Synapse POC-spelbok: Stordataanalys med Apache Spark-pool i Azure Synapse Analytics
Den här artikeln innehåller en metod på hög nivå för att förbereda och köra ett effektivt POC-projekt (Proof of Concept) för Azure Synapse Analytics för Apache Spark-poolen.
Kommentar
Den här artikeln är en del av Azure Synapse proof of concept-spelboksserien med artiklar. En översikt över serien finns i Spelboken om konceptbevis i Azure Synapse.
Förbereda för POC
Ett POC-projekt kan hjälpa dig att fatta ett välgrundat affärsbeslut om att implementera en stordata- och avancerad analysmiljö på en molnbaserad plattform som utnyttjar Apache Spark-poolen i Azure Synapse.
Ett POC-projekt identifierar dina viktigaste mål och affärsdrivande faktorer som molnbaserad stordata- och förhandsanalysplattform måste stödja. Den testar viktiga mått och bevisar viktiga beteenden som är viktiga för att datatekniken, maskininlärningsmodellens utveckling och träningskraven ska lyckas. En POC är inte utformad för att distribueras till en produktionsmiljö. Det är snarare ett kortsiktigt projekt som fokuserar på viktiga frågor och resultatet kan ignoreras.
Innan du börjar planera ditt Spark POC-projekt:
- Identifiera eventuella begränsningar eller riktlinjer som din organisation har för att flytta data till molnet.
- Identifiera chefs- eller företagssponsorer för ett stordata- och avancerat analysplattformsprojekt. Skydda deras stöd för migrering till molnet.
- Identifiera tillgängligheten för tekniska experter och företagsanvändare som kan stödja dig under POC-körningen.
Innan du börjar förbereda dig för POC-projektet rekommenderar vi att du först läser Apache Spark-dokumentationen.
Dricks
Om du inte har använt Spark-pooler tidigare rekommenderar vi att du går igenom utbildningsvägen Utför datateknik med Azure Synapse Apache Spark-pooler .
Vid det här laget borde du ha fastställt att det inte finns några omedelbara blockerare och sedan kan du börja förbereda dig för din POC. Om du är nybörjare på Apache Spark-pooler i Azure Synapse Analytics kan du läsa den här dokumentationen där du kan få en översikt över Spark-arkitekturen och lära dig hur den fungerar i Azure Synapse.
Utveckla en förståelse för dessa nyckelbegrepp:
- Apache Spark och dess distribuerade arkitektur.
- Spark-begrepp som Resilient Distributed Datasets (RDD) och partitioner (minnesintern och fysisk).
- Azure Synapse-arbetsytan, de olika beräkningsmotorerna, pipelinen och övervakningen.
- Separation av beräkning och lagring i Spark-poolen.
- Autentisering och auktorisering i Azure Synapse.
- Inbyggda anslutningsappar som integreras med azure Synapse-dedikerad SQL-pool, Azure Cosmos DB och andra.
Azure Synapse frikopplar beräkningsresurser från lagring så att du bättre kan hantera dina databehandlingsbehov och kontrollera kostnaderna. Med den serverlösa arkitekturen i Spark-poolen kan du snurra upp och ned samt växa och krympa ditt Spark-kluster, oberoende av din lagring. Du kan pausa (eller automatiskt pausa) ett Spark-kluster helt. På så sätt betalar du bara för beräkning när den används. När den inte används betalar du bara för lagring. Du kan skala upp Ditt Spark-kluster för stora databearbetningsbehov eller stora belastningar och sedan skala ned det igen under mindre intensiva bearbetningstider (eller stänga av det helt). Du kan effektivt skala och pausa ett kluster för att minska kostnaderna. Dina Spark POC-tester bör omfatta datainmatning och databearbetning i olika skalor (små, medelstora och stora) för att jämföra pris och prestanda i olika skala. Mer information finns i Skala Apache Spark-pooler automatiskt i Azure Synapse Analytics.
Det är viktigt att förstå skillnaden mellan de olika uppsättningarna av Spark-API:er så att du kan bestämma vad som fungerar bäst för ditt scenario. Du kan välja den som ger bättre prestanda eller användarvänlighet, och dra nytta av ditt teams befintliga kompetensuppsättningar. Mer information finns i A Tale of Three Apache Spark API:er: RDDs, DataFrames och Datasets.
