Modellera relationer
I den här artikeln beskrivs modelleringsprocessen som hjälper dig att utforma dina Azure Table Storage-lösningar.
Att skapa domänmodeller är ett viktigt steg i utformningen av komplexa system. Vanligtvis använder du modelleringsprocessen för att identifiera entiteter och relationerna mellan dem som ett sätt att förstå affärsdomänen och informera systemets utformning. Det här avsnittet fokuserar på hur du kan översätta några av de vanliga relationstyper som finns i domänmodeller till design för tabelltjänsten. Processen för att mappa från en logisk datamodell till en fysisk NoSQL-baserad datamodell skiljer sig från den som används när du utformar en relationsdatabas. Relationsdatabasdesign förutsätter vanligtvis en datanormaliseringsprocess som optimerats för att minimera redundans – och en deklarativ frågefunktion som sammanfattar hur implementeringen av hur databasen fungerar.
En till många-relationer
En-till-många-relationer mellan affärsdomänobjekt sker ofta: till exempel har en avdelning många anställda. Det finns flera sätt att implementera en-till-många-relationer i tabelltjänsten med för- och nackdelar som kan vara relevanta för det specifika scenariot.
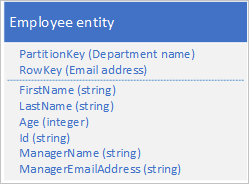
Tänk på exemplet med ett stort multinationellt/regionalt företag med tiotusentals avdelningar och personalenheter där varje avdelning har många anställda och varje anställd som associeras med en specifik avdelning. En metod är att lagra separata avdelnings- och medarbetarentiteter som dessa:

Det här exemplet visar en implicit en-till-många-relation mellan typerna baserat på PartitionKey-värdet . Varje avdelning kan ha många anställda.
Det här exemplet visar också en avdelningsentitet och dess relaterade medarbetarentiteter i samma partition. Du kan välja att använda olika partitioner, tabeller eller till och med lagringskonton för de olika entitetstyperna.
En annan metod är att avnormalisera dina data och endast lagra medarbetarentiteter med avnormaliserade avdelningsdata som visas i följande exempel. I det här scenariot kanske den här avnormaliserade metoden inte är den bästa om du har ett krav på att kunna ändra information om en avdelningschef eftersom du måste uppdatera varje anställd på avdelningen för att göra detta.
Mer information finns i mönstret Avormalisering senare i den här guiden.
I följande tabell sammanfattas för- och nackdelarna med var och en av de metoder som beskrivs ovan för lagring av anställda och avdelningsentiteter som har en en-till-många-relation. Du bör också tänka på hur ofta du förväntar dig att utföra olika åtgärder: det kan vara acceptabelt att ha en design som innehåller en dyr åtgärd om den åtgärden bara sker sällan.
| Metod | Fördelar | Nackdelar |
|---|---|---|
| Separata entitetstyper, samma partition, samma tabell |
|
|
| Separata entitetstyper, olika partitioner eller tabeller eller lagringskonton |
|
|
| Avormalisera till en enskild entitetstyp |
|
|
*Mer information finns i Entitetsgrupptransaktioner
Hur du väljer mellan de här alternativen och vilka av fördelarna och nackdelarna som är viktigast beror på dina specifika programscenarier. Till exempel hur ofta du ändrar avdelningsentiteter; gör alla dina medarbetare frågor behöver ytterligare avdelningsinformation; hur nära är du skalbarhetsgränserna för dina partitioner eller ditt lagringskonto?
En-till-en-relationer
Domänmodeller kan innehålla en-till-en-relationer mellan entiteter. Om du behöver implementera en en-till-en-relation i tabelltjänsten måste du också välja hur du ska länka de två relaterade entiteterna när du behöver hämta dem båda. Den här länken kan antingen vara implicit, baserat på en konvention i nyckelvärdena eller explicit genom att lagra en länk i form av PartitionKey - och RowKey-värden i varje entitet till dess relaterade entitet. En diskussion om huruvida du ska lagra de relaterade entiteterna i samma partition finns i avsnittet En-till-många-relationer.
Det finns också implementeringsöverväganden som kan leda till att du implementerar en-till-en-relationer i tabelltjänsten:
- Hantera stora entiteter (mer information finns i Mönster för stora entiteter).
- Implementera åtkomstkontroller (mer information finns i Kontrollera åtkomst med signaturer för delad åtkomst).
Ansluta till klienten
Även om det finns sätt att modellera relationer i tabelltjänsten bör du inte glömma att de två främsta orsakerna till att använda tabelltjänsten är skalbarhet och prestanda. Om du upptäcker att du modellerar många relationer som äventyrar lösningens prestanda och skalbarhet bör du fråga dig själv om det är nödvändigt att skapa alla datarelationer i tabelldesignen. Du kanske kan förenkla designen och förbättra lösningens skalbarhet och prestanda om du låter klientprogrammet utföra nödvändiga kopplingar.
Om du till exempel har små tabeller som innehåller data som inte ändras ofta kan du hämta dessa data en gång och cachelagras på klienten. Detta kan undvika upprepade tur och retur-flöden för att hämta samma data. I exemplen som vi har tittat på i den här guiden är det troligt att uppsättningen avdelningar i en liten organisation är liten och ändras sällan, vilket gör den till en bra kandidat för data som klientprogrammet kan ladda ned en gång och cachelagras som uppslagsdata.
Arvsrelationer
Om klientprogrammet använder en uppsättning klasser som ingår i en arvsrelation för att representera affärsentiteter kan du enkelt bevara dessa entiteter i tabelltjänsten. Du kan till exempel ha följande uppsättning klasser definierade i klientprogrammet där Person är en abstrakt klass.
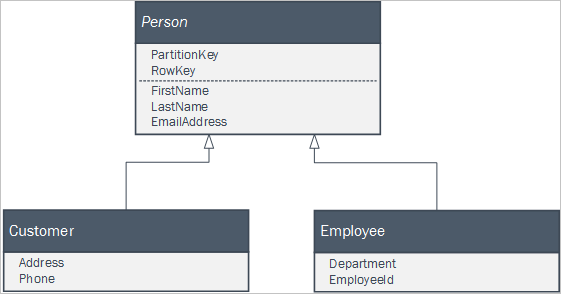
Du kan bevara instanser av de två konkreta klasserna i tabelltjänsten med hjälp av en enda persontabell med entiteter i som ser ut så här:

Mer information om hur du arbetar med flera entitetstyper i samma tabell i klientkoden finns i avsnittet Arbeta med heterogena entitetstyper senare i den här guiden. Detta ger exempel på hur du känner igen entitetstypen i klientkoden.