Hantera beräkningssession för promptflöde i Azure Machine Learning-studio
En bearbetningssession för promptflöde innehåller databehandlingsresurser som krävs för att programmet ska kunna köras, inklusive en Docker-avbildning som innehåller alla nödvändiga beroendepaket. Den här tillförlitliga och skalbara miljön gör det möjligt för promptflöde att effektivt utföra sina uppgifter och funktioner för en sömlös användarupplevelse.
Behörigheter och roller för hantering av beräkningssessioner
Om du vill tilldela roller måste du ha owner eller Microsoft.Authorization/roleAssignments/write behörighet för resursen.
För användare av beräkningssessionen tilldelar du AzureML Data Scientist rollen på arbetsytan. Mer information finns i Hantera åtkomst till en Azure Machine Learning-arbetsyta.
Rolltilldelningen kan ta flera minuter att börja gälla.
Starta en beräkningssession i studio
Innan du använder Azure Machine Learning-studio för att starta en beräkningssession kontrollerar du att:
- Du har
AzureML Data Scientistrollen i arbetsytan. - Standarddatalagret (vanligtvis
workspaceblobstore) på din arbetsyta är blobtypen. - Arbetskatalogen (
workspaceworkingdirectory) finns på arbetsytan. - Om du använder ett virtuellt nätverk för promptflöde förstår du övervägandena i Nätverksisolering i promptflödet.
Starta en beräkningssession på en flödessida
Ett flöde binder till en beräkningssession. Du kan starta en beräkningssession på en flödessida.
Välj start. Starta en beräkningssession med hjälp av miljön som definierats i
flow.dag.yamlflödesmappen. Den körs på den virtuella datorns storlek (VM) för serverlös beräkning som du har tillräckligt med kvot på arbetsytan.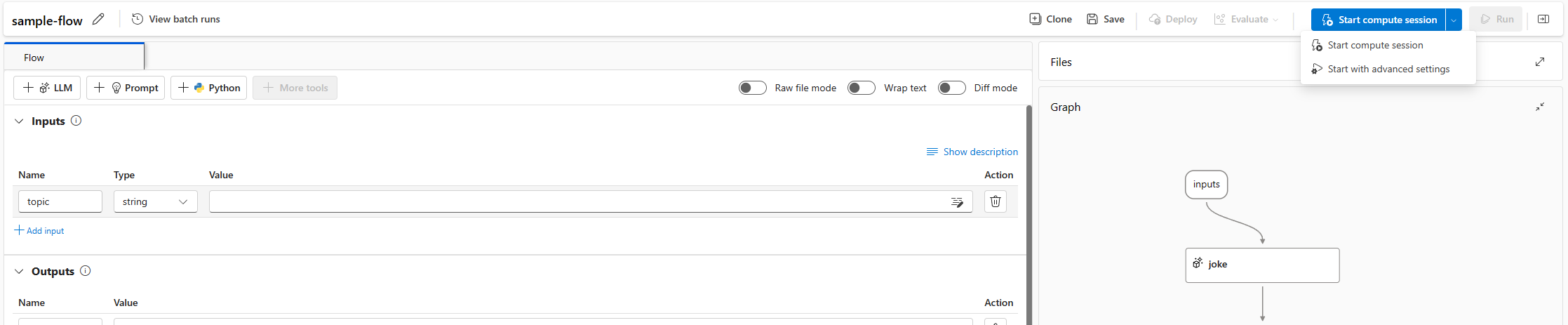
Välj Börja med avancerade inställningar. I de avancerade inställningarna kan du:
- Välj beräkningstyp. Du kan välja mellan serverlös beräknings- och beräkningsinstans.
