Felsöka och identifiera långsamma frågor i Azure Database for PostgreSQL – flexibel server
GÄLLER FÖR:  Azure Database for PostgreSQL – flexibel server
Azure Database for PostgreSQL – flexibel server
Den här artikeln beskriver hur du identifierar och diagnostiserar rotorsaken till långsamma frågor.
I den här artikeln kan du lära dig:
- Så här identifierar du långsamma frågor.
- Så här identifierar du en långsam procedur tillsammans med den. Identifiera en långsam fråga i en lista med frågor som tillhör samma långsamma lagrade procedur.
Förutsättningar
Aktivera felsökningsguider genom att följa stegen som beskrivs i felsökningsguiderna för användning.
auto_explainKonfigurera tillägget genom att tillåtalistning och läsa in tillägget.auto_explainNär tillägget har konfigurerats ändrar du följande serverparametrar som styr beteendet för tillägget:auto_explain.log_analyzetillON.auto_explain.log_bufferstillON.auto_explain.log_min_durationenligt vad som är rimligt i ditt scenario.auto_explain.log_timingtillON.auto_explain.log_verbosetillON.
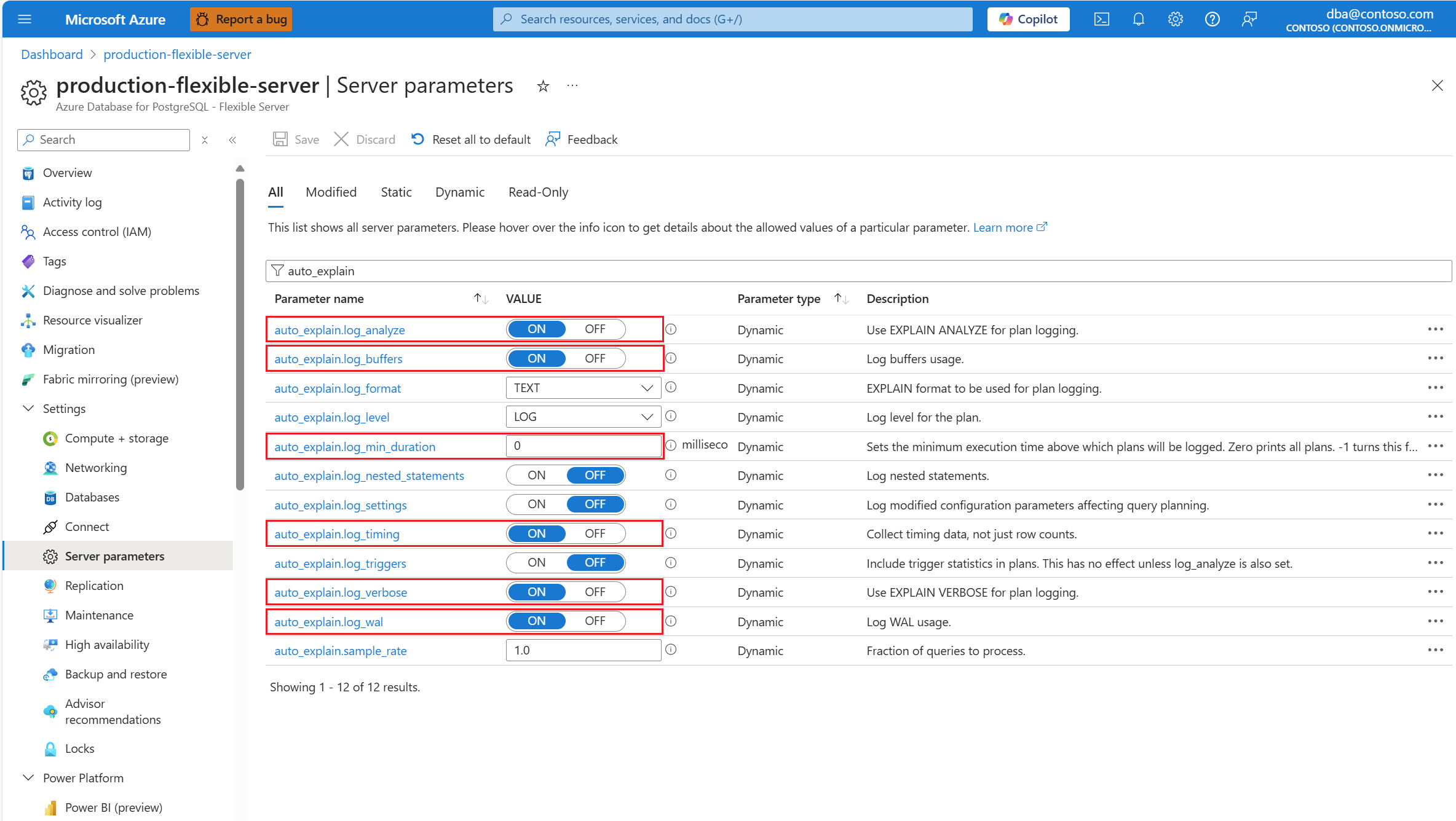

Kommentar
Om du anger auto_explain.log_min_duration till 0 börjar tillägget logga alla frågor som körs på servern. Detta kan påverka databasens prestanda. Korrekt due diligence måste göras för att komma till ett värde som anses vara långsamt på servern. Om till exempel alla frågor slutförs på mindre än 30 sekunder och det är acceptabelt för ditt program rekommenderar vi att du uppdaterar parametern till 3 000 millisekunder. Då loggas alla frågor som tar längre tid än 30 sekunder att slutföra.
