Självstudie: Implementera data lake capture-mönstret för att uppdatera en Databricks Delta-tabell
Den här självstudien visar hur du hanterar händelser i ett lagringskonto som har ett hierarkiskt namnområde.
Du skapar en liten lösning som gör att en användare kan fylla i en Databricks Delta-tabell genom att ladda upp en fil med kommaavgränsade värden (csv) som beskriver en försäljningsorder. Du skapar den här lösningen genom att ansluta en Event Grid-prenumeration, en Azure-funktion och ett jobb i Azure Databricks.
I den här självstudien kommer vi att:
- Skapa en Event Grid-prenumeration som anropar en Azure-funktion.
- Skapa en Azure-funktion som tar emot ett meddelande från en händelse och kör sedan jobbet i Azure Databricks.
- Skapa ett Databricks-jobb som infogar en kundorder i en Databricks Delta-tabell som finns i lagringskontot.
Vi skapar den här lösningen i omvänd ordning och börjar med Azure Databricks-arbetsytan.
Förutsättningar
Skapa ett lagringskonto som har ett hierarkiskt namnområde (Azure Data Lake Storage). I den här självstudien används ett lagringskonto med namnet
contosoorders.Se Skapa ett lagringskonto som ska användas med Azure Data Lake Storage.
Se till att ditt användarkonto har tilldelats rollen Storage Blob Data-deltagare.
Skapa ett huvudnamn för tjänsten, skapa en klienthemlighet och ge sedan tjänstens huvudnamn åtkomst till lagringskontot.
Se Självstudie: Ansluta till Azure Data Lake Storage (steg 1 till och med 3). När du har slutfört de här stegen måste du klistra in klientorganisations-ID, app-ID och klienthemlighetsvärden i en textfil. Du kommer att behöva dem snart.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Skapa en försäljningsorder
Skapa först en csv-fil som beskriver en försäljningsorder och ladda sedan upp filen till lagringskontot. Senare använder du data från den här filen för att fylla i den första raden i vår Databricks Delta-tabell.
Navigera till ditt nya lagringskonto i Azure Portal.
Välj Storage browser-Blob> containers-Add> container och skapa en ny container med namnet data.
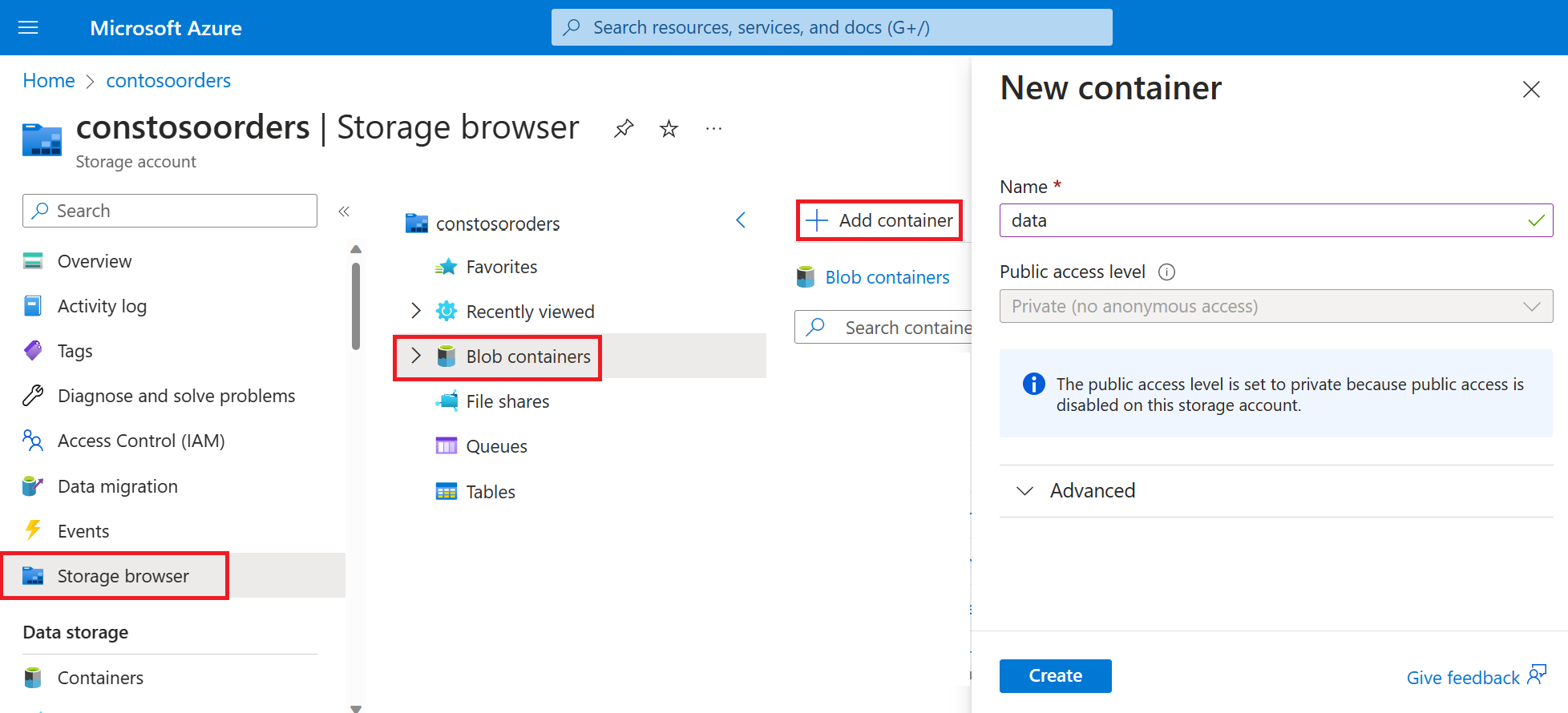
Skapa en katalog med namnet input i datacontainern.