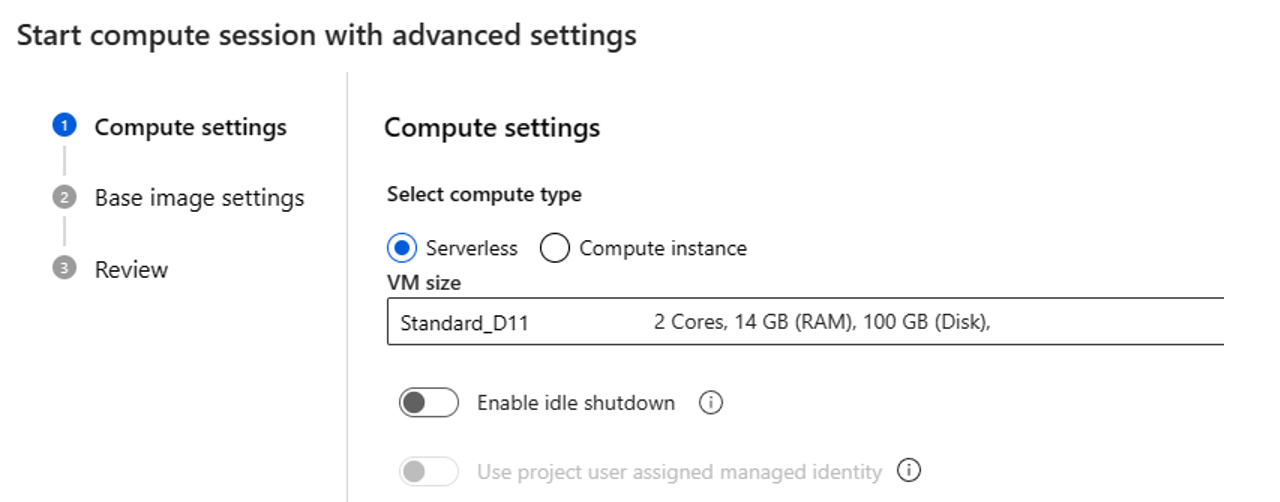
Om du väljer serverlös beräkning kan du ange följande inställningar:
- Anpassa storleken på den virtuella datorn som beräkningssessionen använder. Välj VM-serien D och senare. Mer information finns i avsnittet om VM-serier och storlekar som stöds
- Anpassa inaktivitetstiden, vilket tar bort beräkningssessionen automatiskt om den inte används på ett tag.
- Ange den användartilldelade hanterade identiteten. Beräkningssessionen använder den här identiteten för att hämta en basavbildning, autentisering med anslutnings- och installationspaket. Kontrollera att den användartilldelade hanterade identiteten har tillräcklig behörighet. Om du inte anger den här identiteten använder vi användaridentiteten som standard.
- Du kan använda följande CLI-kommando för att tilldela användartilldelad hanterad identitet till arbetsytan. Läs mer om hur du skapar och uppdaterar användartilldelade identiteter för en arbetsyta.
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>Om innehållet i workspace_update_with_multiple_UAIs.yml är följande:
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}Dricks
Följande Azure RBAC-rolltilldelningar krävs på din användartilldelade hanterade identitet för din Azure Machine Learning-arbetsyta för att få åtkomst till data på de arbetsyteassocierade resurserna.
