Självstudie: Textanalys med Azure AI-tjänster
I den här självstudien lär du dig hur du använder Textanalys för att analysera ostrukturerad text i Azure Synapse Analytics. Textanalys är en Azure AI-tjänst som gör att du kan utföra textutvinning och textanalys med NLP-funktioner (Natural Language Processing).
Den här självstudien visar hur du använder textanalys med SynapseML för att:
- Identifiera sentimentetiketter på menings- eller dokumentnivå
- Identifiera språket för en viss textinmatning
- Identifiera entiteter från en text med länkar till en välkänd kunskapsbas
- Extrahera nyckelfraser från en text
- Identifiera olika entiteter i text och kategorisera dem i fördefinierade klasser eller typer
- Identifiera och redigera känsliga entiteter i en viss text
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
- Azure Synapse Analytics-arbetsyta med ett Azure Data Lake Storage Gen2-lagringskonto konfigurerat som standardlagring. Du måste vara Storage Blob Data-deltagare i Data Lake Storage Gen2-filsystemet som du arbetar med.
- Spark-pool på din Azure Synapse Analytics-arbetsyta. Mer information finns i Skapa en Spark-pool i Azure Synapse.
- Förkonfigurationssteg som beskrivs i självstudien Konfigurera Azure AI-tjänster i Azure Synapse.
Kom igång
Öppna Synapse Studio och skapa en ny notebook-fil. Kom igång genom att importera SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Konfigurera textanalys
Använd den länkade textanalys som du konfigurerade i förkonfigurationsstegen.
linked_service_name = "<Your linked service for text analytics>"
Textsentiment
Analys av textsentiment är ett sätt att identifiera sentimentetiketterna (till exempel "negativa", "neutrala" och "positiva") och konfidenspoäng på menings- och dokumentnivå. Se språk som stöds i Textanalys API för listan över aktiverade språk.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Förväntat resultat
| text | känsla |
|---|---|
| Jag är så glad idag, det är soligt! | positivt |
| Jag är frustrerad över denna rusningstrafik | negativt |
| Azure AI-tjänsterna på spark aint bad | neutralt |
Språkidentifiering
