Hantera och analysera flödesloggar för nätverkssäkerhetsgrupp med Hjälp av Network Watcher och Grafana
Viktigt!
Den 30 september 2027 dras nätverkssäkerhetsgruppens flödesloggar tillbaka. Som en del av den här tillbakadragningen kommer du inte längre att kunna skapa nya NSG-flödesloggar från och med den 30 juni 2025. Vi rekommenderar att du migrerar till flödesloggar för virtuella nätverk, vilket övervinner begränsningarna i NSG-flödesloggar. Efter slutdatumet stöds inte längre trafikanalys som är aktiverad med NSG-flödesloggar, och befintliga NSG-flödesloggresurser i dina prenumerationer tas bort. NSG-flödesloggposter tas dock inte bort och fortsätter att följa deras respektive kvarhållningsprinciper. Mer information finns i det officiella meddelandet.
NSG-flödesloggar (Network Security Group) innehåller information som kan användas för att förstå inkommande och utgående IP-trafik i nätverksgränssnitt. Dessa flödesloggar visar utgående och inkommande flöden per NSG-regel, det nätverkskort som flödet gäller för, 5-tuppelns information om flödet (käll-/mål-IP, käll-/målport, protokoll) och om trafiken tilläts eller nekades.
Du kan ha många NSG:er i nätverket med flödesloggning aktiverat. Den här mängden loggningsdata gör det besvärligt att parsa och få insikter från dina loggar. Den här artikeln innehåller en lösning för att centralt hantera dessa NSG-flödesloggar med grafana, ett öppen källkod diagramverktyg, ElasticSearch, en distribuerad sökmotor och analysmotor, och Logstash, som är en öppen källkod databearbetningspipeline på serversidan.
Scenario
NSG-flödesloggar aktiveras med Network Watcher och lagras i Azure Blob Storage. Ett Logstash-plugin-program används för att ansluta och bearbeta flödesloggar från Blob Storage och skicka dem till ElasticSearch. När flödesloggarna har lagrats i ElasticSearch kan de analyseras och visualiseras till anpassade instrumentpaneler i Grafana.
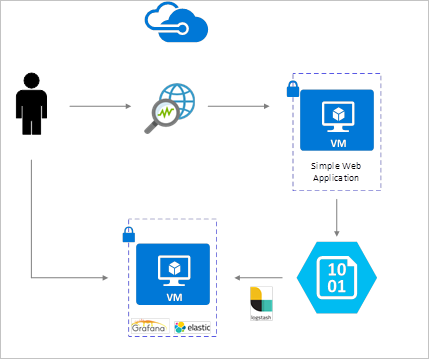
Installationssteg
Aktivera flödesloggning för nätverkssäkerhetsgrupp
I det här scenariot måste du ha nätverkssäkerhetsgruppflödesloggning aktiverat på minst en nätverkssäkerhetsgrupp i ditt konto. Anvisningar om hur du aktiverar flödesloggar för nätverkssäkerhet finns i följande artikel Introduktion till flödesloggning för nätverkssäkerhetsgrupper.
Konfigurationsöverväganden
I det här exemplet konfigureras Grafana, ElasticSearch och Logstash på en Ubuntu LTS-server som distribueras i Azure. Den här minimala konfigurationen används för att köra alla tre komponenterna – alla körs på samma virtuella dator. Den här konfigurationen bör endast användas för testning och icke-kritiska arbetsbelastningar. Logstash, Elasticsearch och Grafana kan alla utformas för att skala oberoende över många instanser. Mer information finns i dokumentationen för var och en av dessa komponenter.
Installera Logstash
Du använder Logstash för att platta ut JSON-formaterade flödesloggar till en flödestupplarnivå.
Följande instruktioner används för att installera Logstash i Ubuntu. Anvisningar om hur du installerar det här paketet i Red Hat Enterprise Linux finns i Installera från paketlagringsplatser – yum.
