Optimera filresursprestanda vid åtkomst till stora kataloger från Linux-klienter
Den här artikeln innehåller rekommendationer för att arbeta med kataloger som innehåller ett stort antal filer. Det är vanligtvis en bra idé att minska antalet filer i en enda katalog genom att sprida filerna över flera kataloger. Det finns dock situationer där stora kataloger inte kan undvikas. Tänk på följande när du arbetar med stora kataloger på Azure-filresurser som är monterade på Linux-klienter.
Gäller för
| Typ av filresurs | SMB | NFS |
|---|---|---|
| Standardfilresurser (GPv2), LRS/ZRS |
|
|
| Standardfilresurser (GPv2), GRS/GZRS |
|
|
| Premiumfilresurser (FileStorage), LRS/ZRS |
|
|
Rekommenderade monteringsalternativ
Följande monteringsalternativ är specifika för uppräkning och kan minska svarstiden när du arbetar med stora kataloger.
actimeo
Anger actimeo anger alla av acregmin, acregmax, acdirminoch acdirmax till samma värde. Om actimeo inte anges använder klienten standardvärdena för vart och ett av dessa alternativ.
Vi rekommenderar att du ställer in actimeo mellan 30 och 60 sekunder när du arbetar med stora kataloger. Om du anger ett värde i det här intervallet förblir attributen giltiga under en längre tidsperiod i klientens attributcachen, vilket gör att åtgärder kan hämta filattribut från cacheminnet i stället för att hämta dem över kabeln. Detta kan minska svarstiden i situationer där cachelagrade attribut upphör att gälla medan åtgärden fortfarande körs.
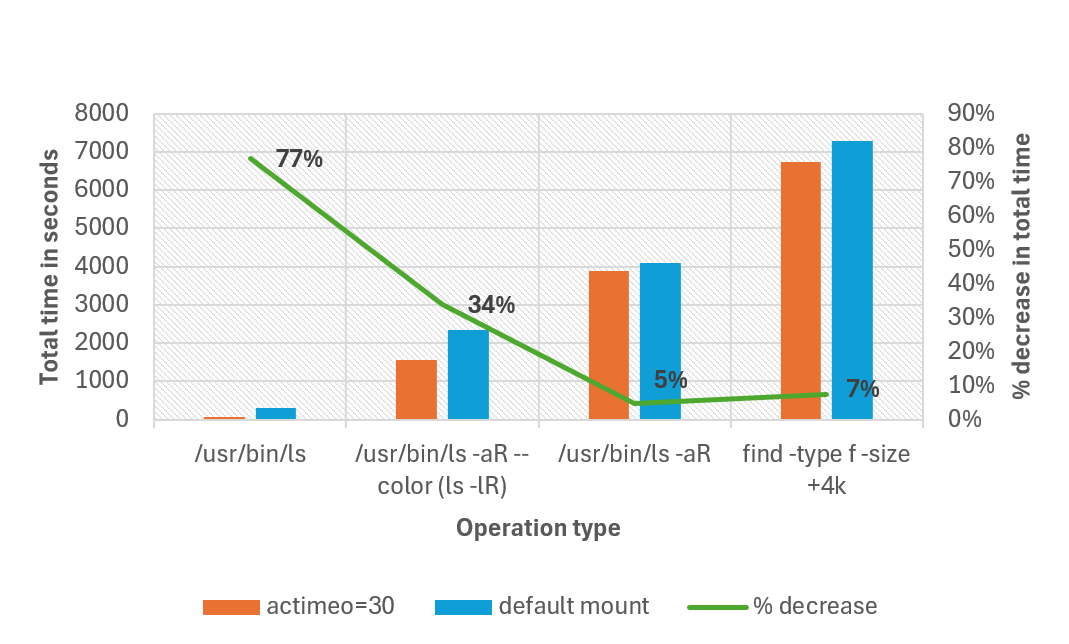
I följande diagram jämförs den totala tid det tar att slutföra olika åtgärder med standardmontering jämfört med att ange värdet actimeo 30 för en arbetsbelastning som har 1 miljon filer i en enda katalog. I vår testning minskade den totala slutförandetiden med så mycket som 77 % för vissa åtgärder. Alla operationer gjordes med otillfördelade ls.
nconnect
Nconnect är ett monteringsalternativ på klientsidan för NFS-filresurser som gör att du kan använda flera TCP-anslutningar mellan klienten och Azure Premium Files-tjänsten för NFSv4.1. Vi rekommenderar den optimala inställningen nconnect=4 för att minska svarstiden och förbättra prestandan.
