Filtrera och mata in till Azure Data Explorer med Stream Analytics utan kodredigerare
Den här artikeln beskriver hur du kan använda redigeringsprogrammet utan kod för att enkelt skapa ett Stream Analytics-jobb. Den läser kontinuerligt från dina händelsehubbar, filtrerar inkommande data och skriver sedan resultatet kontinuerligt till Azure Data Explorer.
Förutsättningar
- Dina Azure Event Hubs- och Azure Data Explorer-resurser måste vara offentligt tillgängliga och inte vara bakom en brandvägg eller skyddas i ett virtuellt Azure-nätverk
- Data i dina Event Hubs måste serialiseras i antingen JSON-, CSV- eller Avro-format.
Utveckla ett Stream Analytics-jobb för att filtrera och mata in realtidsdata
Leta upp och välj Azure Event Hubs-instansen i Azure Portal.
Välj Funktioner>Bearbeta data och välj sedan Starta på kortet Filtrera och lagra data till Azure Data Explorer.
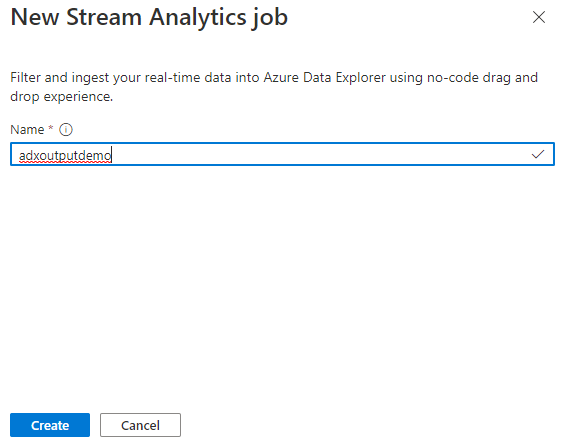
Ange ett namn för Stream Analytics-jobbet och välj sedan Skapa.
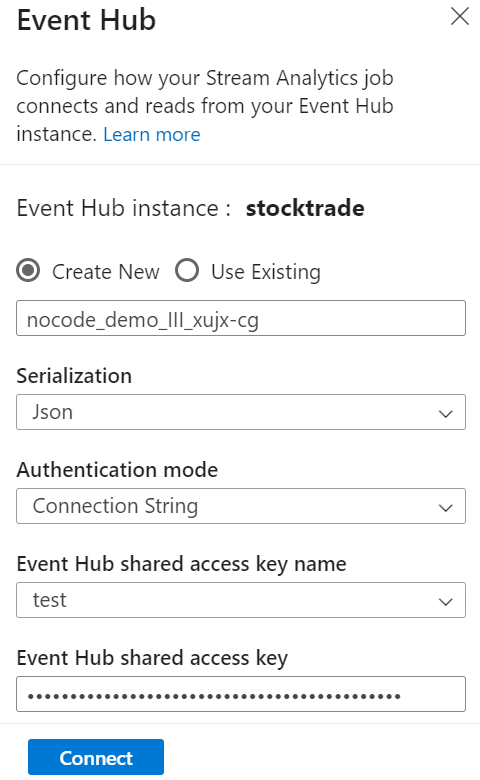
Ange serialiseringstypen för dina data i fönstret Event Hubs och den autentiseringsmetod som jobbet ska använda för att ansluta till Händelsehubbar. Välj sedan Anslut.
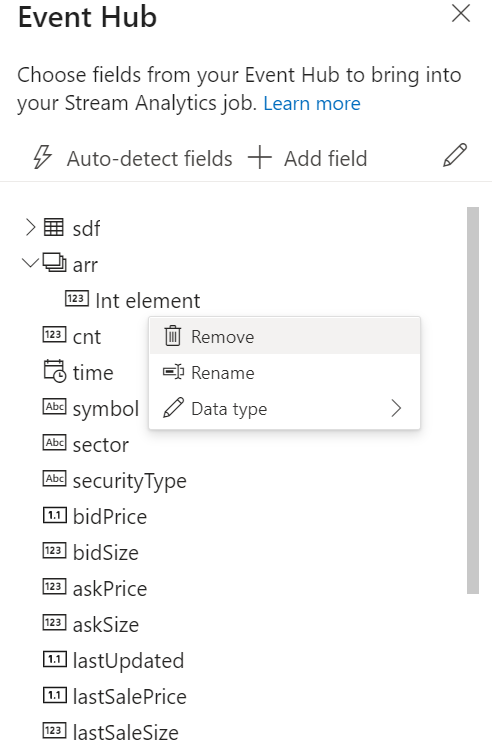
När anslutningen har upprättats och du har dataströmmar som flödar till din Event Hubs-instans ser du omedelbart två saker:
- Fält som finns i indata. Du kan välja Lägg till fält eller välja symbolen med tre punkter bredvid ett fält för att ta bort, byta namn på eller ändra dess typ.