Identifiera långsam fråga
Med felsökningsguider och auto_explain tillägg på plats beskriver vi scenariot med hjälp av ett exempel.
Vi har ett scenario där processoranvändningen ökar till 90 % och vill fastställa orsaken till topparna. Följ dessa steg för att felsöka scenariot:
Så snart du får aviseringar om ett CPU-scenario går du till resursmenyn för den berörda instansen av Azure Database for PostgreSQL – flexibel server. Under avsnittet Övervakning väljer du Felsökningsguider.
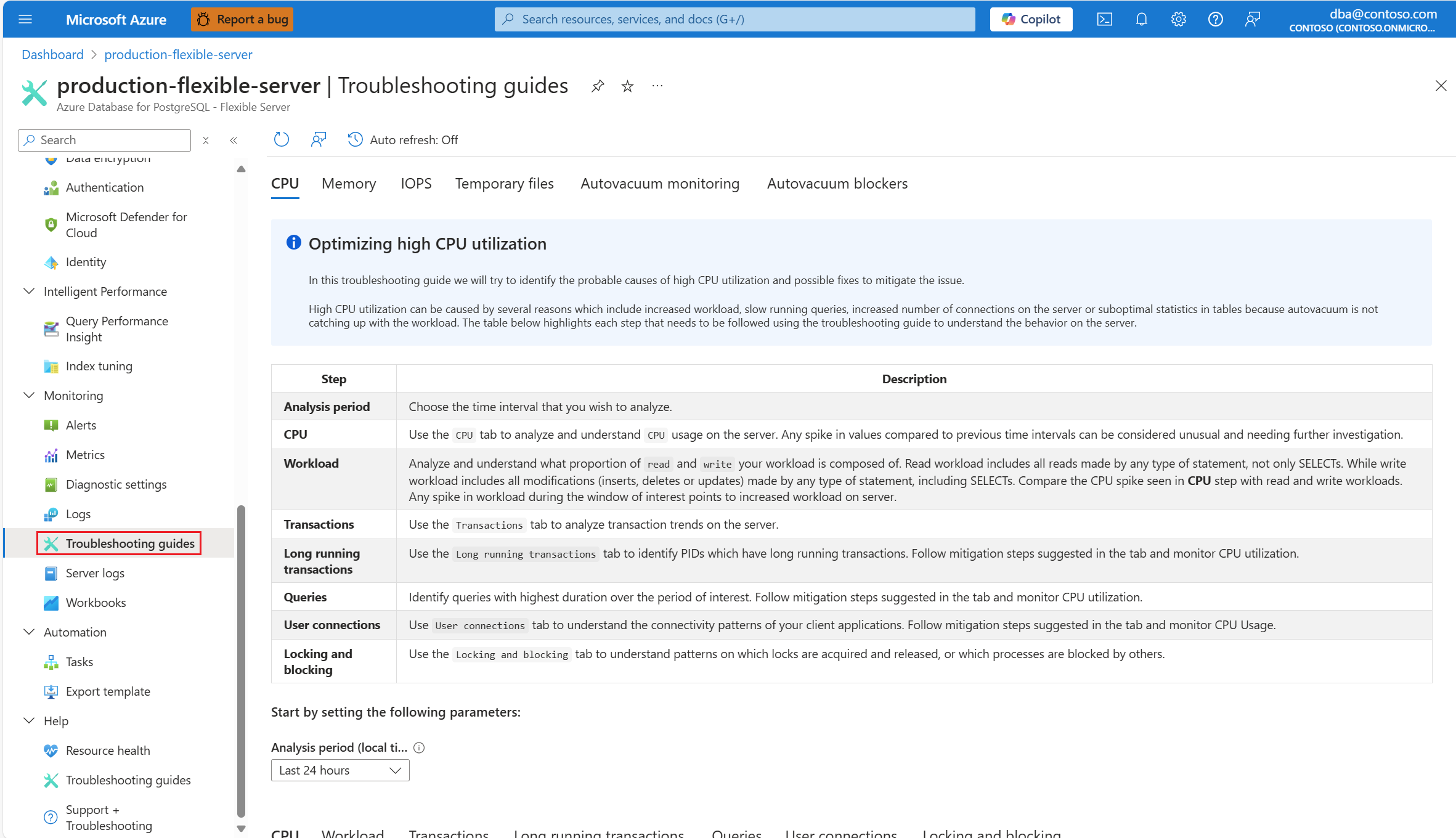
Välj fliken CPU . Felsökningsguiden Optimera hög CPU-användning öppnas.
I listrutan Analysperiod (lokal tid) väljer du det tidsintervall som du vill fokusera analysen på.
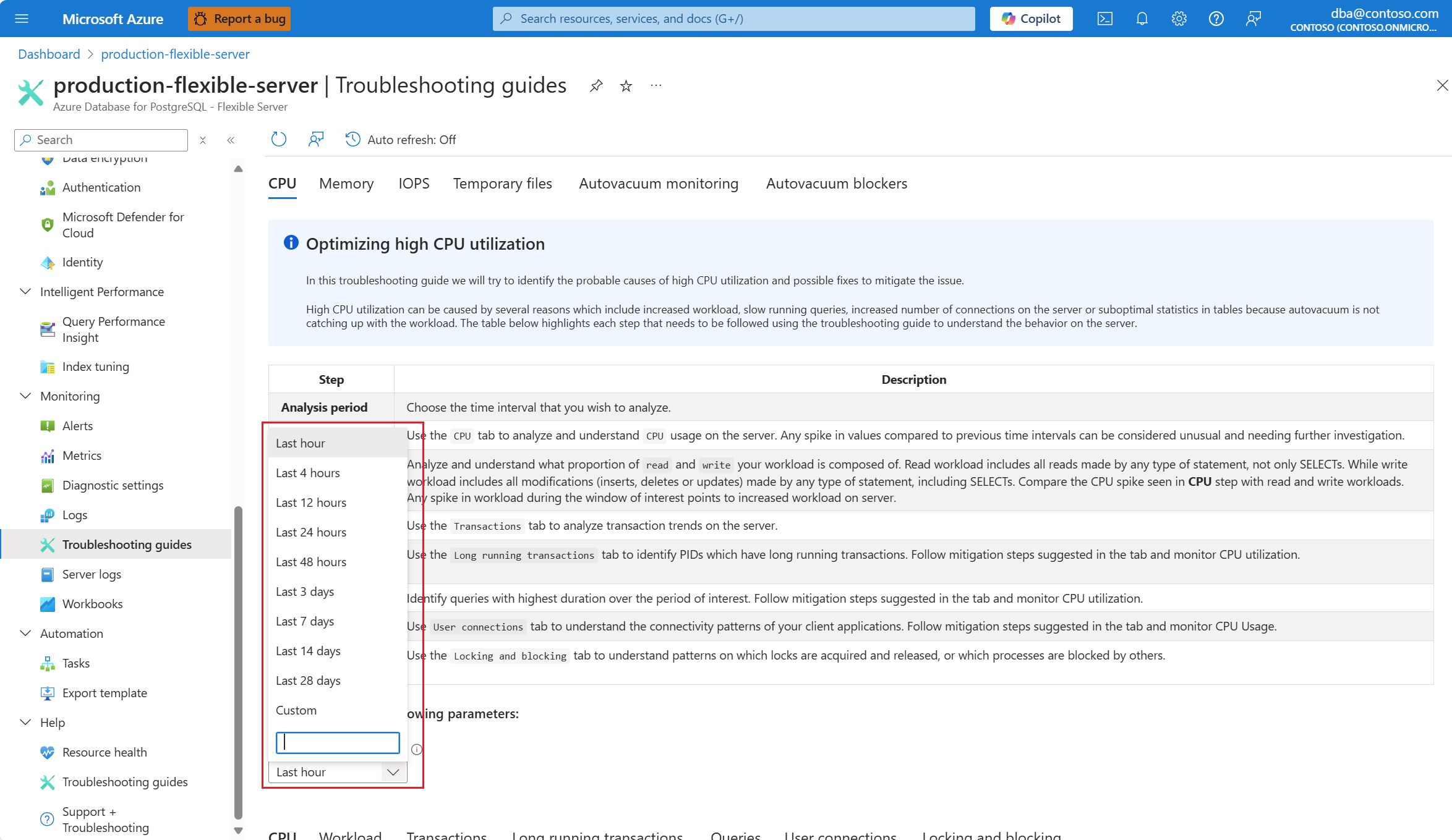
