Kör Azure Machine Learning-modeller från Fabric med batchslutpunkter (förhandsversion)
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
I den här artikeln får du lära dig hur du använder Azure Machine Learning-batchdistributioner från Microsoft Fabric. Även om arbetsflödet använder modeller som distribueras till batchslutpunkter, stöder det även användning av distributioner av batchpipelines från Infrastrukturresurser.
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Förutsättningar
- Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri utvärderingsversion av Microsoft Fabric.
- Logga in på Microsoft Fabric.
- En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning.
- En Azure Machine Learning-arbetsyta. Om du inte har någon använder du stegen i Så här hanterar du arbetsytor för att skapa en.
- Kontrollera att du har följande behörigheter på arbetsytan:
- Skapa/hantera batchslutpunkter och distributioner: Använd roller Ägare, deltagare eller anpassad roll som tillåter
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*. - Skapa ARM-distributioner i arbetsytans resursgrupp: Använd roller Ägare, deltagare eller anpassad roll som tillåter
Microsoft.Resources/deployments/writei resursgruppen där arbetsytan distribueras.
- Skapa/hantera batchslutpunkter och distributioner: Använd roller Ägare, deltagare eller anpassad roll som tillåter
- Kontrollera att du har följande behörigheter på arbetsytan:
- En modell som distribuerats till en batchslutpunkt. Om du inte har någon använder du stegen i Distribuera modeller för bedömning i batchslutpunkter för att skapa en.
- Ladda ned heart-unlabeled.csv exempeldatauppsättning som ska användas för bedömning.
Arkitektur
Azure Machine Learning kan inte direkt komma åt data som lagras i Fabrics OneLake. Du kan dock använda OneLakes funktion för att skapa genvägar i en Lakehouse för att läsa och skriva data som lagras i Azure Data Lake Gen2. Eftersom Azure Machine Learning stöder Azure Data Lake Gen2-lagring kan du använda Fabric och Azure Machine Learning tillsammans med den här konfigurationen. Dataarkitekturen är följande:

Konfigurera dataåtkomst
Om du vill tillåta att Fabric och Azure Machine Learning läser och skriver samma data utan att behöva kopiera dem kan du dra nytta av OneLake-genvägar och Azure Machine Learning-datalager. Genom att peka en OneLake-genväg och ett datalager på samma lagringskonto kan du se till att både Fabric och Azure Machine Learning läser från och skriver till samma underliggande data.
I det här avsnittet skapar eller identifierar du ett lagringskonto som ska användas för att lagra den information som batchslutpunkten ska använda och som Fabric-användare ser i OneLake. Infrastrukturresurser stöder endast lagringskonton med hierarkiska namn aktiverade, till exempel Azure Data Lake Gen2.
Skapa en OneLake-genväg till lagringskontot
Öppna Synapse-Dataingenjör miljön i Fabric.
I den vänstra panelen väljer du arbetsytan Infrastruktur för att öppna den.
Öppna lakehouse som du ska använda för att konfigurera anslutningen. Om du inte redan har ett sjöhus går du till Dataingenjör upplevelse för att skapa ett sjöhus. I det här exemplet använder du ett lakehouse med namnet trusted.
I det vänstra navigeringsfältet öppnar du fler alternativ för Filer och väljer sedan Ny genväg för att ta upp guiden.
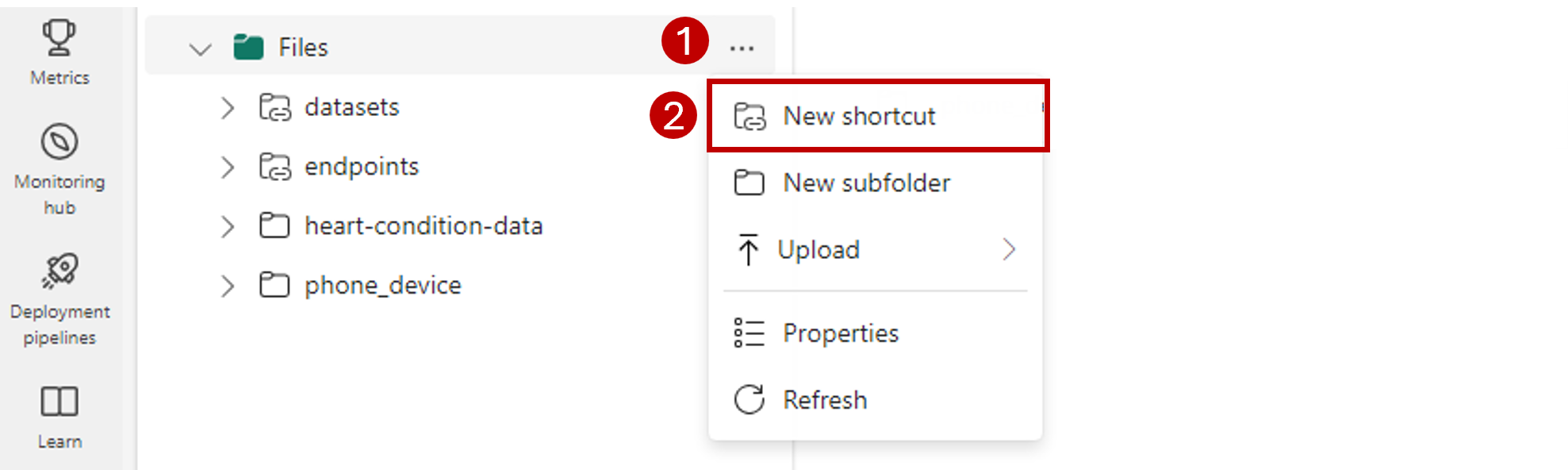
Välj alternativet Azure Data Lake Storage Gen2.