Resurs Behörighet Azure Machine Learning-arbetsyta Deltagare Azure Storage Deltagare (kontrollplan) + Storage Blob Data Contributor + Storage File Data Privileged Contributor (dataplan, förbruka flödesutkast i fildelning och data i blob) Azure Key Vault (när du använder behörighetsmodellen åtkomstprinciper) Deltagare + eventuella behörigheter för åtkomstprinciper förutom rensningsåtgärder , det här är standardläget för länkade Azure Key Vault. Azure Key Vault (när du använder RBAC-behörighetsmodell) Deltagare (kontrollplan) + Key Vault-administratör (dataplan) Azure Container Registry Deltagare Azure Application Insights Deltagare Kommentar
Jobbinskickare behöver ha
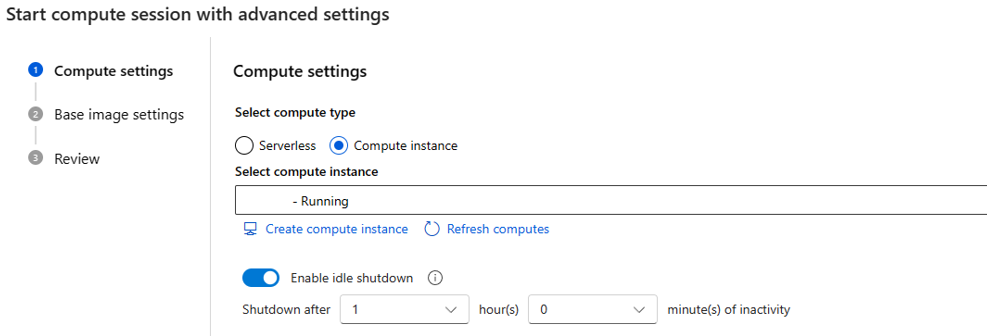
assignbehörighet för användartilldelad hanterad identitet. Du kan tilldelaManaged Identity Operatorrollen eftersom varje gång den skapar en serverlös beräkningssession tilldelar den användartilldelade hanterade identiteten till beräkning.Om du väljer beräkningsinstans som beräkningstyp kan du bara ange inaktiv avstängningstid.
Eftersom den körs på en befintlig beräkningsinstans är vm-storleken fast och kan inte ändras på sessionssidan.
Identiteten som används för den här sessionen definieras också i beräkningsinstansen, som standard använder den användaridentiteten. Läs mer om hur du tilldelar identitet till beräkningsinstansen
För den inaktiva avstängningstiden används den för att definiera livscykeln för beräkningssessionen, om sessionen är inaktiv under den tid du anger tas den bort automatiskt. Och om du har inaktiv avstängning aktiverat på beräkningsinstansen börjar den gälla från beräkningsnivå.
- Välj beräkningstyp. Du kan välja mellan serverlös beräknings- och beräkningsinstans.



Använda en beräkningssession för att skicka en flödeskörning i CLI/SDK
Förutom Studio kan du också ange beräkningssessionen i CLI/SDK när du skickar en flödeskörning.
Du kan också ange instanstypen eller beräkningsinstansens namn under resursdelen. Om du inte anger instanstyp eller beräkningsinstansnamn väljer Azure Machine Learning en instanstyp (VM-storlek) baserat på faktorer som kvot, kostnad, prestanda och diskstorlek. Läs mer om serverlös beräkning.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
Skicka den här körningen via CLI:
pfazure run create --file run.yml
Kommentar
Den inaktiva avstängningen är en timme om du använder CLI/SDK för att skicka en flödeskörning. Du kan gå till beräkningssidan för att släppa beräkning.
Referensfiler utanför flödesmappen
Ibland kanske du vill referera till en requirements.txt fil som ligger utanför flödesmappen. Du kan till exempel ha ett komplext projekt som innehåller flera flöden, och de delar samma requirements.txt fil. Det gör du genom att lägga till det här fältet additional_includes i flow.dag.yaml. Värdet för det här fältet är en lista över den relativa sökvägen till flödesmappen. Om requirements.txt till exempel finns i den överordnade mappen i flödesmappen kan du lägga till ../requirements.txt i fältet additional_includes .
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
Filen requirements.txt kopieras till flödesmappen och använder den för att starta beräkningssessionen.
Uppdatera en beräkningssession på studioflödessidan
På en flödessida kan du använda följande alternativ för att hantera en beräkningssession:
- Ändra inställningar för beräkningssessioner, du ändrar beräkningsinställningar som VM-storlek och e-användartilldelad hanterad identitet för serverlös beräkning, om du använder beräkningsinstansen kan du ändra till att använda en annan instans. Du kan också ändra
- kan också ändra den användartilldelade hanterade identiteten för serverlös beräkning. Om du ändrar storleken på den virtuella datorn återställs beräkningssessionen med den nya VM-storleken. Om du
- Installera paket från requirements.txt Öppna
requirements.txti användargränssnittet för promptflöde. Du kan lägga till paket i det. - Visa installerade paket visar de paket som är installerade i beräkningssessionen. Den innehåller paketen som installeras på basavbildningen och paket som
requirements.txtanges i filen i flödesmappen. - Återställ beräkningssessionen tar bort den aktuella beräkningssessionen och skapar en ny med samma miljö. Om du stöter på ett problem med paketkonflikter kan du prova det här alternativet.