Välj fliken Frågor . Den visar information om alla frågor som kördes i intervallet där 90 % CPU-användning sågs. Från ögonblicksbilden ser det ut som att frågan med den långsammaste genomsnittliga körningstiden under tidsintervallet var ~2,6 minuter och frågan kördes 22 gånger under intervallet. Den frågan är troligen orsaken till cpu-toppar.
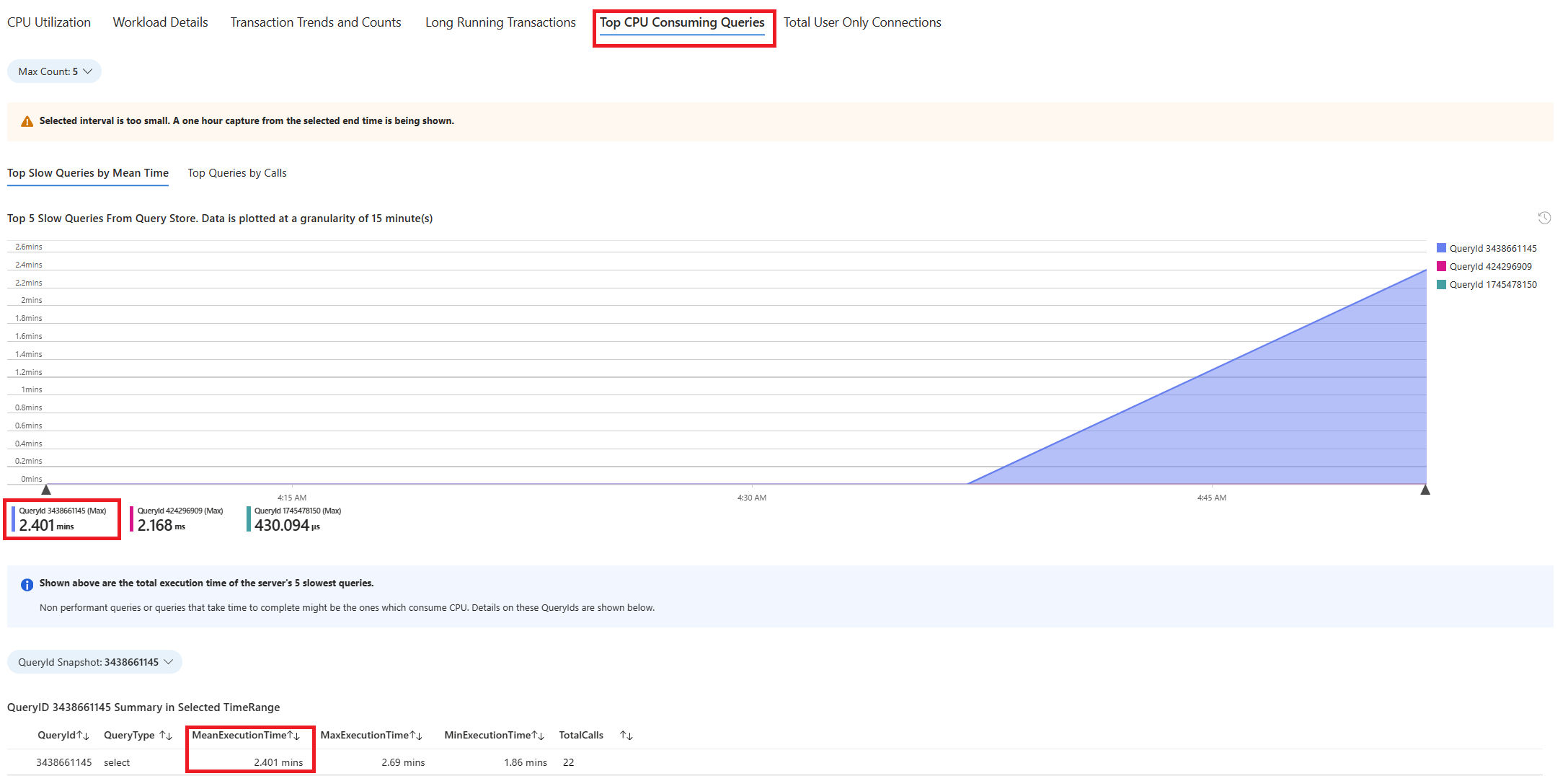
Om du vill hämta den faktiska frågetexten ansluter du
azure_systill databasen och kör följande fråga.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- I det aktuella exemplet var frågan som hittades långsam:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Om du vill förstå exakt vilken förklaringsplan som genererades använder du Azure Database for PostgreSQL – flexibel serverloggar. Varje gång frågan slutförde körningen under den tidsperioden
