kafka.
Dricks
Azure Synapse Spark kan komma åt data i en rad microsoft-analytiska ekosystemdatalager i Azure.
Azure Synapse Spark-poolanteckningsböcker stöder automatisk skalning och automatisk avslutning för att minska den totala ägandekostnaden (TCO). Dataexperter kan använda MLflow-ramverket med öppen källkod för att hantera maskininlärningslivscykeln.
ML.NET
ML.NET är ett plattformsoberoende ramverk för maskininlärning med öppen källkod för Windows, Linux och macOS. Microsoft skapade ML.NET så att .NET-utvecklare kan använda befintliga verktyg, till exempel ML.NET Model Builder för Visual Studio, för att utveckla anpassade maskininlärningsmodeller och integrera dem i sina .NET-program.
Dricks
Microsoft har utökat sin maskininlärningsfunktion till .NET-utvecklare.
.NET för Apache Spark
.NET för Apache Spark utökar Spark-stöd utöver R, Scala, Python och Java till .NET och syftar till att göra Spark tillgängligt för .NET-utvecklare i alla Spark-API:er. .NET för Apache Spark är för närvarande endast tillgängligt på Apache Spark i HDInsight, men Microsoft har för avsikt att göra .NET för Apache Spark tillgängligt i Azure Synapse Spark-poolanteckningsböcker.
Använda Azure Synapse Analytics med ditt informationslager
Om du vill kombinera maskininlärningsmodeller med Azure Synapse kan du:
Använd maskininlärningsmodeller i batch eller i realtid på strömmande data för att skapa nya insikter och lägga till dessa insikter i det du redan vet i Azure Synapse.
Använd data i Azure Synapse för att utveckla och träna nya förutsägelsemodeller för distribution någon annanstans, till exempel i andra program.
Distribuera maskininlärningsmodeller, inklusive modeller som tränats någon annanstans, i Azure Synapse för att analysera data i ditt informationslager och driva nytt affärsvärde.
Dricks
Träna, testa, utvärdera och köra maskininlärningsmodeller i stor skala i Azure Synapse Spark-poolanteckningsböcker med hjälp av data i Azure Synapse.
Dataexperter kan använda RStudio, Jupyter Notebooks och Azure Synapse Spark-poolanteckningsböcker tillsammans med Azure Machine Learning för att utveckla maskininlärningsmodeller som körs i stor skala på Notebook-filer för Azure Synapse Spark-pooler med hjälp av data i Azure Synapse. Dataexperter kan till exempel skapa en oövervakad modell för att segmentera kunder för att driva olika marknadsföringskampanjer. Använd övervakad maskininlärning för att träna en modell för att förutsäga ett specifikt resultat, till exempel för att förutsäga en kunds benägenhet att omsättning, eller för att rekommendera det näst bästa erbjudandet för en kund att försöka öka sitt värde. Följande diagram visar hur Azure Synapse kan användas för Azure Machine Learning.
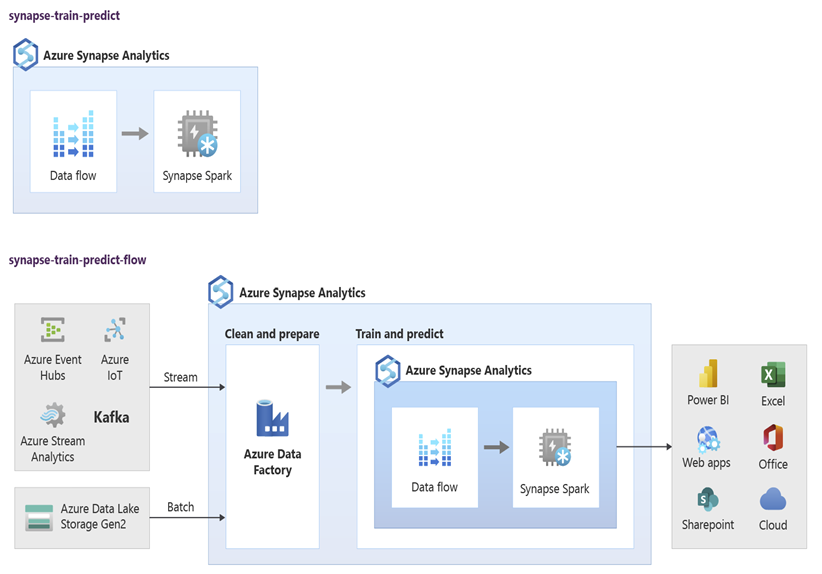
I ett annat scenario kan du mata in sociala nätverk eller granska webbplatsdata i Data Lake Storage och sedan förbereda och analysera data i stor skala på en Azure Synapse Spark-poolanteckningsbok med hjälp av bearbetning av naturligt språk för att bedöma kundernas attityd om dina produkter eller varumärke. Du kan sedan lägga till dessa poäng i informationslagret. Genom att använda stordataanalys för att förstå effekten av negativa sentiment på produktförsäljningen lägger du till det du redan vet i informationslagret.
