Uppgradera och uppdatera Azure Service Fabric-kluster
Ett Azure Service Fabric-kluster är en resurs som du äger, men det hanteras delvis av Microsoft. Den här artikeln beskriver alternativen för när och hur du uppdaterar ditt Azure Service Fabric-kluster.
Automatiska och manuella uppgraderingar
Det är viktigt att se till att Service Fabric-klustret alltid kör en körningsversion som stöds. Varje gång Microsoft tillkännager lanseringen av en ny version av Service Fabric markeras den tidigare versionen för supportens slut efter minst 60 dagar från det datumet. Nya versioner tillkännages på Service Fabric-teamets blogg.
Fjorton dagar innan frisläppningen som klustret körs genereras en hälsohändelse som försätter klustret i ett varningstillstånd . Klustret är fortfarande i ett varningstillstånd tills du uppgraderar till en körningsversion som stöds.
Du kan ange att klustret ska ta emot automatiska Service Fabric-uppgraderingar när de släpps av Microsoft, eller så kan du manuellt välja från en lista över versioner som stöds för närvarande. De här alternativen är tillgängliga i avsnittet Infrastrukturuppgraderingar i din Service Fabric-klusterresurs.
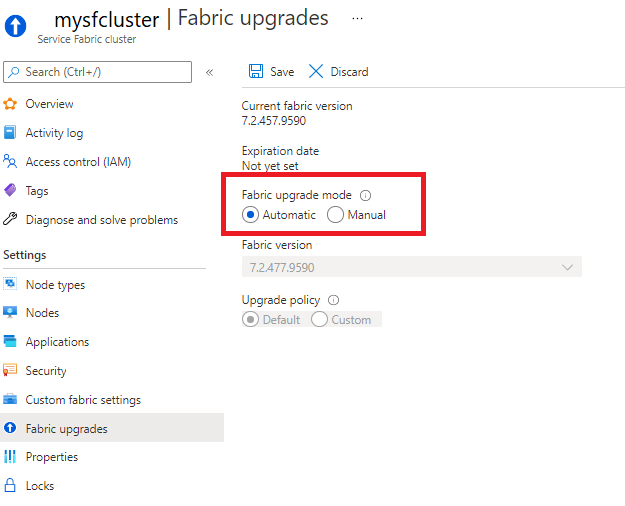
Du kan också ange läget för klusteruppgradering och välja en körningsversion med hjälp av en Resource Manager-mall.
Automatiska uppgraderingar är det rekommenderade uppgraderingsläget, eftersom det här alternativet säkerställer att klustret förblir i ett tillstånd som stöds och drar nytta av de senaste korrigeringarna och funktionerna samtidigt som du kan schemalägga uppdateringar på ett sätt som är minst störande för dina arbetsbelastningar med hjälp av en strategi för vågdistribution .
Kommentar
Om du ändrar ett befintligt kluster till automatiskt läge registreras klustret för nästa uppgraderingsperiod som börjar med en ny version. Nya versioner tillkännages på Service Fabric-teamets blogg. Den högsta möjliga uppgraderingssökvägen väljs per uppgraderingsperiod. Se versioner som stöds. Det manuella uppgraderingsläget utlöser en omedelbar uppgradering.
Vågdistribution för automatiska uppgraderingar
Med vågdistribution kan du minimera avbrotten i en uppgradering till klustret genom att välja mognadsnivån för en uppgradering, beroende på din arbetsbelastning. Du kan till exempel konfigurera en distributionspipeline för Test ->Stage ->Production wave för dina olika Service Fabric-kluster för att testa kompatibiliteten för en körningsuppgradering innan du tillämpar den på dina produktionsarbetsbelastningar.
Om du vill välja vågdistribution anger du något av följande vågvärden för klustret (i dess distributionsmall):
- Våg 0: Kluster uppdateras så snart en ny Service Fabric-version släpps. Avsedd för test-/utvecklingskluster.
- Våg 1: Kluster uppdateras en vecka (sju dagar) efter att en ny version har släppts. Avsedd för för-prod/mellanlagringskluster.
- Våg 2: Kluster uppdateras två veckor (14 dagar) efter att en ny version har släppts. Avsedd för produktionskluster.