auto_explainska tillägget skriva en post i loggarna. I resursmenyn går du till avsnittet Övervakning och väljer Loggar.
Välj det tidsintervall där 90 % cpu-användning hittades.
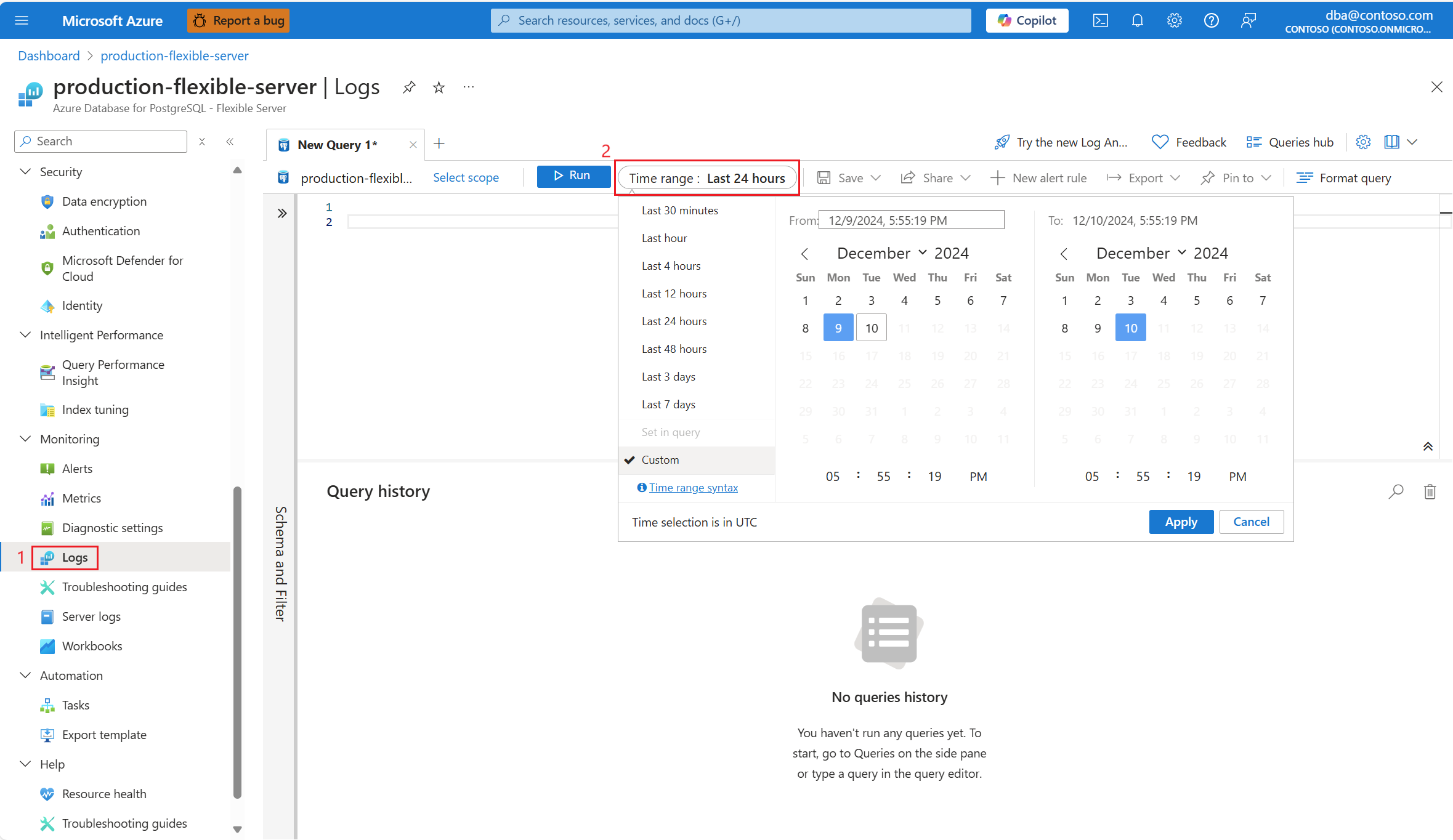
Kör följande fråga för att hämta utdata från EXPLAIN ANALYZE för den identifierade frågan.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
Meddelandekolumnen lagrar körningsplanen enligt följande utdata:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Frågan kördes i ~2,5 minuter, enligt felsökningsguiden. Värdet duration 150692,864 ms från körningsplanens utdata som hämtats bekräftar det. Använd utdata från EXPLAIN ANALYZE för att felsöka ytterligare och finjustera frågan.
Kommentar
Observera att frågan kördes 22 gånger under intervallet och att loggarna som visas innehåller en av de poster som registrerats under intervallet.
Identifiera långsamma frågor i en lagrad procedur
Med felsökningsguider och auto_explain tillägg på plats förklarar vi scenariot med hjälp av ett exempel.
Vi har ett scenario där processoranvändningen ökar till 90 % och vill fastställa orsaken till topparna. Följ dessa steg för att felsöka scenariot:
Så snart du får aviseringar om ett CPU-scenario går du till resursmenyn för den berörda instansen av Azure Database for PostgreSQL – flexibel server. Under avsnittet Övervakning väljer du Felsökningsguider.
Välj fliken CPU . Felsökningsguiden Optimera hög CPU-användning öppnas.
I listrutan Analysperiod (lokal tid) väljer du det tidsintervall som du vill fokusera analysen på.
