Använda parallella jobb i pipelines
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Den här artikeln beskriver hur du använder CLI v2 och Python SDK v2 för att köra parallella jobb i Azure Machine Learning-pipelines. Parallella jobb påskyndar jobbkörningen genom att distribuera upprepade uppgifter på kraftfulla beräkningskluster med flera noder.
Maskininlärningstekniker har alltid skalningskrav på sina tränings- eller slutsatsdragningsuppgifter. När en dataexpert till exempel tillhandahåller ett enda skript för att träna en modell för försäljningsförutsägelse måste maskininlärningstekniker tillämpa den här träningsuppgiften på varje enskilt datalager. Utmaningarna med den här utskalningsprocessen omfattar långa körningstider som orsakar fördröjningar och oväntade problem som kräver manuella åtgärder för att hålla aktiviteten igång.
Kärnjobbet för Azure Machine Learning-parallellisering är att dela upp en enda serieuppgift i minibatcherna och skicka dessa minibatch till flera beräkningar som ska köras parallellt. Parallella jobb minskar avsevärt körningstiden från slutpunkt till slutpunkt och hanterar även fel automatiskt. Överväg att använda parallella Azure Machine Learning-jobb för att träna många modeller ovanpå dina partitionerade data eller för att påskynda dina storskaliga batchinferensaktiviteter.
I ett scenario där du till exempel kör en objektidentifieringsmodell på en stor uppsättning avbildningar kan du med parallella Azure Machine Learning-jobb enkelt distribuera dina avbildningar för att köra anpassad kod parallellt i ett specifikt beräkningskluster. Parallellisering kan avsevärt minska tidskostnaden. Parallella Jobb i Azure Machine Learning kan också förenkla och automatisera processen för att göra den mer effektiv.
Förutsättningar
- Ha ett Azure Machine Learning-konto och en arbetsyta.
- Förstå Azure Machine Learning-pipelines.
- Installera Azure CLI och
mltillägget. Mer information finns i Installera, konfigurera och använda CLI (v2). Tilläggetmlinstalleras automatiskt första gången du kör ettaz mlkommando. - Förstå hur du skapar och kör Azure Machine Learning-pipelines och -komponenter med CLI v2.
Skapa och köra en pipeline med ett parallellt jobbsteg
Ett parallellt Azure Machine Learning-jobb kan bara användas som ett steg i ett pipelinejobb.
Följande exempel kommer från Kör ett pipelinejobb med parallella jobb i pipeline i Azure Machine Learning-exempellagringsplatsen .
Förbereda för parallellisering
Det här parallella jobbsteget kräver förberedelse. Du behöver ett postskript som implementerar de fördefinierade funktionerna. Du måste också ange attribut i den parallella jobbdefinitionen som:
- Definiera och binda indata.
- Ange datadivisionsmetoden.
- Konfigurera dina beräkningsresurser.
- Anropa postskriptet.
I följande avsnitt beskrivs hur du förbereder det parallella jobbet.
Deklarera indata- och datadelningsinställningen
Ett parallellt jobb kräver att en större indata delas upp och bearbetas parallellt. Det huvudsakliga indataformatet kan vara antingen tabelldata eller en lista med filer.
Olika dataformat har olika indatatyper, indatalägen och datadivisionsmetoder. I följande tabell beskrivs alternativen:
| Dataformat | Input type | Indataläge | Datadivisionsmetod |
|---|---|---|---|
| Fillista | mltable eller uri_folder |
ro_mount eller download |
Efter storlek (antal filer) eller efter partition |
| Tabelldata | mltable |
direct |
Efter storlek (uppskattad fysisk storlek) eller efter partition |
Kommentar
Om du använder tabell mltable som dina viktigaste indata måste du:
mltableInstallera biblioteket i din miljö, som på rad 9 i den här conda-filen.- Ha en MLTable-specifikationsfil under din angivna sökväg med avsnittet
transformations: - read_delimited:ifyllt. Exempel finns i Skapa och hantera datatillgångar.
Du kan deklarera dina viktigaste indata med input_data attributet i det parallella jobbet YAML eller Python och binda data med det definierade input parallella jobbet med hjälp ${{inputs.<input name>}}av . Sedan definierar du datadivisionsattributet för dina större indata beroende på din datadivisionsmetod.