Du kan registrera dig för e-postaviseringar med länkar för att ytterligare hjälpa till om en klusteruppgradering misslyckas. Se Wave-distribution för automatiska uppgraderingar för att komma igång.
Faser för automatisk uppgradering
Microsoft underhåller Service Fabric-körningskoden och konfigurationen som körs i ett Azure-kluster. Vi utför automatiskt övervakade uppgraderingar av programvaran efter behov. Dessa uppgraderingar kan vara kod, konfiguration eller båda. För att minimera effekten av dessa uppgraderingar på dina program utförs de i följande faser:
Fas 1: En uppgradering utförs med hjälp av alla hälsoprinciper för kluster
Under den här fasen fortsätter uppgraderingarna en uppgraderingsdomän i taget, och de program som kördes i klustret fortsätter att köras utan avbrott. Klustrets hälsoprinciper (för nodhälsa och programhälsa) följs under uppgraderingen.
Om klustrets hälsoprinciper inte uppfylls återställs uppgraderingen och ett e-postmeddelande skickas till prenumerationens ägare. E-postmeddelandet innehåller följande information:
- Meddelande om att vi var tvungna att återställa en klusteruppgradering.
- Eventuella föreslagna åtgärder.
- Antalet dagar (n) tills vi kör fas 2.
Vi försöker köra samma uppgradering några gånger till om uppgraderingen misslyckas av infrastrukturskäl. Efter de n dagarna från det datum då e-postmeddelandet skickades fortsätter vi till fas 2.
Om klustrets hälsoprinciper uppfylls anses uppgraderingen vara slutförd och markerad som slutförd. Den här situationen kan inträffa under den första uppgraderingen eller någon av uppgraderingskörningarna i den här fasen. Det finns ingen e-postbekräftelse för en lyckad körning, för att undvika att skicka onödiga e-postmeddelanden. Att ta emot ett e-postmeddelande anger ett undantag från normala åtgärder. Vi förväntar oss att de flesta klusteruppgraderingar lyckas utan att påverka programmets tillgänglighet.
Fas 2: En uppgradering utförs endast med hjälp av standardhälsoprinciper
Hälsoprinciperna i den här fasen anges på ett sådant sätt att antalet program som var felfria i början av uppgraderingen förblir detsamma under uppgraderingsprocessen. Precis som i fas 1 fortsätter fas 2-uppgraderingarna en uppgraderingsdomän i taget, och de program som kördes i klustret fortsätter att köras utan avbrott. Klustrets hälsoprinciper (en kombination av nodhälsa och hälsotillståndet för alla program som körs i klustret) följs under uppgraderingen.
Om de gällande principerna för klusterhälsa inte uppfylls återställs uppgraderingen. Sedan skickas ett e-postmeddelande till prenumerationens ägare. E-postmeddelandet innehåller följande information:
- Meddelande om att vi var tvungna att återställa en klusteruppgradering.
- Eventuella föreslagna åtgärder.
- Antalet dagar (n) tills vi kör fas 3.
Vi försöker köra samma uppgradering några gånger till om uppgraderingen misslyckas av infrastrukturskäl. Ett påminnelsemeddelande skickas ett par dagar innan n dagar är slut. Efter de n dagarna från det datum då e-postmeddelandet skickades fortsätter vi till fas 3. De e-postmeddelanden som vi skickar dig i fas 2 måste tas på allvar och åtgärder måste vidtas.
Om klustrets hälsoprinciper uppfylls anses uppgraderingen vara slutförd och markerad som slutförd. Detta kan inträffa under den första uppgraderingen eller någon av uppgraderingens omkörningar i den här fasen. Det finns ingen e-postbekräftelse för en lyckad körning.
Fas 3: En uppgradering utförs med hjälp av aggressiva hälsoprinciper
Dessa hälsoprinciper i den här fasen är inriktade på att slutföra uppgraderingen i stället för programmens hälsotillstånd. Få klusteruppgraderingar hamnar i den här fasen. Om klustret kommer till den här fasen finns det en god chans att programmet blir felfritt och/eller förlorar tillgängligheten.
På samma sätt som de andra två faserna fortsätter fas 3-uppgraderingarna en uppgraderingsdomän i taget.
Om klustrets hälsoprinciper inte uppfylls återställs uppgraderingen. Vi försöker köra samma uppgradering några gånger till om uppgraderingen misslyckas av infrastrukturskäl. Därefter fästs klustret så att det inte längre får support och/eller uppgraderingar.