Dricks
Skapa nya insikter med hjälp av maskininlärning i Azure i batch eller i realtid och lägg till det du vet i ditt informationslager.
Integrera direktuppspelningsdata i Azure Synapse Analytics
När du analyserar data i ett modernt informationslager måste du kunna analysera strömmande data i realtid och koppla dem till historiska data i ditt informationslager. Ett exempel är att kombinera IoT-data med produkt- eller tillgångsdata.
Dricks
Integrera ditt informationslager med strömmande data från IoT-enheter eller klickströmmar.
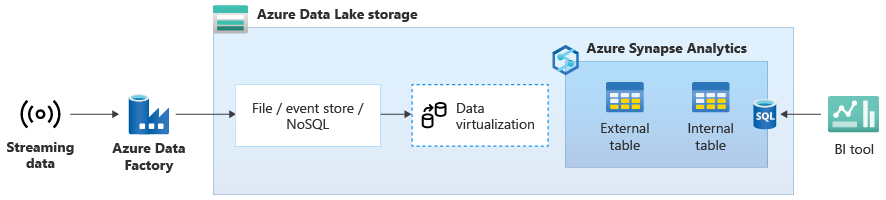
När du har migrerat ditt informationslager till Azure Synapse kan du introducera direktuppspelningsdataintegrering som en del av en moderniseringsövning för informationslager genom att dra nytta av de extra funktionerna i Azure Synapse. Det gör du genom att mata in strömmande data via Event Hubs, andra tekniker som Apache Kafka eller eventuellt ditt befintliga ETL-verktyg om det stöder strömmande datakällor. Lagra data i Data Lake Storage. Skapa sedan en extern tabell i Azure Synapse med PolyBase och peka på data som strömmas till Data Lake Storage så att ditt informationslager nu innehåller nya tabeller som ger åtkomst till strömmande realtidsdata. Fråga den externa tabellen som om data fanns i informationslagret med hjälp av standard-T-SQL från alla BI-verktyg som har åtkomst till Azure Synapse. Du kan också koppla strömmande data till andra tabeller med historiska data för att skapa vyer som kopplar direktuppspelningsdata till historiska data för att göra det enklare för företagsanvändare att komma åt data.
Dricks
Mata in strömmande data till Data Lake Storage från Event Hubs eller Apache Kafka och få åtkomst till data från Azure Synapse med hjälp av externa PolyBase-tabeller.
I följande diagram är ett informationslager i realtid i Azure Synapse integrerat med strömmande data i Data Lake Storage.
Skapa ett logiskt informationslager med PolyBase
Med PolyBase kan du skapa ett logiskt informationslager för att förenkla användaråtkomsten till flera analysdatalager. Många företag har antagit analytiska datalager för "arbetsbelastningsoptimerade" under de senaste åren utöver sina informationslager. Analysplattformarna i Azure omfattar:
Data Lake Storage med Azure Synapse Spark-poolanteckningsboken (Spark som en tjänst) för stordataanalys.
HDInsight (Hadoop som en tjänst), även för stordataanalys.
NoSQL Graph-databaser för grafanalys, vilket kan göras i Azure Cosmos DB.
Event Hubs och Stream Analytics för realtidsanalys av data i rörelse.
Du kan ha motsvarigheter från andra plattformar än Microsoft eller ett MDM-system (Master Data Management) som måste nås för konsekventa betrodda data på kunder, leverantörer, produkter, tillgångar med mera.