- Stoppa beräkningssessionen tar bort den aktuella beräkningssessionen. Om det inte finns någon aktiv beräkningssession på den underliggande beräkningen tas även den serverlösa beräkningsresursen bort.

Du kan också anpassa miljön som du använder för att köra det här flödet genom att lägga till paket i requirements.txt filen i flödesmappen. När du har lagt till fler paket i den här filen kan du välja något av följande alternativ:
- Spara och installera utlösare
pip install -r requirements.txti flödesmappen. Processen kan ta några minuter, beroende på vilka paket du installerar. - Spara sparar bara
requirements.txtfilen. Du kan installera paketen senare själv.

Kommentar
Du kan ändra platsen och till och med filnamnet requirements.txtför , men se till att även ändra den i flow.dag.yaml filen i flödesmappen.
Fäst inte versionen av promptflow och promptflow-tools i requirements.txt, eftersom vi redan inkluderar dem i sessionsbasavbildningen.
requirements.txt stöder inte lokala hjulfiler. Skapa dem i avbildningen och uppdatera den anpassade basavbildningen i flow.dag.yaml. Läs mer om hur du skapar en anpassad basavbildning.
Lägga till paket i en privat feed i Azure DevOps
Följ dessa steg om du vill använda ett privat flöde i Azure DevOps:
Tilldela hanterad identitet till arbetsyta eller beräkningsinstans.
Använd serverlös beräkning som beräkningssession. Du måste tilldela användartilldelad hanterad identitet till arbetsytan.
Skapa en användartilldelad hanterad identitet och lägg till den här identiteten i Azure DevOps-organisationen. Mer information finns i Använda tjänstens huvudnamn och hanterade identiteter.
Kommentar
Om knappen Lägg till användare inte visas har du förmodligen inte de behörigheter som krävs för att utföra den här åtgärden.
Lägga till eller uppdatera användartilldelade identiteter till en arbetsyta.
Kommentar
Kontrollera att den användartilldelade hanterade identiteten har
Microsoft.KeyVault/vaults/readpå den länkade nyckelvaulten för arbetsytan.
Använd beräkningsinstansen som beräkningssession. Du behöver tilldela en användartilldelad hanterad identitet till en beräkningsinstans.
Lägg till
{private}i din privata feed-URL. Om du till exempel vill installeratest_packagefråntest_feedi Azure DevOps lägger du till-i https://{private}@{test_feed_url_in_azure_devops}irequirements.txt:-i https://{private}@{test_feed_url_in_azure_devops} test_packageAnge med användartilldelad hanterad identitet i konfigurationen av beräkningssessionen.
Om du använder serverlös beräkning anger du den användartilldelade hanterade identiteten i Starta med avancerade inställningar om beräkningssessionen inte körs eller använder knappen Ändra inställningar för beräkningssession om beräkningssessionen körs.