Data- och filpartitionering fungerar något annorlunda i Spark. Om du förstår skillnaderna kan du optimera prestandan. Mer information finns i Apache Spark-dokumentationen: Partitionsidentifiering och konfigurationsalternativ för partitioner.
Ange målen
Ett lyckat POC-projekt kräver planering. Börja med att identifiera varför du gör en POC för att fullt ut förstå de verkliga motivationerna. Motiveringar kan vara modernisering, kostnadsbesparingar, prestandaförbättringar eller integrerad upplevelse. Se till att dokumentera tydliga mål för din POC och de kriterier som definierar dess framgång. Fråga dig själv:
- Vad vill du ha som utdata från din POC?
- Vad ska du göra med dessa utdata?
- Vem ska använda utdata?
- Vad definierar en lyckad POC?
Tänk på att en POC bör vara en kort och fokuserad insats för att snabbt bevisa en begränsad uppsättning begrepp och funktioner. Dessa begrepp och funktioner bör vara representativa för den övergripande arbetsbelastningen. Om du har en lång lista med objekt att bevisa kanske du vill planera mer än en POC. I så fall definierar du portar mellan POC:erna för att avgöra om du behöver fortsätta med nästa. Med tanke på de olika yrkesroller som kan använda Spark-pooler och notebook-filer i Azure Synapse kan du välja att köra flera POC:er. En POC kan till exempel fokusera på kraven för datateknikrollen, till exempel inmatning och bearbetning. En annan POC kan fokusera på utveckling av maskininlärningsmodeller (ML).
När du tänker på dina POC-mål kan du ställa dig följande frågor för att hjälpa dig att forma målen:
- Migrerar du från en befintlig plattform för stordata och avancerad analys (lokalt eller i molnet)?
- Migrerar du men vill göra så få ändringar som möjligt i befintlig inmatning och databearbetning? Till exempel en Spark till Spark-migrering eller en Hadoop/Hive till Spark-migrering.
- Migrerar du men vill göra några omfattande förbättringar på vägen? Du kan till exempel skriva om MapReduce-jobb som Spark-jobb eller konvertera äldre RDD-baserad kod till DataFrame/Dataset-baserad kod.
- Skapar du en helt ny plattform för stordata och avancerad analys (greenfield-projekt)?
- Vilka är dina nuvarande smärtpunkter? Till exempel skalbarhet, prestanda eller flexibilitet.
- Vilka nya affärskrav behöver du stöd för?
- Vilka serviceavtal måste du uppfylla?
- Vilka blir arbetsbelastningarna? Till exempel ETL, batchbearbetning, dataströmbearbetning, maskininlärningsmodellträning, analys, rapporteringsfrågor eller interaktiva frågor?
- Vilka är färdigheterna hos de användare som kommer att äga projektet (bör POC implementeras)? Till exempel PySpark vs Scala-kunskaper, notebook- och IDE-upplevelse.
Här följer några exempel på POC-målinställning:
- Varför gör vi en POC?
- Vi behöver veta att datainmatning och bearbetningsprestanda för vår stordataarbetsbelastning uppfyller våra nya serviceavtal.
- Vi behöver veta om dataströmbearbetning i nära realtid är möjligt och hur mycket dataflöde det kan stödja. (Kommer det att stödja våra affärskrav?)
- Vi behöver veta om våra befintliga datainmatnings- och transformeringsprocesser passar bra och var förbättringar måste göras.
- Vi behöver veta om vi kan förkorta körningstiderna för dataintegrering och hur mycket.
- Vi behöver veta om våra dataexperter kan skapa och träna maskininlärningsmodeller och utnyttja AI/ML-bibliotek efter behov i en Spark-pool.
- Kommer övergången till molnbaserad Synapse Analytics att uppfylla våra kostnadsmål?
- I slutet av denna POC:
- Vi har data för att avgöra om våra prestandakrav för databehandling kan uppfyllas för både batch- och realtidsströmning.
- Vi kommer att ha testat inmatning och bearbetning av alla våra olika datatyper (strukturerade, halvstrukturerade och ostrukturerade) som stöder våra användningsfall.