Klistra in följande text i en textredigerare.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomSpara filen på den lokala datorn och ge den namnet data.csv.
Ladda upp filen till indatamappen i lagringswebbläsaren.
Skapa ett jobb i Azure Databricks
I det här avsnittet utför du följande uppgifter:
- Skapa en Azure Databricks-arbetsyta.
- Skapa en anteckningsbok.
- Skapa och fylla i en Databricks Delta-tabell.
- Lägg till kod som infogar rader i tabellen Databricks Delta.
- Skapa ett jobb.
Skapa en Azure Databricks-arbetsyta
I det här avsnittet skapar du en Azure Databricks-arbetsyta med Azure-portalen.
Skapa en Azure Databricks-arbetsyta. Ge arbetsytan
contoso-ordersnamnet . Se Skapa en Azure Databricks-arbetsyta.Skapa ett kluster. Ge klustret
customer-order-clusternamnet . Se Skapa ett kluster.Skapa en anteckningsbok. Namnge anteckningsboken
configure-customer-tableoch välj Python som standardspråk för notebook-filen. Se Skapa en notebook-fil.
Skapa och fylla i en Databricks Delta-tabell
I anteckningsboken som du skapade kopierar och klistrar du in följande kodblock i den första cellen, men kör inte den här koden ännu.
appIdErsätt platshållarvärdena ,passwordtenanti det här kodblocket med de värden som du samlade in när du slutförde förutsättningarna för den här självstudien.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Den här koden skapar en widget med namnet source_file. Senare skapar du en Azure-funktion som anropar den här koden och skickar en filsökväg till widgeten. Den här koden autentiserar även tjänstens huvudnamn med lagringskontot och skapar några variabler som du ska använda i andra celler.
Kommentar
I en produktionsinställning bör du överväga att lagra din autentiseringsnyckel i Azure Databricks. Sedan lägger du till en lookup-nyckel i kodblocket i stället för autentiseringsnyckeln.
I stället för att till exempel använda den här kodraden:spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>")använder du följande kodrad:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
När du har slutfört den här självstudien kan du läsa artikeln om Azure Data Lake Storage på Webbplatsen för Azure Databricks för att se exempel på den här metoden.Tryck på SKIFT + RETUR för att köra koden i det här blocket.
Kopiera och klistra in följande kodblock i en annan cell och tryck sedan på SKIFT + RETUR-tangenterna för att köra koden i det här blocket.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Den här koden skapar tabellen Databricks Delta i ditt lagringskonto och läser sedan in några initiala data från csv-filen som du laddade upp tidigare.
När det här kodblocket har körts tar du bort det här kodblocket från notebook-filen.
Lägg till kod som infogar rader i tabellen Databricks Delta
Kopiera och klistra in följande kodblock i en annan cell, men kör inte den här cellen.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Den här koden infogar data i en tillfällig tabellvy med hjälp av data från en csv-fil. Sökvägen till csv-filen kommer från den indatawidget som du skapade i ett tidigare steg.
Kopiera och klistra in följande kodblock i en annan cell. Den här koden sammanfogar innehållet i den tillfälliga tabellvyn med tabellen Databricks Delta.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Skapa ett jobb
Skapa ett jobb som kör anteckningsboken som du skapade tidigare. Senare skapar du en Azure-funktion som kör det här jobbet när en händelse aktiveras.
Välj Nytt> jobb.
Ge jobbet ett namn, välj den notebook-fil som du skapade och klustret. Välj sedan Skapa för att skapa jobbet.
Skapa en Azure-funktion
Skapa en Azure-funktion som kör jobbet.
I din Azure Databricks-arbetsyta klickar du på ditt Användarnamn för Azure Databricks i det övre fältet och väljer sedan Användarinställningar i listrutan.
På fliken Åtkomsttoken väljer du Generera ny token.
Kopiera token som visas och klicka sedan på Klar.
I det övre hörnet av Databricks-arbetsytan väljer du personikonen och väljer sedan Användarinställningar.