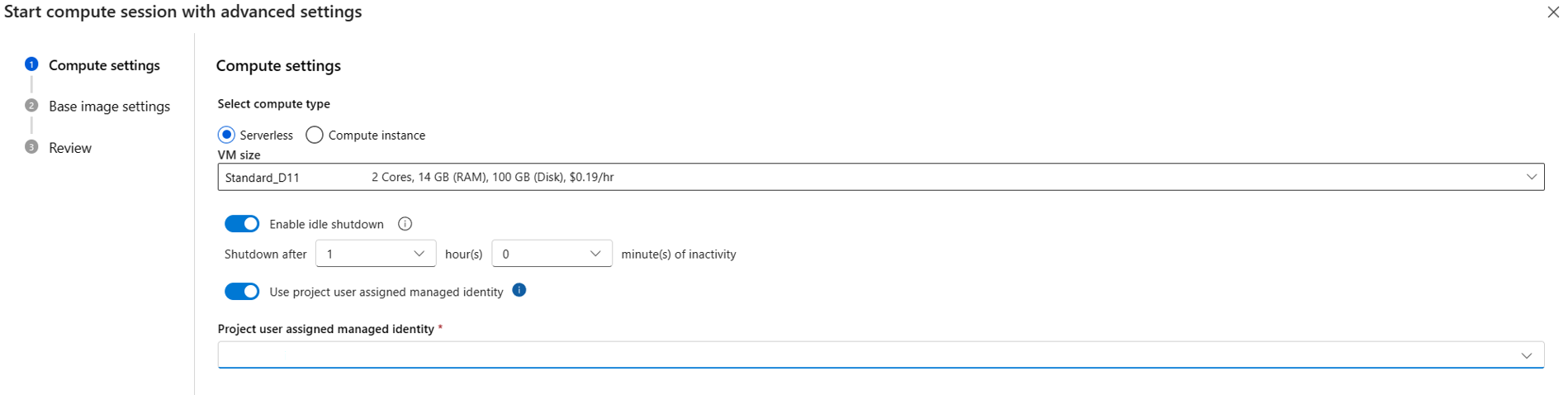
Om du använder beräkningsinstansen använder den den användartilldelade hanterade identiteten som du tilldelade till beräkningsinstansen.

Kommentar
Den här metoden fokuserar främst på snabb testning i flödesutvecklingsfasen, om du också vill distribuera det här flödet som slutpunkt skapar du det här privata flödet i avbildningen och uppdaterar anpassa basavbildningen i flow.dag.yaml. Läs mer om hur du skapar en anpassad basavbildning
Ändra basavbildningen för beräkningssessionen
Som standard använder vi den senaste basavbildningen för promptflöde. Om du vill använda en annan basavbildning kan du skapa en anpassad.
- I Studio kan du ändra basavbildningen i basavbildningsinställningarna under inställningarna för beräkningssessionen.

Du kan också ange den nya basavbildningen
flow.dag.yamlunderenvironmenti filen i flödesmappen.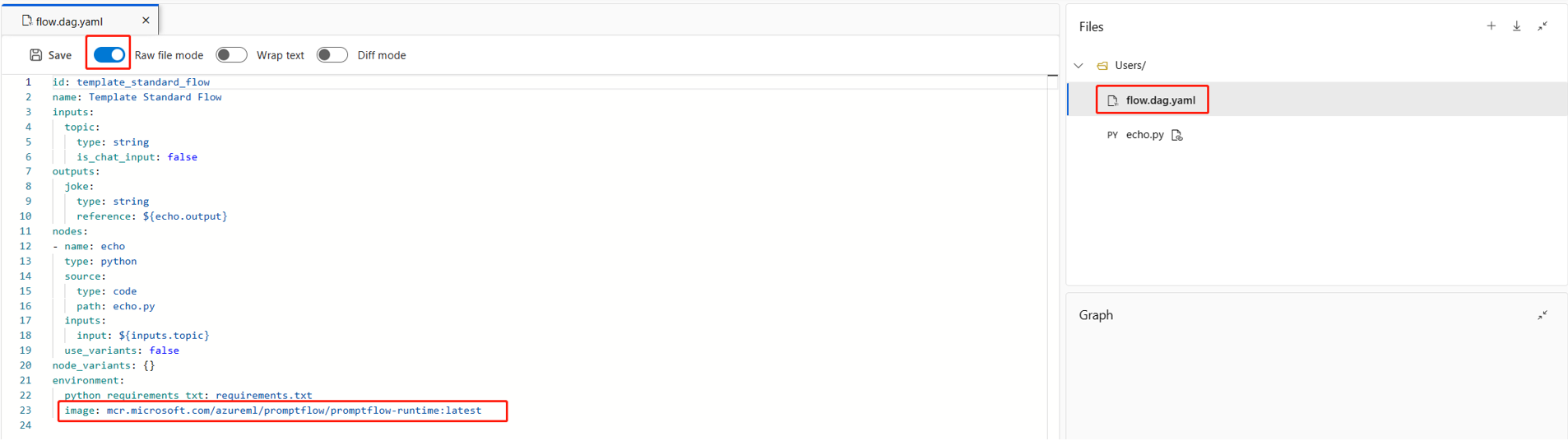
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

Om du vill använda den nya basavbildningen måste du återställa beräkningssessionen. Den här processen tar flera minuter eftersom den hämtar den nya basavbildningen och installerar om paketen.