- Vi kommer att ha testat en del av vår befintliga komplexa databehandling och kan identifiera det arbete som måste utföras för att migrera vår portfölj av dataintegrering till den nya miljön.
- Vi kommer att ha testat datainmatning och bearbetning och kommer att ha datapunkterna för att uppskatta den ansträngning som krävs för den inledande migreringen och belastningen av historiska data, samt uppskatta den ansträngning som krävs för att migrera vår datainmatning (Azure Data Factory (ADF), Distcp, Databox eller andra).
- Vi kommer att ha testat datainmatning och bearbetning och kan avgöra om våra ETL/ELT-bearbetningskrav kan uppfyllas.
- Vi kommer att ha fått insikter för att bättre uppskatta den ansträngning som krävs för att slutföra implementeringsprojektet.
- Vi kommer att ha testat skalnings- och skalningsalternativ och har datapunkterna för att bättre konfigurera vår plattform för bättre prisprestandainställningar.
- Vi kommer att ha en lista över objekt som kan behöva testas mer.
Planera projektet
Använd dina mål för att identifiera specifika tester och för att tillhandahålla de utdata som du har identifierat. Det är viktigt att se till att du har minst ett test som stöder varje mål och förväntade utdata. Identifiera även specifik datainmatning, batch- eller dataströmbearbetning och alla andra processer som ska köras så att du kan identifiera en mycket specifik datauppsättning och kodbas. Den här specifika datauppsättningen och kodbasen definierar poc-omfånget.
Här är ett exempel på den specificitetsnivå som krävs i planeringen:
- Mål A: Vi behöver veta om vårt krav på datainmatning och bearbetning av batchdata kan uppfyllas under vårt definierade serviceavtal.
- Utdata A: Vi har data för att avgöra om vår batchdatainmatning och bearbetning kan uppfylla databehandlingskravet och serviceavtalet.
- Test A1: Bearbetningsfrågorna A, B och C identifieras som bra prestandatester eftersom de ofta körs av datateknikteamet. Dessutom representerar de övergripande databehandlingsbehov.
- Test A2: Bearbetningsfrågorna X, Y och Z identifieras som bra prestandatester eftersom de innehåller dataströmbearbetningskrav i nära realtid. Dessutom representerar de övergripande händelsebaserade dataströmbearbetningsbehov.
- Test A3: Jämför prestandan för dessa frågor i olika skala i Spark-klustret (varierande antal arbetsnoder, storleken på arbetsnoderna – som små, medelstora och stora – antal och storleken på exekutorer) med det riktmärke som erhålls från det befintliga systemet. Håll lagen om minskande avkastning i åtanke. Att lägga till fler resurser (antingen genom att skala upp eller skala ut) kan bidra till att uppnå parallellitet, men det finns en viss gräns som är unik för varje scenario för att uppnå parallelliteten. Identifiera den optimala konfigurationen för varje identifierat användningsfall i testningen.
- Mål B: Vi behöver veta om våra dataforskare kan skapa och träna maskininlärningsmodeller på den här plattformen.
- Utdata B: Vi har testat några av våra maskininlärningsmodeller genom att träna dem på data i en Spark-pool eller en SQL-pool och utnyttja olika maskininlärningsbibliotek. Dessa tester hjälper dig att avgöra vilka maskininlärningsmodeller som kan migreras till den nya miljön
- Test B1: Specifika maskininlärningsmodeller testas.
- Test B2: Testa grundläggande maskininlärningsbibliotek som medföljer Spark (Spark MLLib) tillsammans med ytterligare ett bibliotek som kan installeras på Spark (till exempel scikit-learn) för att uppfylla kraven.
- Mål C: Vi kommer att ha testat datainmatning och kommer att ha datapunkterna till:
- Beräkna arbetet med vår inledande historiska datamigrering till Data Lake och/eller Spark-poolen.
- Planera en metod för att migrera historiska data.
- Utdata C: Vi kommer att ha testat och fastställt den datainmatningshastighet som kan uppnås i vår miljö och kan avgöra om vår datainmatningshastighet är tillräcklig för att migrera historiska data under den tillgängliga tidsperioden.
- Test C1: Testa olika metoder för historisk datamigrering. Mer information finns i Överföra data till och från Azure.