| Datadivisionsmetod | Attributets namn | Attributtyp | Jobbexempel |
|---|---|---|---|
| Efter storlek | mini_batch_size |
sträng | Förutsägelse för Iris-batch |
| Efter partition | partition_keys |
lista över strängar | Försäljningsförutsägelse för apelsinjuice |
Konfigurera beräkningsresurserna för parallellisering
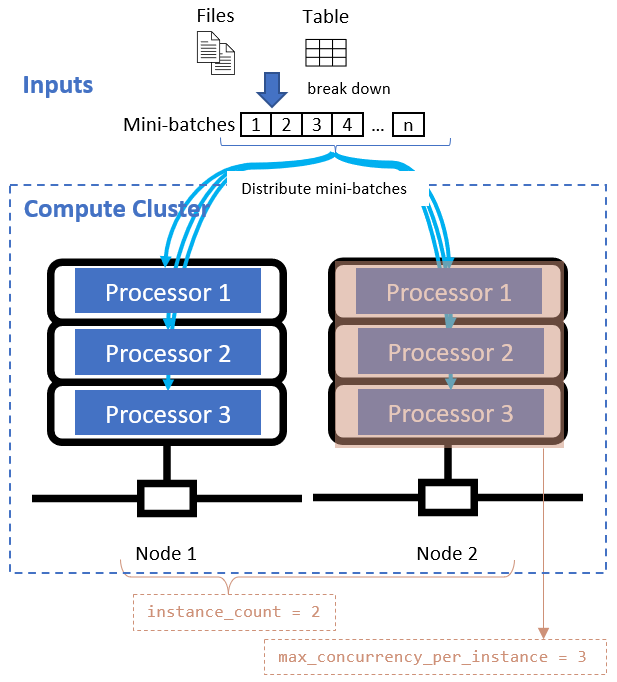
När du har definierat datadivisionsattributet konfigurerar du beräkningsresurserna för parallelliseringen genom att ange attributen instance_count och max_concurrency_per_instance .
| Attributets namn | Typ | Beskrivning | Standardvärde |
|---|---|---|---|
instance_count |
integer | Antalet noder som ska användas för jobbet. | 1 |
max_concurrency_per_instance |
integer | Antalet processorer på varje nod. | För en GPU-beräkning: 1. För en CPU-beräkning: antal kärnor. |
Dessa attribut fungerar tillsammans med ditt angivna beräkningskluster, enligt följande diagram:
Anropa postskriptet
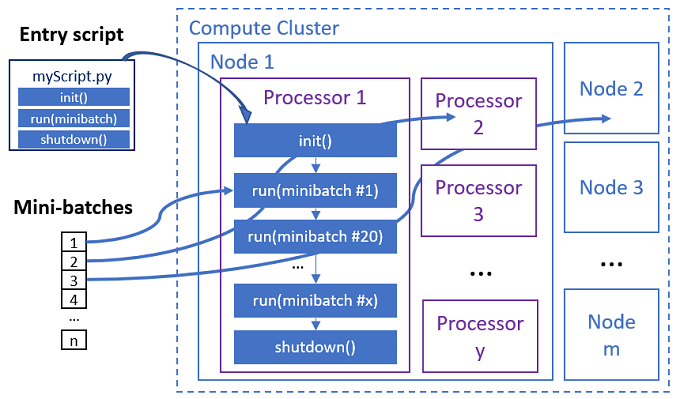
Inmatningsskriptet är en enda Python-fil som implementerar följande tre fördefinierade funktioner med anpassad kod.
| Funktionsnamn | Obligatoriskt | Beskrivning | Indata | Returnera |
|---|---|---|---|---|
Init() |
Y | Vanliga förberedelser innan du börjar köra mini-batchar. Använd till exempel den här funktionen för att läsa in modellen i ett globalt objekt. | -- | -- |
Run(mini_batch) |
Y | Implementerar huvudkörningslogik för mini-batchar. | mini_batch är pandas-dataram om indata är tabelldata eller en filsökvägslista om indata är en katalog. |
Dataram, lista eller tuppeln. |
Shutdown() |
N | Valfri funktion för att göra anpassade rensningar innan du returnerar beräkningen till poolen. | -- | -- |
Viktigt!
Om du vill undvika undantag vid parsning av parse_argsargument i eller Run(mini_batch) funktioner använder du parse_known_args i Init() stället för . Se iris_score exempel för ett postskript med argumentparser.
Viktigt!
Funktionen Run(mini_batch) kräver en retur av antingen en dataram, en lista eller ett tupppelobjekt. Det parallella jobbet använder antalet som returneras för att mäta lyckade objekt under den mini-batchen. Mini-batchantalet ska vara lika med antalet returnerade listor om alla objekt har bearbetats.
Det parallella jobbet kör funktionerna i varje processor, enligt följande diagram.
Se följande exempel på postskript:
Om du vill anropa postskriptet anger du följande två attribut i din parallella jobbdefinition:
| Attributets namn | Typ | Description |
|---|---|---|
code |
sträng | Lokal sökväg till källkodskatalogen som ska laddas upp och användas för jobbet. |
entry_script |
sträng | Python-filen som innehåller implementeringen av fördefinierade parallella funktioner. |
Exempel på parallella jobbsteg
Följande parallella jobbsteg deklarerar indatatypen, läget och datadivisionsmetoden, binder indata, konfigurerar beräkningen och anropar inmatningsskriptet.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Överväg automatiseringsinställningar
Parallella Azure Machine Learning-jobb exponerar många valfria inställningar som automatiskt kan styra jobbet utan manuella åtgärder. I följande tabell beskrivs de här inställningarna.