Nconnect kan vara särskilt användbart för arbetsbelastningar som använder asynkron eller synkron I/O från flera trådar.
Läs mer.
Öka antalet hash-bucketar
Den totala mängden RAM-minne som finns i systemet som gör uppräkningen påverkar det interna arbetet med filsystemprotokoll som NFS och SMB. Även om användarna inte har hög minnesanvändning påverkar mängden tillgängligt minne antalet inode-hash-bucketar som systemet har, vilket påverkar/förbättrar uppräkningsprestanda för stora kataloger. Du kan ändra antalet inode-hash-bucketar som systemet har för att minska de hash-kollisioner som kan inträffa under stora uppräkningsarbetsbelastningar.
För att göra detta måste du ändra inställningarna för startkonfigurationen genom att ange ytterligare ett kernelkommando som börjar gälla under starten för att öka antalet inode-hash-bucketar. Följ dessa steg.
Redigera filen med hjälp av
/etc/default/gruben textredigerare.sudo vim /etc/default/grubLägg till följande text i
/etc/default/grub-filen. Det här kommandot skiljer 128 MB som inode-hashtabellstorlek, vilket ökar systemets minnesförbrukning med högst 128 MB.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Om
GRUB_CMDLINE_LINUXdet redan finns lägger du tillihash_entries=16777216avgränsat med ett blanksteg, så här:GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Om du vill tillämpa ändringarna kör du:
sudo update-grub2Starta om systemet:
sudo rebootKontrollera att ändringarna har träda i kraft när systemet startas om genom att kontrollera kommandona för kernel-cmdline:
cat /proc/cmdlineOm
ihash_entriesär synligt har systemet tillämpat inställningen och uppräkningsprestandan bör förbättras exponentiellt.Du kan också kontrollera dmesg-utdata för att se om kernel-cmdline tillämpades:
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Kommandon och åtgärder
Hur kommandon och åtgärder anges kan också påverka prestanda. Att visa alla filer i en stor katalog med kommandot ls är ett bra exempel.
Kommentar
Vissa åtgärder, till exempel rekursiva ls, findoch du behöver både filnamn och filattribut, så de kombinerar kataloguppräkningar (för att hämta posterna) med en statistik för varje post (för att hämta attributen). Vi föreslår att du använder ett högre värde för actimeo på monteringspunkter där du sannolikt kommer att köra sådana kommandon.
Använd otilldelade ls
I vissa Linux-distributioner anger gränssnittet automatiskt standardalternativ för ls kommandot, till exempel ls --color=auto. Detta ändrar hur ls fungerar över kabeln och lägger till fler åtgärder i körningen ls . För att undvika prestandaförsämring rekommenderar vi att du använder oaliaserade ls. Du kan göra detta på ett av tre sätt:
Ta bort aliaset med hjälp av kommandot
unalias ls. Det här är bara en tillfällig lösning för den aktuella sessionen.För en permanent ändring kan du redigera aliaset
lsi användarensbashrc/bash_aliasesfil. I Ubuntu redigerar du~/.bashrcför att ta bort aliaset förls.I stället för att anropa
lskan du anropa binärfilenlsdirekt, till exempel/usr/bin/ls. På så sätt kan du användalsutan några alternativ som kan finnas i aliaset. Du hittar platsen för binärfilen genom att köra kommandotwhich ls.