- Test C2: Identifiera allokerad bandbredd för ExpressRoute och om det finns någon begränsningskonfiguration av infrateamet. Mer information finns i Vad är Azure ExpressRoute? (Bandbreddsalternativ).
- Test C3: Testa dataöverföringshastigheten för datamigrering både online och offline. Mer information finns i aktiviteten Kopiera guide för prestanda och skalbarhet.
- Test C4: Testa dataöverföring från datasjön till SQL-poolen med hjälp av antingen ADF, Polybase eller kommandot COPY. Mer information finns i Datainläsningsstrategier för dedikerad SQL-pool i Azure Synapse Analytics.
- Mål D: Vi kommer att ha testat datainmatningshastigheten för inkrementell datainläsning och har datapunkterna för att uppskatta datainmatningen och bearbetningstiden till datasjön och/eller den dedikerade SQL-poolen.
- Utdata D: Vi kommer att ha testat datainmatningshastigheten och kan avgöra om våra datainmatnings- och bearbetningskrav kan uppfyllas med den identifierade metoden.
- Test D1: Testa den dagliga uppdateringsdatainmatningen och bearbetningen.
- Test D2: Testa den bearbetade databelastningen till den dedikerade SQL-pooltabellen från Spark-poolen. Mer information finns i Azure Synapse Dedicated SQL Pool Connector för Apache Spark.
- Test D3: Kör den dagliga uppdateringsbelastningsprocessen samtidigt som slutanvändarfrågor körs.
Se till att förfina dina tester genom att lägga till flera testscenarier. Azure Synapse gör det enkelt att testa olika skalning (varierande antal arbetsnoder, storleken på arbetsnoderna som små, medelstora och stora) för att jämföra prestanda och beteende.
Här följer några testscenarier:
- Spark-pooltest A: Vi kör databearbetning över flera nodtyper (små, medelstora och stora) samt olika antal arbetsnoder.
- Spark-pooltest B: Vi läser in/hämtar bearbetade data från Spark-poolen till den dedikerade SQL-poolen med hjälp av anslutningsappen.
- Spark-pooltest C: Vi läser in/hämtar bearbetade data från Spark-poolen till Azure Cosmos DB via Azure Synapse Link.
Utvärdera POC-datamängden
Med hjälp av de specifika tester som du har identifierat väljer du en datauppsättning som stöder testerna. Ta dig tid att granska den här datamängden. Du bör kontrollera att datamängden på ett tillfredsställande sätt representerar din framtida bearbetning när det gäller innehåll, komplexitet och skala. Använd inte en datauppsättning som är för liten (mindre än 1 TB) eftersom den inte ger representativa prestanda. Använd däremot inte en datauppsättning som är för stor eftersom POC inte ska bli en fullständig datamigrering. Se till att få lämpliga riktmärken från befintliga system så att du kan använda dem för prestandajämförelser.
Viktigt!
Kontrollera att du kontrollerar eventuella blockerare med företagsägare innan du flyttar data till molnet. Identifiera eventuella säkerhets- eller sekretessproblem eller eventuella datafördunklingsbehov som bör göras innan data flyttas till molnet.
Skapa en arkitektur på hög nivå
Baserat på den övergripande arkitekturen i din föreslagna framtida tillståndsarkitektur identifierar du de komponenter som ska ingå i din POC. Din framtida arkitektur på hög nivå innehåller troligen många datakällor, många datakonsumenter, stordatakomponenter och eventuellt maskininlärning och AI-datakonsumenter (artificiell intelligens). DIN POC-arkitektur bör specifikt identifiera komponenter som kommer att ingå i POC. Det är viktigt att den identifierar alla komponenter som inte ingår i POC-testningen.
Om du redan använder Azure kan du identifiera alla resurser som du redan har på plats (Microsoft Entra-ID, ExpressRoute och andra) som du kan använda under POC. Identifiera även de Azure-regioner som din organisation använder. Nu är det en bra tid att identifiera dataflödet för din ExpressRoute-anslutning och att kontrollera med andra företagsanvändare att din POC kan förbruka en del av det dataflödet utan att påverka produktionssystemen negativt.
Mer information finns i Arkitekturer för stordata.
Identifiera POC-resurser
Identifiera specifikt de tekniska resurser och tidsåtaganden som krävs för att stödja din POC. Din POC behöver:
- En företagsrepresentant som övervakar krav och resultat.