Hantera serverlös instans som används av beräkningssessionen
När du använder serverlös beräkning som en beräkningssession kan du hantera den serverlösa instansen. Visa den serverlösa instansen på fliken för beräkningssessionslistan på beräkningssidan.

Du kan också komma åt flöden och körningar som körs på beräkningen under fliken Aktiva flöden och körningar . När du tar bort instansen påverkas flödet och körs på den.

Relation mellan beräkningssession, beräkningsresurs, flöde och användare
- En enskild användare kan ha flera beräkningsresurser (serverlös eller beräkningsinstans). På grund av olika behov kan en enskild användare ha flera beräkningsresurser. En användare kan till exempel ha flera beräkningsresurser med olika VM-storlek eller en annan användartilldelad hanterad identitet.
- En beräkningsresurs kan bara användas av en enskild användare. En beräkningsresurs används som en enskild användares privata utvecklingsruta. Flera användare kan inte dela samma beräkningsresurser.
- En beräkningsresurs kan vara värd för flera beräkningssessioner. En beräkningssession är en container som körs på en underliggande beräkningsresurs. Till exempel behöver redigering av promptflöde inte för mycket beräkningsresurser, så en enda beräkningsresurs kan vara värd för flera beräkningssessioner från samma användare.
- En beräkningssession tillhör bara en enda beräkningsresurs i taget. Men du kan ta bort eller stoppa en beräkningssession och omallokera den till en annan beräkningsresurs.
- Ett flöde kan bara ha en beräkningssession. Varje flöde är fristående och definierar basavbildningen och nödvändiga Python-paket i flödesmappen för beräkningssessionen.
Växla körning till beräkningssession
Beräkningssessioner har följande fördelar jämfört med körning av beräkningsinstanser:
- Automatisk hantering av livscykeln för session och underliggande beräkning. Du behöver inte skapa och hantera dem manuellt längre.
- Anpassa enkelt paket genom att lägga till paket i
requirements.txtfilen i flödesmappen i stället för att skapa en anpassad miljö.
Växla en beräkningsinstanskörning till en beräkningssession med hjälp av följande steg:
requirements.txtFörbered filen i flödesmappen. Se till att du inte fäster versionen avpromptflowochpromptflow-toolsirequirements.txt, eftersom vi redan inkluderar dem i basavbildningen. Compute-sessionen installerar paketen irequirements.txtfilen när den startas.- Om du skapar en anpassad miljö för att skapa en körning av beräkningsinstansen kan du hämta avbildningen från miljöinformationssidan och ange den
flow.dag.yamli filen i flödesmappen. Mer information finns i Ändra basavbildningen för beräkningssessionen. Kontrollera att du eller den relaterade användartilldelade hanterade identiteten på arbetsytan haracr pullbehörighet för avbildningen.

- För beräkningsresursen kan du fortsätta att använda den befintliga beräkningsinstansen om du vill hantera livscykeln manuellt eller om du kan prova serverlös beräkning vars livscykel hanteras av systemet.