Ett e-postmeddelande med den här informationen skickas till prenumerationsägaren, tillsammans med reparationsåtgärderna. Vi förväntar oss inte att några kluster hamnar i ett tillstånd där fas 3 har misslyckats.
Om klustrets hälsoprinciper uppfylls anses uppgraderingen vara slutförd och markerad som slutförd. Detta kan inträffa under den första uppgraderingen eller någon av uppgraderingens omkörningar i den här fasen. Det finns ingen e-postbekräftelse för en lyckad körning.
Anpassade principer för manuella uppgraderingar
Du kan ange anpassade principer för manuella klusteruppgraderingar. Dessa principer tillämpas varje gång du väljer en ny körningsversion, vilket utlöser systemet för att starta uppgraderingen av klustret. Om du inte åsidosätter principerna används standardvärdena. Mer information finns i Ange anpassade principer för manuella uppgraderingar.
Andra klusteruppdateringar
Förutom att uppgradera körningen finns det ett antal andra åtgärder som du kan behöva utföra för att hålla klustret uppdaterat, inklusive följande:
Hantera certifikat
Service Fabric använder X.509-servercertifikat som du anger när du skapar ett kluster för att skydda kommunikationen mellan klusternoder och autentisera klienter. Du kan lägga till, uppdatera eller ta bort certifikat för klustret och klienten i Azure Portal eller använda PowerShell/Azure CLI. Mer information finns i Lägga till eller ta bort certifikat
Öppna programportar
Du kan ändra programportar genom att ändra egenskaperna för Load Balancer-resursen som är associerade med nodtypen. Du kan använda Azure Portal eller använda PowerShell/Azure CLI. Mer information finns i Öppna programportar för ett kluster.
Definiera nodegenskaper
Ibland kanske du vill se till att vissa arbetsbelastningar endast körs på vissa typer av noder i klustret. Vissa arbetsbelastningar kan till exempel kräva GPU:er eller SSD medan andra kanske inte gör det. För var och en av nodtyperna i ett kluster kan du lägga till anpassade nodegenskaper i klusternoder. Placeringsbegränsningar är de instruktioner som är kopplade till enskilda tjänster som väljer för en eller flera nodegenskaper. Placeringsbegränsningar definierar var tjänsterna ska köras.
Mer information om hur du använder placeringsbegränsningar, nodegenskaper och hur du definierar dem finns i nodegenskaper och placeringsbegränsningar.
Lägga till kapacitetsmått
För var och en av nodtyperna kan du lägga till anpassade kapacitetsmått som du vill använda i dina program för att rapportera inläsning. Mer information om hur du använder kapacitetsmått för att rapportera inläsning finns i Service Fabric Cluster Resource Manager-dokument om att beskriva ditt kluster och mått och belastning.
Anpassa inställningar för klustret
Många olika konfigurationsinställningar kan anpassas i ett kluster, till exempel tillförlitlighetsnivån för kluster- och nodegenskaperna. Mer information finns i Infrastrukturinställningar för Service Fabric-kluster.
Kommentar
För kluster som använder körningsversioner före 10.0CU6, 10.1CU5 och 9.1CU12, om du har ändrat eller planerar att ändra NTLM-inställningar för FileStoreService, kan du förvänta dig viss stilleståndstid när klustrets noder startas om. Den här omstarten är kopplad till rensning som sker under uppgraderingscykeln.
Det här beteendet ändras från och med 10.0CU6, 10.1CU5 och 9.1CU12, och inga omstarter av noder ska ske på kluster som kör dessa versioner eller senare.
Mer information om Service Fabric-versionshantering finns på sidan versioner.
Uppgradera OS-avbildningar för klusternoder
Det är bästa praxis att aktivera automatiska uppgraderingar av operativsystemavbildningar för dina Service Fabric-klusternoder. För att göra det finns det flera klusterkrav och åtgärder att vidta. Ett annat alternativ är att använda Patch Orchestration Application (POA), ett Service Fabric-program som automatiserar operativsystemets korrigering på ett Service Fabric-kluster utan driftstopp. Mer information om de här alternativen finns i Korrigera Windows-operativsystemet i Service Fabric-klustret.