- En programdataexpert för att hämta data för POC och ge kunskap om befintliga processer och logik.
- En Apache Spark- och Spark-poolexpert.
- En expertrådgivare för att optimera POC-testerna.
- Resurser som krävs för specifika komponenter i ditt POC-projekt, men som inte nödvändigtvis krävs under poc-programmets varaktighet. Dessa resurser kan omfatta nätverksadministratörer, Azure-administratörer, Active Directory-administratörer, Azure Portal administratörer och andra.
- Se till att alla nödvändiga Azure-tjänstresurser har etablerats och att den åtkomstnivå som krävs beviljas, inklusive åtkomst till lagringskonton.
- Se till att du har ett konto som har nödvändiga behörigheter för dataåtkomst för att hämta data från alla datakällor i POC-omfånget.
Dricks
Vi rekommenderar att du engagerar en expertrådgivare för att hjälpa till med din POC. Microsofts partnercommunity har global tillgänglighet för expertkonsulter som kan hjälpa dig att utvärdera, utvärdera eller implementera Azure Synapse.
Ange tidslinjen
Granska din POC-planeringsinformation och dina affärsbehov för att identifiera en tidsram för din POC. Gör realistiska uppskattningar av den tid som krävs för att slutföra POC-målen. Tiden för att slutföra din POC påverkas av storleken på din POC-datamängd, antalet och komplexiteten i tester och antalet gränssnitt som ska testas. Om du uppskattar att din POC kommer att köras längre än fyra veckor kan du överväga att minska POC-omfånget för att fokusera på de högsta prioritetsmålen. Se till att få godkännande och åtagande från alla ledande resurser och sponsorer innan du fortsätter.
Omsätta POC i praktiken
Vi rekommenderar att du kör ditt POC-projekt med disciplin och stränghet för alla produktionsprojekt. Kör projektet enligt plan och hantera en process för ändringsbegäran för att förhindra okontrollerad tillväxt av POC:s omfång.
Här är några exempel på uppgifter på hög nivå:
Skapa en Synapse-arbetsyta, Spark-pooler och dedikerade SQL-pooler, lagringskonton och alla Azure-resurser som identifieras i POC-planen.
Läs in POC-datauppsättning:
- Gör data tillgängliga i Azure genom att extrahera från källan eller genom att skapa exempeldata i Azure. För ytterligare information, se:
- Testa den dedikerade anslutningsappen för Spark-poolen och den dedikerade SQL-poolen.
Migrera befintlig kod till Spark-poolen:
- Om du migrerar från Spark är det troligt att migreringsarbetet är enkelt med tanke på att Spark-poolen utnyttjar Spark-distributionen med öppen källkod. Men om du använder leverantörsspecifika funktioner ovanpå viktiga Spark-funktioner måste du mappa dessa funktioner korrekt till Spark-poolfunktionerna.
- Om du migrerar från ett icke-Spark-system varierar migreringen beroende på komplexiteten.
Kör testerna:
- Många tester kan köras parallellt över flera Spark-poolkluster.
- Registrera dina resultat i ett förbrukningsbart och lättförståeligt format.
Övervaka för felsökning och prestanda. Mer information finns i:
Övervaka datasnedvridning, tidssnedställdhet och användningsprocent för exekutor genom att öppna fliken Diagnostik på Sparks historikserver.
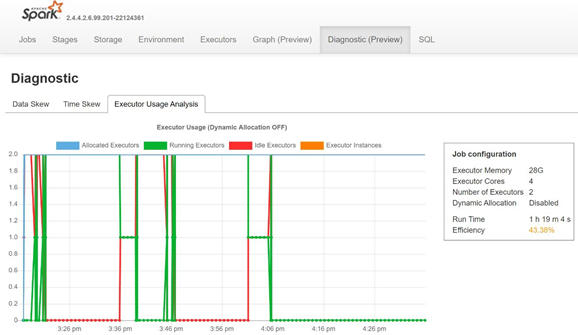
Tolka POC-resultaten
När du slutför alla POC-tester utvärderar du resultatet. Börja med att utvärdera om POC-målen uppnåddes och önskade utdata samlades in. Avgör om fler tester är nödvändiga eller om några frågor behöver åtgärdas.