Installera Logstash genom att köra följande kommandon:
curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-5.2.0.deb sudo dpkg -i logstash-5.2.0.debKonfigurera Logstash för att parsa flödesloggarna och skicka dem till ElasticSearch. Skapa en Logstash.conf-fil med hjälp av:
sudo touch /etc/logstash/conf.d/logstash.confLägg till följande innehåll i filen. Ändra lagringskontots namn och åtkomstnyckel så att de återspeglar information om ditt lagringskonto:
input { azureblob { storage_account_name => "mystorageaccount" storage_access_key => "VGhpcyBpcyBhIGZha2Uga2V5Lg==" container => "insights-logs-networksecuritygroupflowevent" codec => "json" # Refer https://learn.microsoft.com/azure/network-watcher/network-watcher-read-nsg-flow-logs # Typical numbers could be 21/9 or 12/2 depends on the nsg log file types file_head_bytes => 12 file_tail_bytes => 2 # Enable / tweak these settings when event is too big for codec to handle. # break_json_down_policy => "with_head_tail" # break_json_batch_count => 2 } } filter { split { field => "[records]" } split { field => "[records][properties][flows]"} split { field => "[records][properties][flows][flows]"} split { field => "[records][properties][flows][flows][flowTuples]"} mutate { split => { "[records][resourceId]" => "/"} add_field => { "Subscription" => "%{[records][resourceId][2]}" "ResourceGroup" => "%{[records][resourceId][4]}" "NetworkSecurityGroup" => "%{[records][resourceId][8]}" } convert => {"Subscription" => "string"} convert => {"ResourceGroup" => "string"} convert => {"NetworkSecurityGroup" => "string"} split => { "[records][properties][flows][flows][flowTuples]" => "," } add_field => { "unixtimestamp" => "%{[records][properties][flows][flows][flowTuples][0]}" "srcIp" => "%{[records][properties][flows][flows][flowTuples][1]}" "destIp" => "%{[records][properties][flows][flows][flowTuples][2]}" "srcPort" => "%{[records][properties][flows][flows][flowTuples][3]}" "destPort" => "%{[records][properties][flows][flows][flowTuples][4]}" "protocol" => "%{[records][properties][flows][flows][flowTuples][5]}" "trafficflow" => "%{[records][properties][flows][flows][flowTuples][6]}" "traffic" => "%{[records][properties][flows][flows][flowTuples][7]}" "flowstate" => "%{[records][properties][flows][flows][flowTuples][8]}" "packetsSourceToDest" => "%{[records][properties][flows][flows][flowTuples][9]}" "bytesSentSourceToDest" => "%{[records][properties][flows][flows][flowTuples][10]}" "packetsDestToSource" => "%{[records][properties][flows][flows][flowTuples][11]}" "bytesSentDestToSource" => "%{[records][properties][flows][flows][flowTuples][12]}" } add_field => { "time" => "%{[records][time]}" "systemId" => "%{[records][systemId]}" "category" => "%{[records][category]}" "resourceId" => "%{[records][resourceId]}" "operationName" => "%{[records][operationName]}" "Version" => "%{[records][properties][Version]}" "rule" => "%{[records][properties][flows][rule]}" "mac" => "%{[records][properties][flows][flows][mac]}" } convert => {"unixtimestamp" => "integer"} convert => {"srcPort" => "integer"} convert => {"destPort" => "integer"} add_field => { "message" => "%{Message}" } } date { match => ["unixtimestamp" , "UNIX"] } } output { stdout { codec => rubydebug } elasticsearch { hosts => "localhost" index => "nsg-flow-logs" } }
Den angivna Logstash-konfigurationsfilen består av tre delar: indata, filter och utdata. Indataavsnittet anger indatakällan för loggarna som Logstash ska bearbeta – i det här fallet ska vi använda ett "azureblob"-plugin-indata (installerat i nästa steg) som gör att vi kan komma åt NSG-flödesloggens JSON-filer som lagras i Blob Storage.
Filteravsnittet plattar sedan ut varje flödesloggfil så att varje enskild flödestupplare och dess associerade egenskaper blir en separat Logstash-händelse.
Slutligen vidarebefordrar utdataavsnittet varje Logstash-händelse till ElasticSearch-servern. Ändra logstash-konfigurationsfilen så att den passar dina specifika behov.
Installera plugin-programmet Logstash-indata för Azure Blob Storage
Med det här Logstash-plugin-programmet kan du direkt komma åt flödesloggarna från deras avsedda bloblagringskonto. Om du vill installera det här plugin-programmet kör du kommandot från standardkatalogen för Logstash-installationen (i det här fallet /usr/share/logstash/bin):
sudo /usr/share/logstash/bin/logstash-plugin install logstash-input-azureblob
Mer information om det här plugin-programmet finns i Logstash-plugin-indata för Azure Storage Blobs.
Installera ElasticSearch
Du kan använda följande skript för att installera ElasticSearch. Information om hur du installerar ElasticSearch finns i Elastic Stack.
sudo apt-get install apt-transport-https openjdk-8-jre-headless uuid-runtime pwgen -y
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb https://packages.elastic.co/elasticsearch/5.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-5.x.list
sudo apt-get update && apt-get install elasticsearch
sudo sed -i s/#cluster.name:.*/cluster.name:\ grafana/ /etc/elasticsearch/elasticsearch.yml
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.service
Installera Grafana
Kör följande kommandon för att installera och köra Grafana:
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.5.1_amd64.deb
sudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_4.5.1_amd64.deb
sudo service grafana-server start
Mer installationsinformation finns i Installera på Debian/Ubuntu.