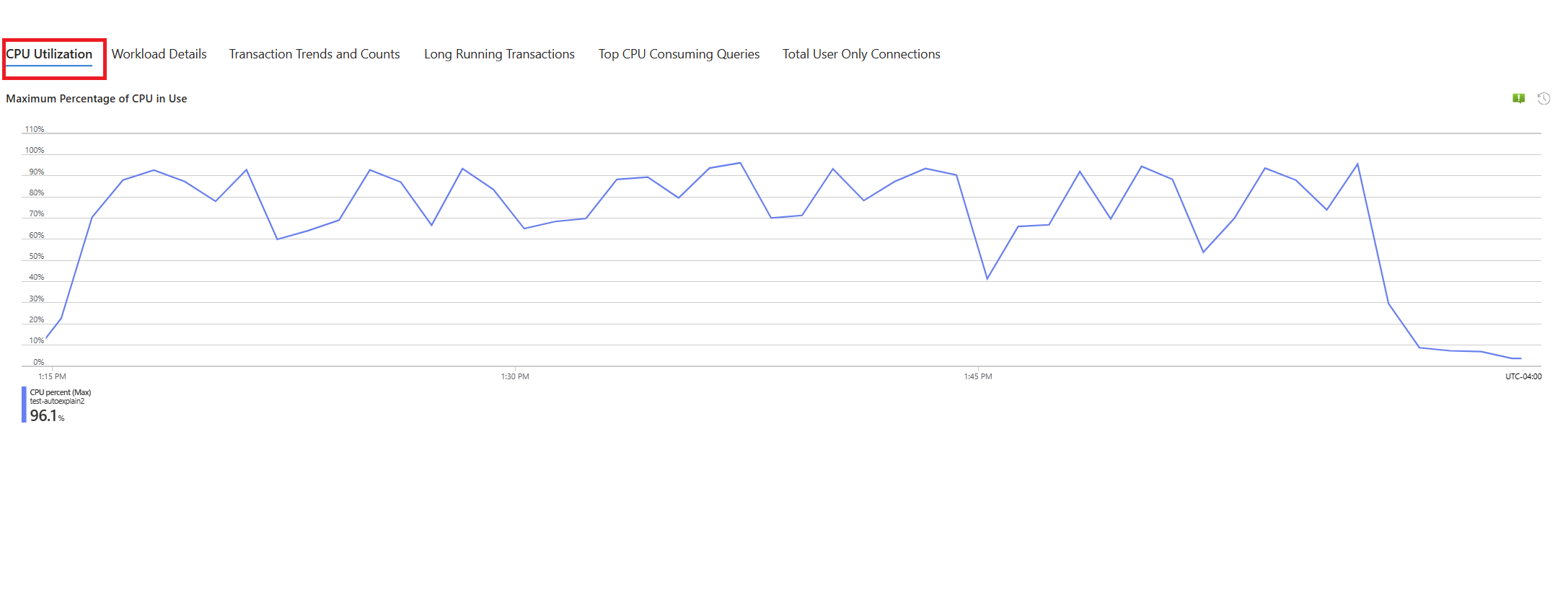
Välj fliken Frågor . Den visar information om alla frågor som kördes i intervallet där 90 % CPU-användning sågs. Från ögonblicksbilden ser det ut som att frågan med den långsammaste genomsnittliga körningstiden under tidsintervallet var ~2,6 minuter och frågan kördes 22 gånger under intervallet. Den frågan är troligen orsaken till cpu-toppar.