Dricks
PolyBase förenklar åtkomsten till flera underliggande analysdatalager i Azure för att underlätta åtkomsten för företagsanvändare.
Dessa analysplattformar uppstod på grund av explosionen av nya datakällor inom och utanför företaget och företagsanvändares efterfrågan på att samla in och analysera nya data. De nya datakällorna omfattar:
Datorgenererade data, till exempel IoT-sensordata och klickströmsdata.
Mänskligt genererade data, till exempel sociala nätverksdata, granska webbplatsdata, inkommande e-post, bilder och video för kunder.
Andra externa data, till exempel öppna myndighetsdata och väderdata.
Dessa nya data går utöver strukturerade transaktionsdata och huvudsakliga datakällor som vanligtvis matar in informationslager och innehåller ofta:
- Halvstrukturerade data som JSON, XML eller Avro.
- Ostrukturerade data som text, röst, bild eller video, vilket är mer komplext att bearbeta och analysera.
- Data med hög volym, data med hög hastighet eller både och.
Därför har nya mer komplexa typer av analyser uppstått, till exempel bearbetning av naturligt språk, grafanalys, djupinlärning, strömmande analys eller komplex analys av stora mängder strukturerade data. Den här typen av analys sker vanligtvis inte i ett informationslager, så det är inte förvånande att se olika analysplattformar för olika typer av analytiska arbetsbelastningar, som du ser i följande diagram.
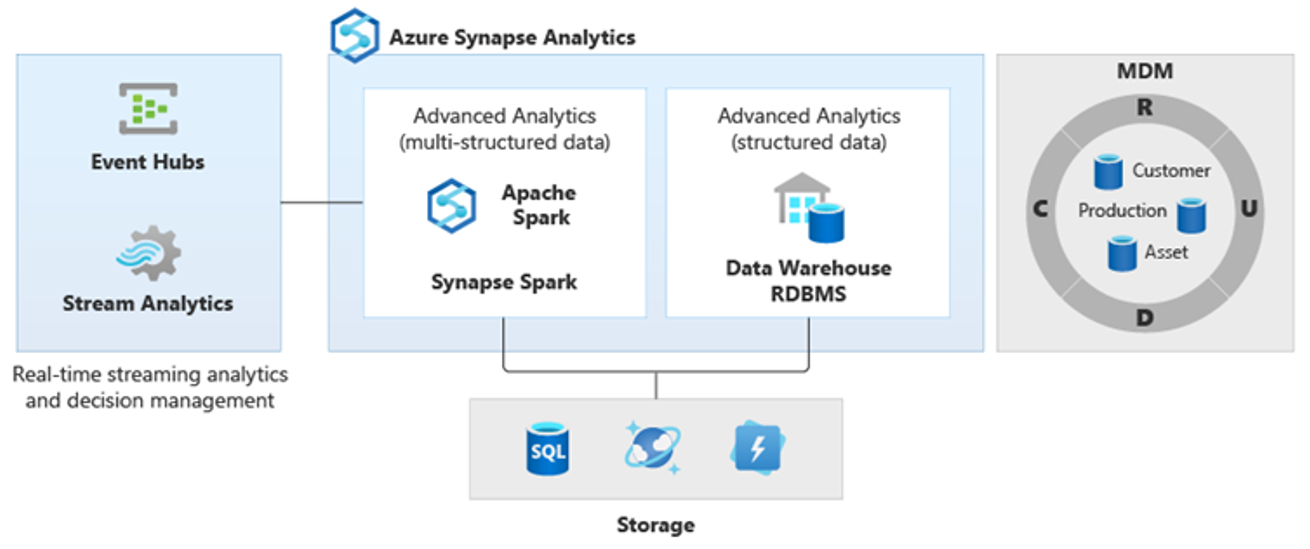
Dricks
Möjligheten att få data i flera analysdatalager att se ut som om allt finns i ett system och ansluta dem till Azure Synapse kallas för en arkitektur för logiskt informationslager.
Eftersom dessa plattformar ger nya insikter är det normalt att se ett krav på att kombinera de nya insikterna med det du redan vet i Azure Synapse, vilket är vad PolyBase gör möjligt.