- Ett live-exempel på inkommande data i tabellen Dataförhandsgranskning under diagramvyn. Den uppdateras automatiskt med jämna mellanrum. Du kan välja Pausa förhandsversionen av direktuppspelning för att se en statisk vy över exempelindata.

- Fält som finns i indata. Du kan välja Lägg till fält eller välja symbolen med tre punkter bredvid ett fält för att ta bort, byta namn på eller ändra dess typ.
Välj panelen Filter för att aggregera data. I området Filter väljer du ett fält för att filtrera inkommande data med ett villkor.
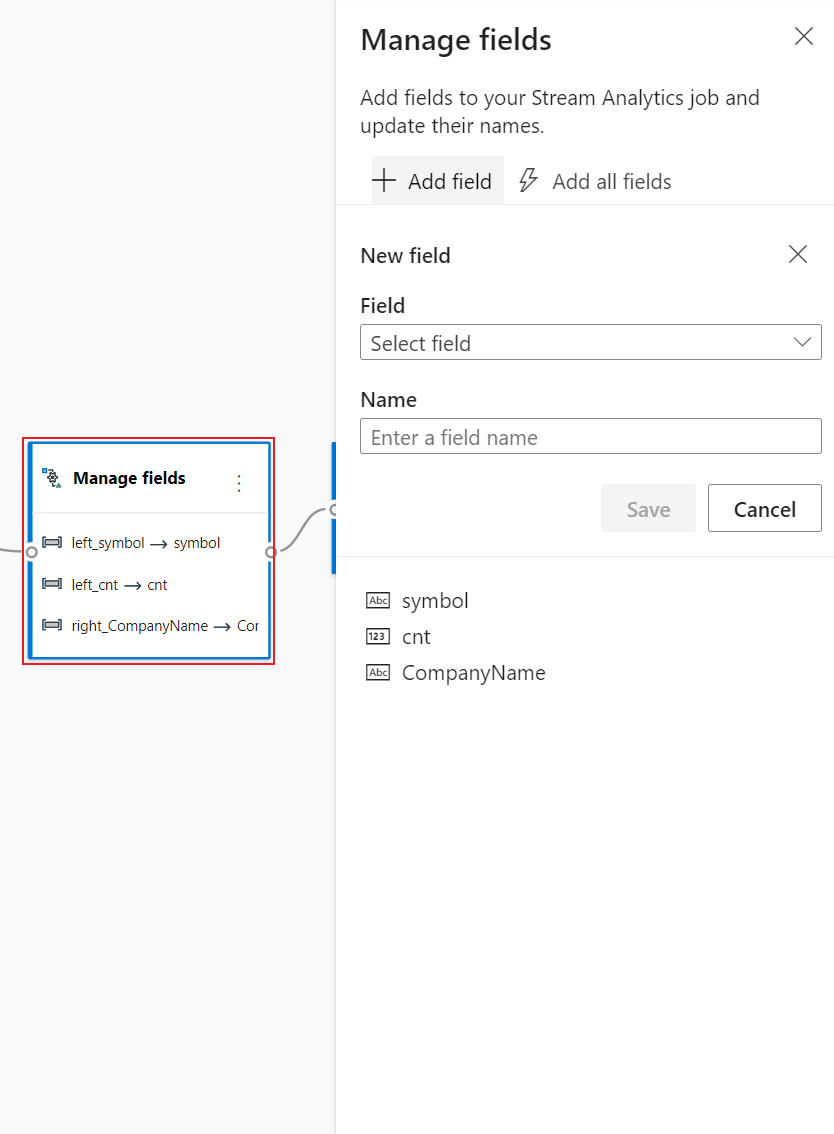
Välj panelen Hantera . I konfigurationspanelen Hantera fält väljer du de fält som du vill mata ut till händelsehubben. Om du vill lägga till alla fält väljer du Lägg till alla fält.