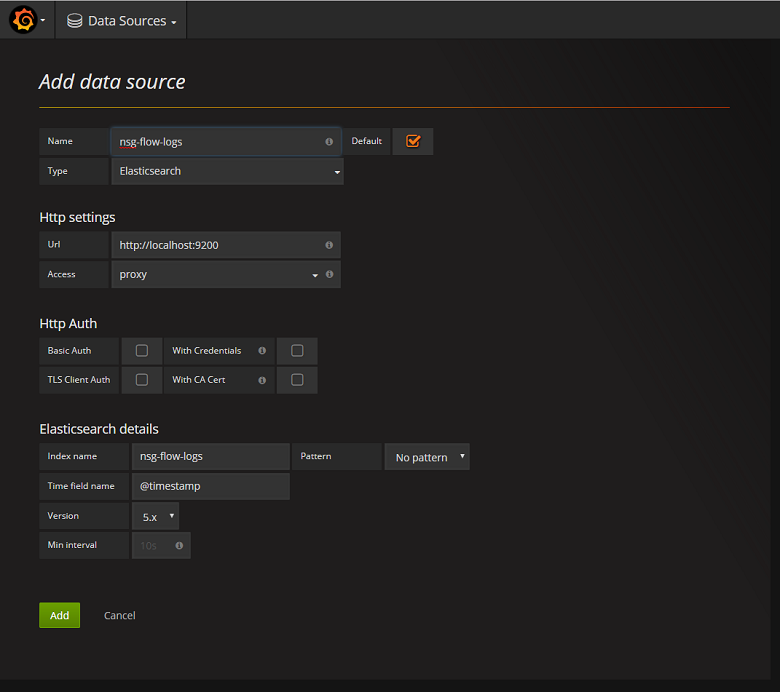
Lägg till ElasticSearch-servern som en datakälla
Därefter måste du lägga till ElasticSearch-indexet som innehåller flödesloggar som en datakälla. Du kan lägga till en datakälla genom att välja Lägg till datakälla och fylla i formuläret med relevant information. Ett exempel på den här konfigurationen finns i följande skärmbild:
Skapa en instrumentpanel
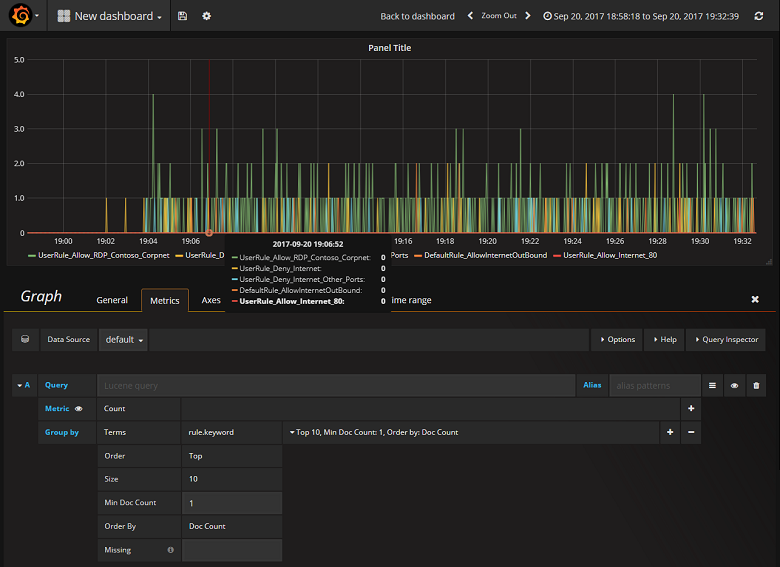
Nu när du har konfigurerat Grafana att läsa från ElasticSearch-indexet som innehåller NSG-flödesloggar kan du skapa och anpassa instrumentpaneler. Om du vill skapa en ny instrumentpanel väljer du Skapa din första instrumentpanel. Följande exempeldiagramkonfiguration visar flöden segmenterade efter NSG-regel:
Slutsats
Genom att integrera Network Watcher med ElasticSearch och Grafana har du nu ett bekvämt och centraliserat sätt att hantera och visualisera NSG-flödesloggar samt andra data. Grafana har ett antal andra kraftfulla graffunktioner som också kan användas för att ytterligare hantera flödesloggar och bättre förstå din nätverkstrafik. Nu när du har konfigurerat och anslutit en Grafana-instans till Azure kan du fortsätta utforska de andra funktionerna som den erbjuder.
Gå vidare
- Läs mer om hur du använder Network Watcher.