Genom att använda PolyBase-datavirtualisering i Azure Synapse kan du implementera ett logiskt informationslager där data i Azure Synapse är anslutna till data i andra Azure- och lokala analysdatalager som HDInsight, Azure Cosmos DB eller strömmande data som flödar till Data Lake Storage från Stream Analytics eller Event Hubs. Den här metoden minskar komplexiteten för användare, som har åtkomst till externa tabeller i Azure Synapse och inte behöver veta att de data de kommer åt lagras i flera underliggande analyssystem. Följande diagram visar en komplex informationslagerstruktur som nås via jämförelsevis enklare men ändå kraftfulla UI-metoder.
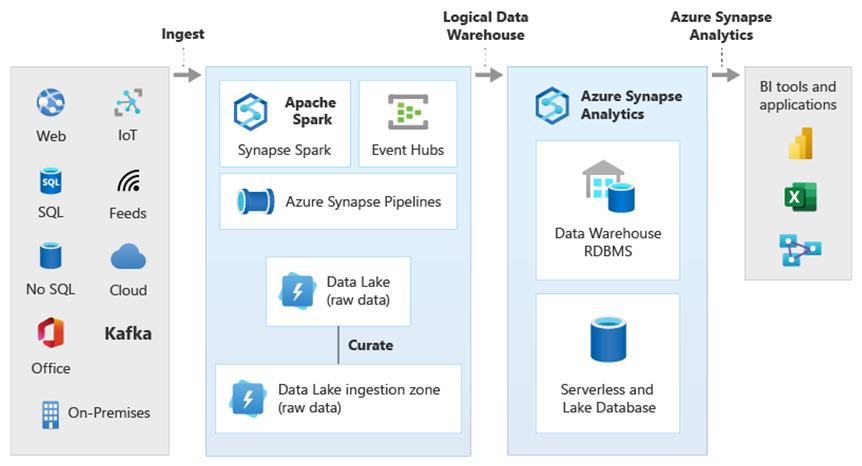
Diagrammet visar hur andra tekniker i Microsofts analytiska ekosystem kan kombineras med funktionen för den logiska informationslagerarkitekturen i Azure Synapse. Du kan till exempel mata in data i Data Lake Storage och kurera data med hjälp av Data Factory för att skapa betrodda dataprodukter som representerar logiska dataentiteter i Microsoft Lake Database . Dessa betrodda, allmänt förstådda data kan sedan användas och återanvändas i olika analysmiljöer, till exempel Azure Synapse, Azure Synapse Spark-poolanteckningsböcker eller Azure Cosmos DB. Alla insikter som skapas i dessa miljöer är tillgängliga via ett logiskt informationslager för datavirtualiseringslager som möjliggörs av PolyBase.
Dricks
En arkitektur för logiskt informationslager förenklar användarnas åtkomst till data och lägger till nytt värde i det du redan vet i ditt informationslager.
Slutsatser
När du har migrerat ditt informationslager till Azure Synapse kan du dra nytta av andra tekniker i Microsofts analysekosystem. På så sätt moderniserar du inte bara ditt informationslager, utan ger insikter som skapas i andra Azure-analysdatalager i en integrerad analysarkitektur.
Du kan bredda ETL-bearbetningen för att mata in data av alla typer i Data Lake Storage och sedan förbereda och integrera data i stor skala med datafabriken för att skapa betrodda, allmänt förstådda datatillgångar. Dessa tillgångar kan användas av ditt informationslager och nås av dataforskare och andra program. Du kan skapa analyspipelines i realtid och batchorienterade analyspipelines och skapa maskininlärningsmodeller som ska köras i batch, i realtid på strömmande data och på begäran som en tjänst.
Du kan använda PolyBase eller COPY INTO gå längre än ditt informationslager för att förenkla åtkomsten till insikter från flera underliggande analysplattformar i Azure. Det gör du genom att skapa holistiska integrerade vyer i ett logiskt informationslager som stöder åtkomst till direktuppspelning, stordata och traditionella informationslagerinsikter från BI-verktyg och program.
Genom att migrera ditt informationslager till Azure Synapse kan du dra nytta av det omfattande Microsoft-analysekosystem som körs i Azure för att skapa ett nytt värde i din verksamhet.
Nästa steg
Mer information om hur du migrerar till en dedikerad SQL-pool finns i Migrera ett informationslager till en dedikerad SQL-pool i Azure Synapse Analytics.