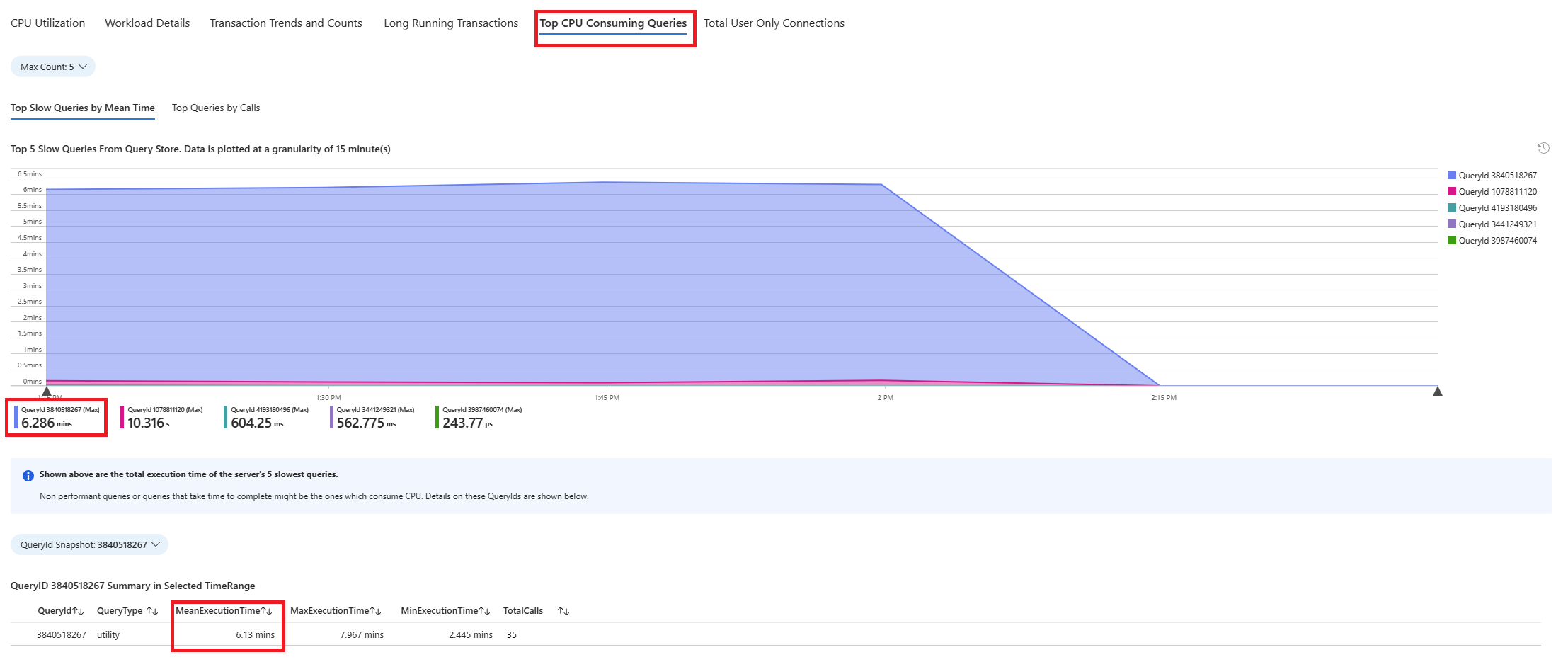
Anslut till azure_sys databas och kör frågan för att hämta faktisk frågetext med hjälp av skriptet nedan.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- I det aktuella exemplet var frågan som hittades långsam en lagrad procedur:
call autoexplain_test ();
- Om du vill förstå exakt vilken förklaringsplan som genererades använder du Azure Database for PostgreSQL – flexibel serverloggar. Varje gång frågan slutförde körningen under den tidsperioden
auto_explainska tillägget skriva en post i loggarna. I resursmenyn går du till avsnittet Övervakning och väljer Loggar. I Tidsintervall väljer du sedan det tidsfönster där du vill fokusera analysen.

- Kör följande fråga för att hämta förklara analysera utdata för den identifierade frågan.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
Proceduren har flera frågor som är markerade nedan. Förklara analysera utdata för varje fråga som används i den lagrade proceduren loggas in för att analysera ytterligare och felsöka. Körningstiden för de frågor som loggas kan användas för att identifiera de långsammaste frågorna som ingår i den lagrade proceduren.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Kommentar
I demonstrationssyfte visas EXPLAIN ANALYZE-utdata för endast ett fåtal frågor som används i proceduren. Tanken är att man kan samla in EXPLAIN ANALYZE-utdata från alla frågor från loggarna och identifiera de långsammaste av dem och försöka finjustera dem.
Relaterat innehåll
- Felsöka hög CPU-användning i Azure Database for PostgreSQL – flexibel server.
- Felsöka hög IOPS-användning i Azure Database for PostgreSQL – flexibel server.
- Felsöka hög minnesanvändning i Azure Database for PostgreSQL – flexibel server.
- Serverparametrar i Azure Database for PostgreSQL – flexibel server.
- Autovacuumjustering i Azure Database for PostgreSQL – flexibel server.