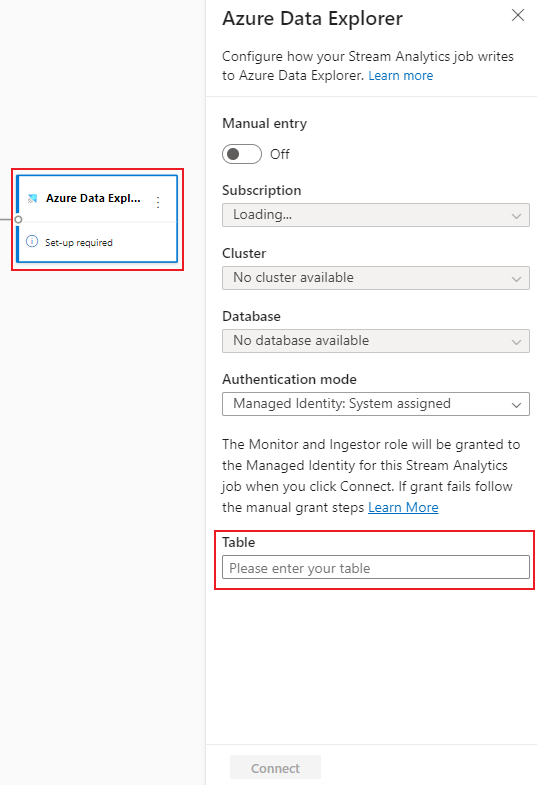
Välj Azure Data Explorer-panelen . I konfigurationspanelen fyller du i nödvändiga parametrar och ansluter.
Kommentar
Tabellen måste finnas i den valda databasen och tabellschemat måste exakt matcha antalet fält och deras typer som dataförhandsgranskningen genererar.
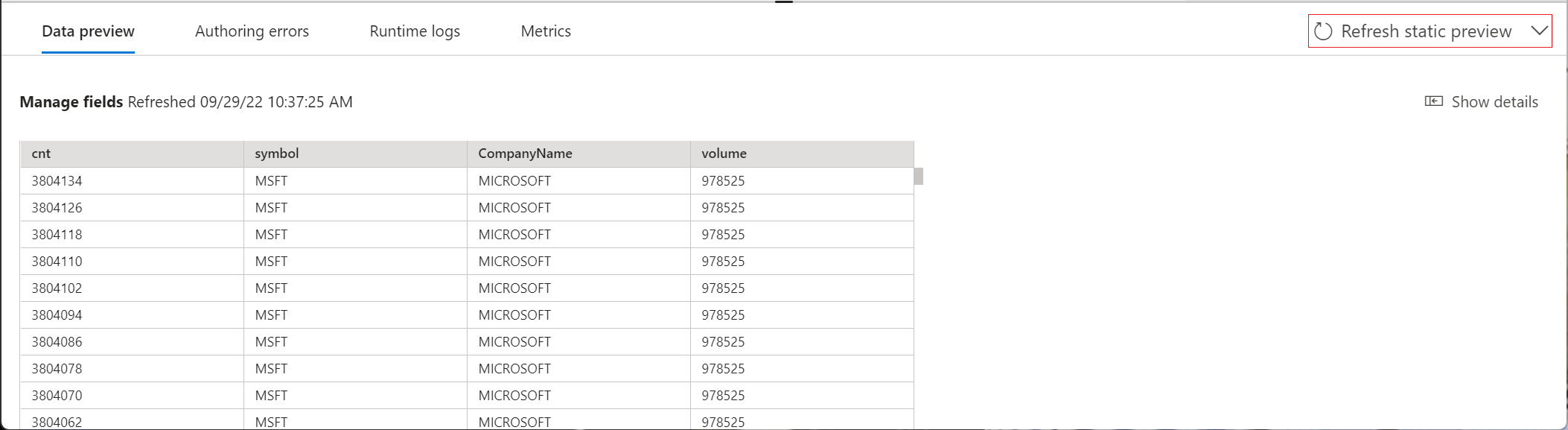
Du kan också välja Hämta statisk förhandsversion/Uppdatera statisk förhandsversion för att se den dataförhandsgranskning som ska matas in i händelsehubben.
Välj Spara och välj sedan Starta Stream Analytics-jobbet.
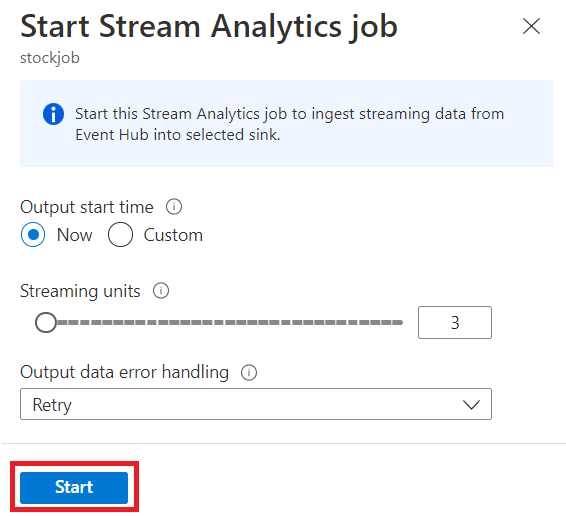
Om du vill starta jobbet anger du:
- Antalet strömningsenheter (SUs) som jobbet körs med. SUs representerar mängden beräkning och minne som allokerats till jobbet. Vi rekommenderar att du börjar med tre och sedan justerar efter behov.
