Migrera till Azure Managed Instance för Apache Cassandra med Apache Spark
Där det är möjligt rekommenderar vi att du använder inbyggd Apache Cassandra-replikering för att migrera data från ditt befintliga kluster till Azure Managed Instance för Apache Cassandra genom att konfigurera ett hybridkluster. Den här metoden använder Apache Cassandras skvallerprotokoll för att replikera data från källdatacentret till ditt nya datacenter för hanterade instanser. Det kan dock finnas scenarier där källdatabasversionen inte är kompatibel eller om en hybridklusterkonfiguration annars inte är möjlig.
I den här självstudien beskrivs hur du migrerar data till Migrera till Azure Managed Instance för Apache Cassandra offline med hjälp av Cassandra Spark Connector och Azure Databricks för Apache Spark.
Förutsättningar
Etablera ett Azure Managed Instance för Apache Cassandra-kluster med Azure Portal eller Azure CLI och se till att du kan ansluta till klustret med CQLSH.
Etablera ett Azure Databricks-konto i ditt hanterade virtuella Cassandra-nätverk. Se till att den också har nätverksåtkomst till ditt Cassandra-källkluster.
Kontrollera att du redan har migrerat nyckelrymds-/tabellschemat från cassandra-källdatabasen till måldatabasen för Cassandra Managed Instance.
Etablera ett Azure Databricks-kluster
Vi rekommenderar att du väljer Databricks runtime version 7.5, som stöder Spark 3.0.

Lägga till beroenden
Lägg till Apache Spark Cassandra Connector-biblioteket i klustret för att ansluta till både interna slutpunkter och Azure Cosmos DB Cassandra-slutpunkter. I klustret väljer du Bibliotek>Installera ny>Maven och lägger sedan till com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 i Maven-koordinater.
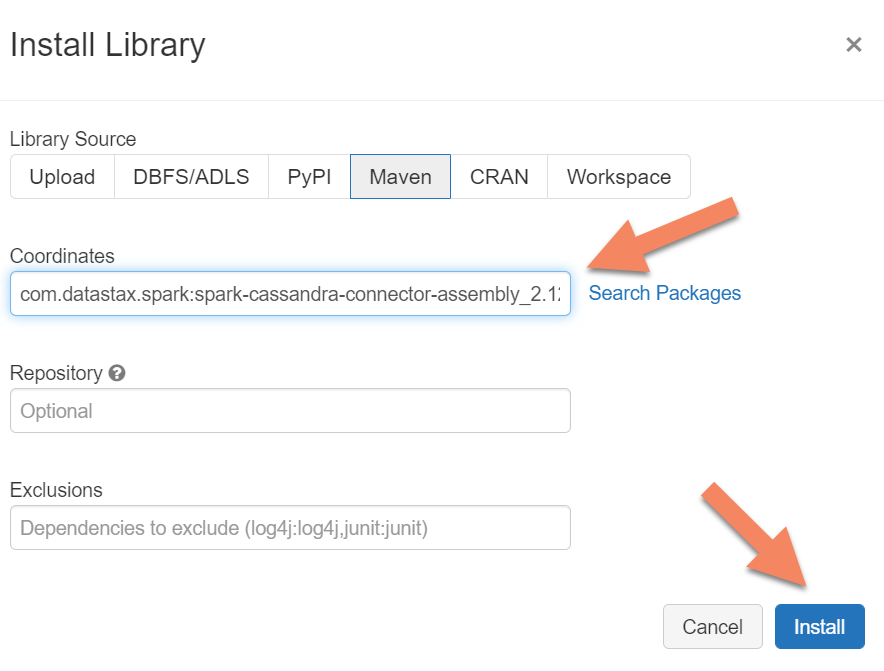
Välj Installera och starta sedan om klustret när installationen är klar.
Kommentar
Kontrollera att du startar om Databricks-klustret när Cassandra Connector-biblioteket har installerats.
Skapa Scala Notebook för migrering
Skapa en Scala Notebook i Databricks. Ersätt dina cassandra-konfigurationer för källa och mål med motsvarande autentiseringsuppgifter samt käll- och målnyckelområden och tabeller. Kör sedan följande kod:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "10",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Kommentar
Om du behöver bevara originalet writetime för varje rad kan du läsa cassandra-migratorexemplet .