Välj knappen Generera ny token och välj sedan knappen Generera.
Se till att kopiera token till en säker plats. Din Azure-funktion behöver den här token för att autentisera med Databricks så att den kan köra jobbet.
I menyn i Azure-portalen eller på sidan Start väljer du Skapa en resurs.
På sidan Nytt väljer du Beräkningsfunktionsapp>.
På fliken Grundinställningar på sidan Skapa funktionsapp väljer du en resursgrupp och ändrar eller verifierar sedan följande inställningar:
Inställning Värde Funktionsappens namn contosoorder CLR-stack .NET Publicera Kod Operativsystem Windows Abonnemangstyp Förbrukning (serverlös) Välj Granska + skapa och välj sedan Skapa.
När distributionen är klar väljer du Gå till resurs för att öppna översiktssidan för funktionsappen.
I gruppen Inställningar väljer du Konfiguration.
På sidan Programinställningar väljer du knappen Ny programinställning för att lägga till varje inställning.

Lägg till följande inställningar:
Inställningsnamn Värde DBX_INSTANCE Regionen för din databricks-arbetsyta. Till exempel: westus2.azuredatabricks.netDBX_PAT Den personliga åtkomsttoken som du genererade tidigare. DBX_JOB_ID Identifieraren för det jobb som körs. Välj Spara för att checka in de här inställningarna.
I gruppen Funktioner väljer du Funktioner och sedan Skapa.
Välj Azure Event Grid-utlösare.
Installera tillägget Microsoft.Azure.WebJobs.Extensions.EventGrid om du uppmanas att göra det. Om du måste installera den måste du välja Azure Event Grid-utlösare igen för att skapa funktionen.
Fönstret Ny funktion visas.
I fönstret Ny funktion ger du funktionen namnet UpsertOrder och väljer sedan knappen Skapa .
Ersätt innehållet i kodfilen med den här koden och välj sedan knappen Spara :
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Den här koden parsar information om lagringshändelsen som skapades och skapar sedan ett begärandemeddelande med URL:en för filen som utlöste händelsen. Som en del av meddelandet skickar funktionen ett värde till den source_file widget som du skapade tidigare. Funktionskoden skickar meddelandet till Databricks-jobbet och använder den token som du fick tidigare som autentisering.
Skapa en Event Grid-prenumeration
I det här avsnittet skapar du en Event Grid-prenumeration som anropar Azure-funktionen när filer laddas upp till lagringskontot.
Välj Integrering och välj sedan Händelserutnätsutlösare på sidan Integrering.
I fönstret Redigera utlösare namnger du händelsen
eventGridEventoch väljer sedan Skapa händelseprenumeration.Kommentar
Namnet
eventGridEventmatchar parametern med namnet som skickas till Azure-funktionen.På fliken Grundläggande inställningar på sidan Skapa händelseprenumeration ändrar eller verifierar du följande inställningar:
Inställning Värde Name contoso-order-event-subscription Ämnestyp Lagringskonto Källresurs contosoorders Systemämnesnamn <create any name>Filtrera till händelsetyper Bloben har skapats och bloben har tagits bort Markera knappen Skapa.
Testa Event Grid-prenumerationen
Skapa en fil med namnet
customer-order.csv, klistra in följande information i filen och spara den på den lokala datorn.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneI Storage Explorer laddar du upp den här filen till indatamappen för ditt lagringskonto.
När du laddar upp en fil genereras händelsen Microsoft.Storage.BlobCreated . Event Grid meddelar alla prenumeranter på händelsen. I vårt fall är Azure-funktionen den enda prenumeranten. Azure-funktionen parsar händelseparametrarna för att avgöra vilken händelse som inträffade. Sedan skickas url:en för filen till Databricks-jobbet. Databricks-jobbet läser filen och lägger till en rad i tabellen Databricks Delta som finns på ditt lagringskonto.
Om du vill kontrollera om jobbet lyckades kan du visa körningarna för jobbet. Du ser en slutförandestatus. Mer information om hur du visar körningar för ett jobb finns i Visa körningar för ett jobb
I en ny arbetsbokscell kör du den här frågan i en cell för att se den uppdaterade deltatabellen.
%sql select * from customer_dataDen returnerade tabellen visar den senaste posten.

Om du vill uppdatera den här posten skapar du en fil med namnet
customer-order-update.csv, klistrar in följande information i filen och sparar den på den lokala datorn.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneDen här csv-filen är nästan identisk med den tidigare, förutom att orderkvantiteten ändras från
228till22.I Storage Explorer laddar du upp den här filen till indatamappen för ditt lagringskonto.
Kör frågan
selectigen för att se den uppdaterade deltatabellen.%sql select * from customer_dataDen returnerade tabellen visar den uppdaterade posten.

Rensa resurser
Ta bort resursgruppen och alla relaterade resurser när de inte längre behövs. Det gör du genom att välja resursgruppen för lagringskontot och sedan Ta bort.