Språkidentifieringen utvärderar textindata för varje dokument och returnerar språkidentifierare med en poäng som anger analysens styrka. Den här funktionen är användbar för innehållslager samlar in godtycklig text, där språket är okänt. Se språk som stöds i Textanalys API för listan över aktiverade språk.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Förväntat resultat
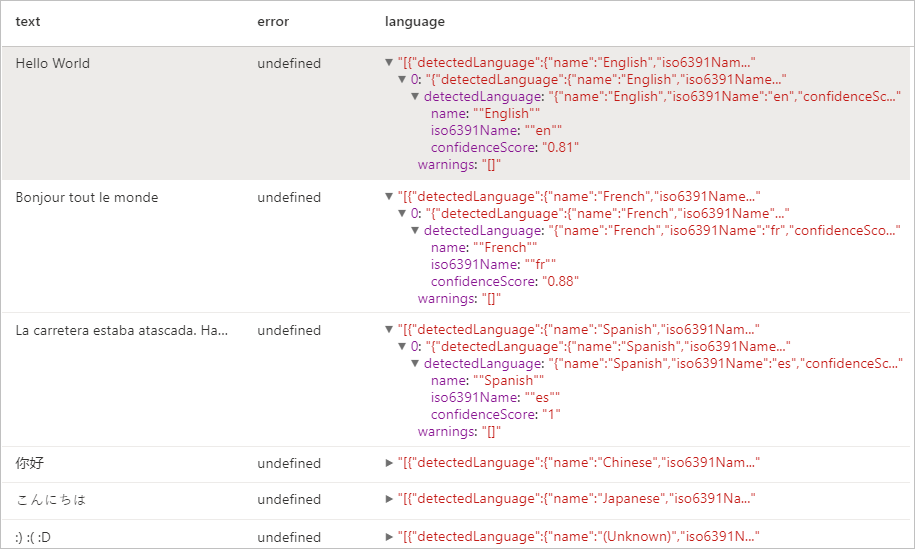
Entitetsidentifiering
Entitetsidentifieringen returnerar en lista över identifierade entiteter med länkar till en välkänd kunskapsbas. Se språk som stöds i Textanalys API för listan över aktiverade språk.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Förväntat resultat
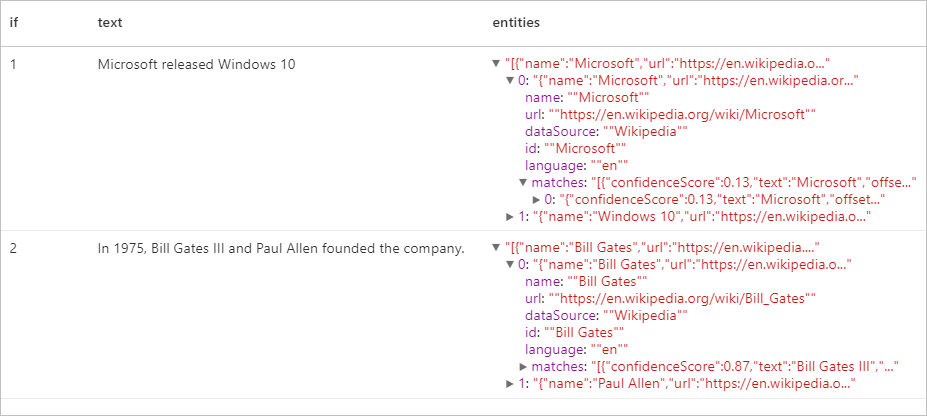
Extraktor för nyckelfras
Extrahering av nyckelfras utvärderar ostrukturerad text och returnerar en lista med nyckelfraser. Den här funktionen är användbar om du snabbt behöver identifiera de viktigaste punkterna i en samling av dokument. Se språk som stöds i Textanalys API för listan över aktiverade språk.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Förväntat resultat
| text | keyPhrases |
|---|---|
| Hej världen. Detta är några indatatext som jag älskar. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Igenkänning av namngiven enhet (NER)
Med namnet Entity Recognition (NER) kan du identifiera olika entiteter i text och kategorisera dem i fördefinierade klasser eller typer som: person, plats, händelse, produkt och organisation. Se språk som stöds i Textanalys API för listan över aktiverade språk.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Förväntat resultat
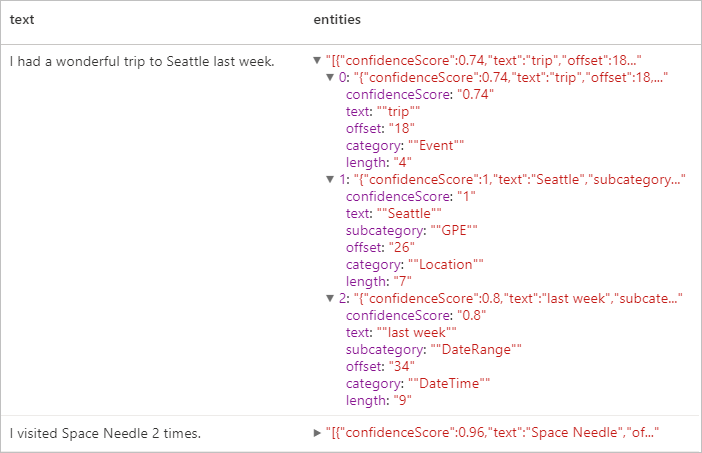
Personligt identifierbar information (PII) V3.1
PII-funktionen är en del av NER och kan identifiera och redigera känsliga entiteter i text som är associerade med en enskild person, till exempel: telefonnummer, e-postadress, postadress, passnummer. Se språk som stöds i Textanalys API för listan över aktiverade språk.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Förväntat resultat
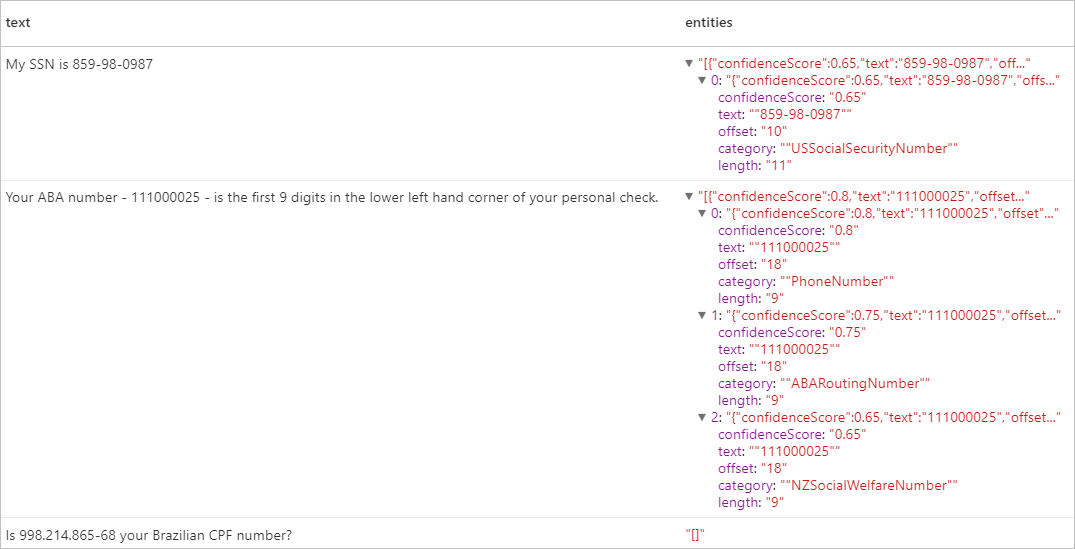
Rensa resurser
För att säkerställa att Spark-instansen stängs av avslutar du alla anslutna sessioner (notebook-filer). Poolen stängs av när den inaktiva tid som anges i Apache Spark-poolen har nåtts. Du kan också välja stoppa session från statusfältet längst upp till höger i anteckningsboken.