| Nyckel | Typ | Beskrivning | Tillåtna värden | Standardvärde | Ange i attribut- eller programargument |
|---|---|---|---|---|---|
mini_batch_error_threshold |
integer | Antal misslyckade mini-batchar som ska ignoreras i det här parallella jobbet. Om antalet misslyckade minibatch är högre än det här tröskelvärdet markeras det parallella jobbet som misslyckat. Mini-batchen markeras som misslyckad om: – Antalet retur från run() är mindre än antalet mini-batch-indata.– Undantag fångas i anpassad run() kod. |
[-1, int.max] |
-1, vilket innebär att ignorera alla misslyckade mini-batchar |
Attribut mini_batch_error_threshold |
mini_batch_max_retries |
integer | Antal återförsök när mini-batchen misslyckas eller överskrider tidsgränsen. Om alla återförsök misslyckas markeras mini-batchen som misslyckad enligt mini_batch_error_threshold beräkningen. |
[0, int.max] |
2 |
Attribut retry_settings.max_retries |
mini_batch_timeout |
integer | Tidsgräns i sekunder för körning av den anpassade run() funktionen. Om körningstiden är högre än det här tröskelvärdet avbryts mini-batchen och markeras som misslyckad för att utlösa återförsök. |
(0, 259200] |
60 |
Attribut retry_settings.timeout |
item_error_threshold |
integer | Tröskelvärdet för misslyckade objekt. Misslyckade objekt räknas av antalet mellanrum mellan indata och returer från varje mini-batch. Om summan av misslyckade objekt är högre än det här tröskelvärdet markeras det parallella jobbet som misslyckat. | [-1, int.max] |
-1, vilket innebär att ignorera alla fel under parallella jobb |
Programargument--error_threshold |
allowed_failed_percent |
integer | mini_batch_error_thresholdLiknar , men använder procent av misslyckade minibatch i stället för antalet. |
[0, 100] |
100 |
Programargument--allowed_failed_percent |
overhead_timeout |
integer | Tidsgräns i sekunder för initiering av varje mini-batch. Läs till exempel in mini-batch-data och skicka dem till run() funktionen. |
(0, 259200] |
600 |
Programargument--task_overhead_timeout |
progress_update_timeout |
integer | Tidsgräns i sekunder för övervakning av förloppet för mini-batch-körning. Om inga förloppsuppdateringar tas emot inom den här tidsgränsinställningen markeras det parallella jobbet som misslyckat. | (0, 259200] |
Dynamiskt beräknad av andra inställningar | Programargument--progress_update_timeout |
first_task_creation_timeout |
integer | Tidsgräns i sekunder för övervakning av tiden mellan jobbstarten och körningen av den första mini-batchen. | (0, 259200] |
600 |
Programargument--first_task_creation_timeout |
logging_level |
sträng | Den nivå av loggar som ska dumpas på användarloggfiler. | INFO, WARNING eller DEBUG |
INFO |
Attribut logging_level |
append_row_to |
sträng | Aggregera alla returer från varje körning av mini-batchen och mata ut den i den här filen. Kan referera till någon av utdata från det parallella jobbet med hjälp av uttrycket ${{outputs.<output_name>}} |
Attribut task.append_row_to |
||
copy_logs_to_parent |
sträng | Booleskt alternativ om jobbförloppet, översikten och loggarna ska kopieras till det överordnade pipelinejobbet. | True eller False |
False |
Programargument--copy_logs_to_parent |
resource_monitor_interval |
integer | Tidsintervall i sekunder för att dumpa nodresursanvändning (till exempel cpu eller minne) för att logga mappen under sökvägen logs/sys/perf . Obs! Frekventa dumpresursloggar är något långsamma körningshastigheter. Ange det här värdet till 0 för att sluta dumpa resursanvändningen. |
[0, int.max] |
600 |
Programargument--resource_monitor_interval |
Följande exempelkod uppdaterar dessa inställningar:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Skapa pipelinen med ett parallellt jobbsteg
I följande exempel visas det fullständiga pipelinejobbet med det parallella jobbsteget infogat:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Skicka pipelinejobbet
Skicka ditt pipelinejobb parallellt med hjälp az ml job create av CLI-kommandot:
az ml job create --file pipeline.yml
Kontrollera parallella steg i studiogränssnittet
När du har skickat ett pipelinejobb ger SDK- eller CLI-widgeten en webb-URL-länk till pipelinediagrammet i Azure Machine Learning-studio användargränssnittet.
Om du vill visa parallella jobbresultat dubbelklickar du på det parallella steget i pipelinediagrammet, väljer fliken Inställningar i informationspanelen, expanderar Kör inställningar och expanderar sedan avsnittet Parallell .

Om du vill felsöka parallella jobbfel väljer du fliken Utdata + loggar , expanderar mappen loggar och kontrollerar job_result.txt för att förstå varför det parallella jobbet misslyckades. Information om loggningsstrukturen för parallella jobb finns i readme.txt i samma mapp.