- Hantering av utdatafel – Du kan ange vilket beteende du vill ha när ett jobbs utdata till målet misslyckas på grund av datafel. Jobbet försöker som standard igen tills skrivåtgärden har slutförts. Du kan också välja att släppa sådana utdatahändelser.
När du har valt Start börjar jobbet köras inom två minuter och måtten öppnas i flikavsnittet nedan.
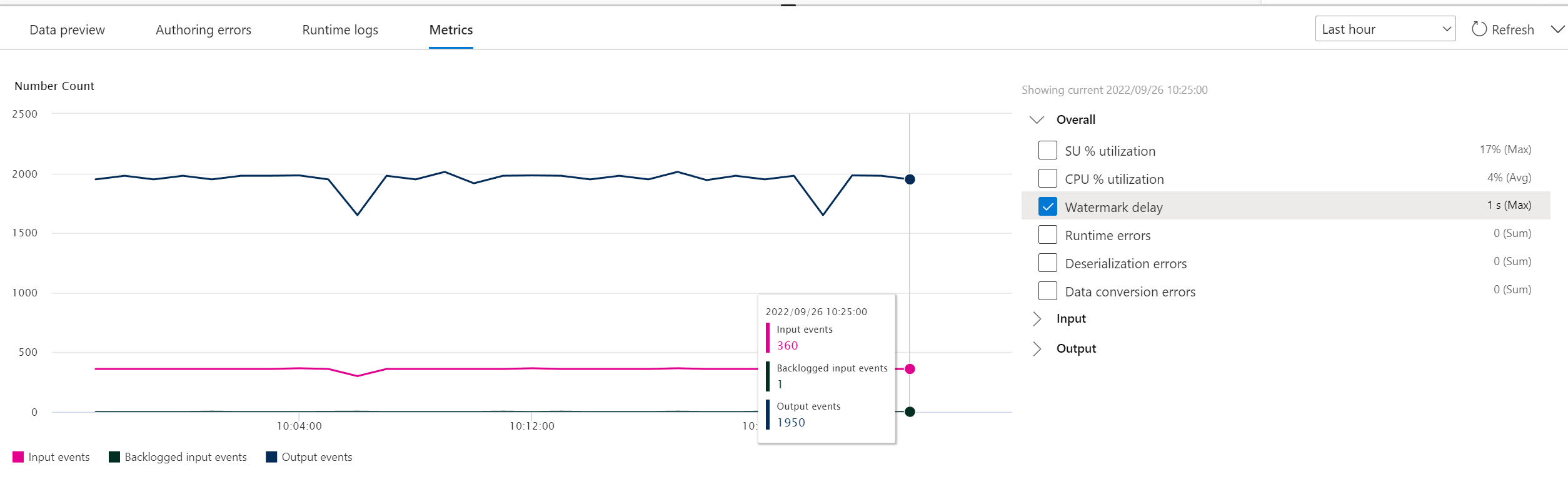
Du kan också se jobbet under avsnittet Processdata på fliken Stream Analytics-jobb . Välj Öppna mått om du vill övervaka det eller stoppa och starta om det efter behov.














Överväganden vid användning av geo-replikeringsfunktionen i Event Hubs
Azure Event Hubs lanserade nyligen geo-replikeringsfunktionen i offentlig förhandsversion. Den här funktionen skiljer sig från geo-haveriberedskapsfunktionen i Azure Event Hubs.
När redundanstypen är Tvingad och replikeringskonsekvensen är asynkron garanterar Stream Analytics-jobbet inte exakt en gång utdata till en Azure Event Hubs-utdata.
Azure Stream Analytics, som producent med en händelsehubb som utdata, kan observera vattenstämpelfördröjning på jobbet under redundansväxlingen och under begränsningen av Event Hubs om replikeringsfördröjningen mellan primär och sekundär når den maximala konfigurerade fördröjningen.
Azure Stream Analytics, som konsument med Event Hubs som indata, kan observera vattenstämpelfördröjning på jobbet under redundansväxlingen och kan hoppa över data eller hitta duplicerade data när redundansväxlingen är klar.
På grund av dessa varningar rekommenderar vi att du startar om Stream Analytics-jobbet med lämplig starttid direkt efter att Event Hubs-redundansväxlingen har slutförts. Eftersom Geo-replikeringsfunktionen i Event Hubs är en offentlig förhandsversion rekommenderar vi inte heller att du använder det här mönstret för stream analytics-produktionsjobb just nu. Det aktuella Stream Analytics-beteendet förbättras innan funktionen Event Hubs Geo-replikering är allmänt tillgänglig och kan användas i Stream Analytics-produktionsjobb.
Nästa steg
Läs mer om Azure Stream Analytics och hur du övervakar det jobb du har skapat.