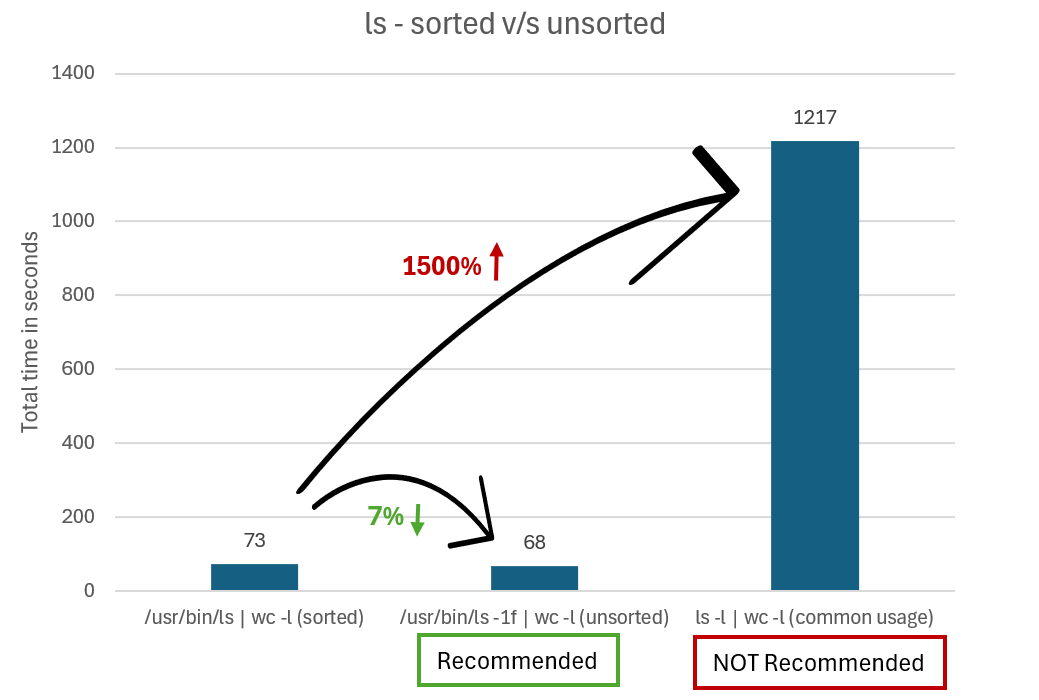
Förhindra att ls sorterar utdata
När du använder ls med andra kommandon kan du förbättra prestanda genom att förhindra att ls dess utdata sorteras i situationer där du inte bryr dig om den ordning som ls returnerar filerna. Sortering av utdata medför betydande omkostnader.
I stället för att köra ls -l | wc -l för att hämta det totala antalet filer kan du använda -f alternativen eller -U med ls för att förhindra att utdata sorteras. Skillnaden är att -f även dolda filer visas och -U inte visas.
Om du till exempel anropar ls binärfilen direkt i Ubuntu skulle du köra /usr/bin/ls -1f | wc -l eller /usr/bin/ls -1U | wc -l.
I följande diagram jämförs den tid det tar att mata ut resultat med osorterade, osorterade ls och sorterade ls.
Åtgärder för filkopiering och säkerhetskopiering
När du kopierar data från en filresurs eller säkerhetskopierar från filresurser till en annan plats rekommenderar vi att du använder en resursögonblicksbild som källa i stället för den aktiva filresursen med aktiv I/O. Säkerhetskopieringsprogram ska köra kommandon på ögonblicksbilden direkt. Mer information finns i Använda resursögonblicksbilder med Azure Files.
Rekommendationer på programnivå
Följ dessa rekommendationer när du utvecklar program som använder stora kataloger.
Hoppa över filattribut. Om programmet bara behöver filnamnet och inte filattribut som filtyp eller senast ändrad tid kan du använda flera anrop till systemanrop, till exempel
getdents64med en bra buffertstorlek. Då hämtas posterna i den angivna katalogen utan filtyp, vilket gör åtgärden snabbare genom att undvika extra åtgärder som inte behövs.Mellanlagringsstatistikanrop. Om programmet behöver attribut och filnamnet rekommenderar vi att du mellanlagrar stat-anropen tillsammans med
getdents64i stället för att hämta alla poster till slutet av filen medgetdents64och sedan göra en statx på alla poster som returneras. Genom att mellanlagrar stat-anropen instrueras klienten att begära både filen och dess attribut samtidigt, vilket minskar antalet anrop till servern. I kombination med ett högtactimeovärde kan detta avsevärt förbättra prestandan. I stället för[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ]placerar du till exempel statx-anropen efter följandegetdents64:[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ].Öka I/O-djup. Om möjligt föreslår vi att du konfigurerar
nconnecttill ett värde som inte är noll (större än 1) och distribuerar åtgärden mellan flera trådar eller använder asynkron I/O. Detta aktiverar åtgärder som kan vara asynkrona för att dra nytta av flera samtidiga anslutningar till filresursen.Cacheminne för framtvingad användning. Om programmet kör frågor mot filattributen på en filresurs som endast en klient har monterat använder du statx-systemanropet
AT_STATX_DONT_SYNCmed flaggan . Den här flaggan säkerställer att de cachelagrade attributen hämtas från cacheminnet utan att synkroniseras med servern, vilket undviker extra nätverksresor för att hämta de senaste data.