I avsnittet Anslutningsinställningar klistrar du in url:en som är associerad med Azure Data Lake Gen2-lagringskontot.

I avsnittet Anslutningsautentiseringsuppgifter :
- För Anslutning väljer du Skapa ny anslutning.
- För Anslutningsnamn behåller du det ifyllda standardvärdet.
- Som Autentiseringstyp väljer du Organisationskonto för att använda den anslutna användarens autentiseringsuppgifter via OAuth 2.0.
- Välj Logga in för att logga in.
Välj Nästa.
Konfigurera sökvägen till genvägen i förhållande till lagringskontot om det behövs. Använd den här inställningen om du vill konfigurera mappen som genvägen ska peka på.
Konfigurera genvägens namn. Det här namnet kommer att vara en sökväg inne i sjöhuset. I det här exemplet namnger du genvägsdatauppsättningarna.
Spara ändringarna.



Skapa ett datalager som pekar på lagringskontot
Gå till din Azure Machine Learning-arbetsyta.
Gå till avsnittet Data .
Välj fliken Datalager .
Välj Skapa.
Konfigurera datalagringen på följande sätt:
För Datalagernamn anger du trusted_blob.
För Datalagertyp väljer du Azure Blob Storage.
Dricks
Varför ska du konfigurera Azure Blob Storage i stället för Azure Data Lake Gen2? Batch-slutpunkter kan bara skriva förutsägelser till Blob Storage-konton. Men varje Azure Data Lake Gen2-lagringskonto är också ett bloblagringskonto. därför kan de användas på ett utbytbart sätt.
Välj lagringskontot i guiden med hjälp av prenumerations-ID, lagringskonto och blobcontainer (filsystem).

Välj Skapa.
Kontrollera att den beräkning där batchslutpunkten körs har behörighet att montera data i det här lagringskontot. Även om åtkomst fortfarande beviljas av den identitet som anropar slutpunkten måste den beräkning där batchslutpunkten körs ha behörighet att montera det lagringskonto som du anger. Mer information finns i Åtkomst till lagringstjänster.
Ladda upp exempeldatauppsättning
Ladda upp exempeldata för slutpunkten som ska användas som indata:
Gå till arbetsytan Infrastruktur.
Välj det sjöhus där du skapade genvägen.
Gå till genvägen till datauppsättningarna .
Skapa en mapp för att lagra den exempeldatauppsättning som du vill poängsätta. Ge mappen namnet uci-heart-unlabeled.
Använd alternativet Hämta data och välj Ladda upp filer för att ladda upp exempeldatauppsättningen heart-unlabeled.csv.
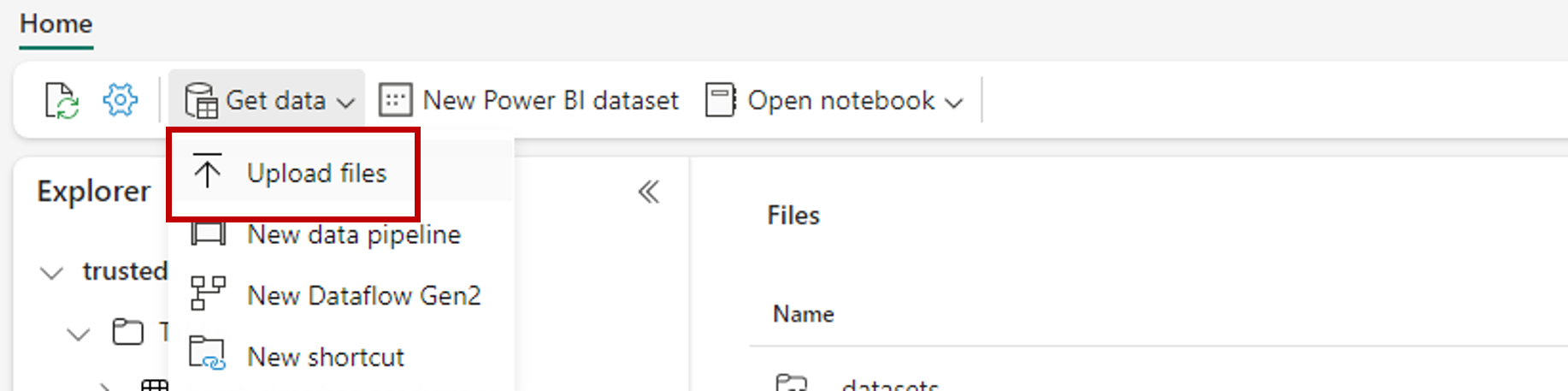
Ladda upp exempeldatauppsättningen.

Exempelfilen är redo att användas. Observera sökvägen till den plats där du sparade den.


Skapa en pipeline för inferens av infrastrukturresurser till batch
I det här avsnittet skapar du en pipeline för fabric-to-batch-slutsatsdragning i din befintliga Fabric-arbetsyta och anropar batchslutpunkter.
Gå tillbaka till Dataingenjör funktionen (om du redan har navigerat bort från den) med hjälp av ikonen för upplevelseväljaren i det nedre vänstra hörnet på startsidan.
Öppna arbetsytan Infrastruktur.
I avsnittet Nytt på startsidan väljer du Datapipeline.
Namnge pipelinen och välj Skapa.

Välj fliken Aktiviteter i verktygsfältet på designerarbetsytan.
Välj fler alternativ i slutet av fliken och välj Azure Machine Learning.
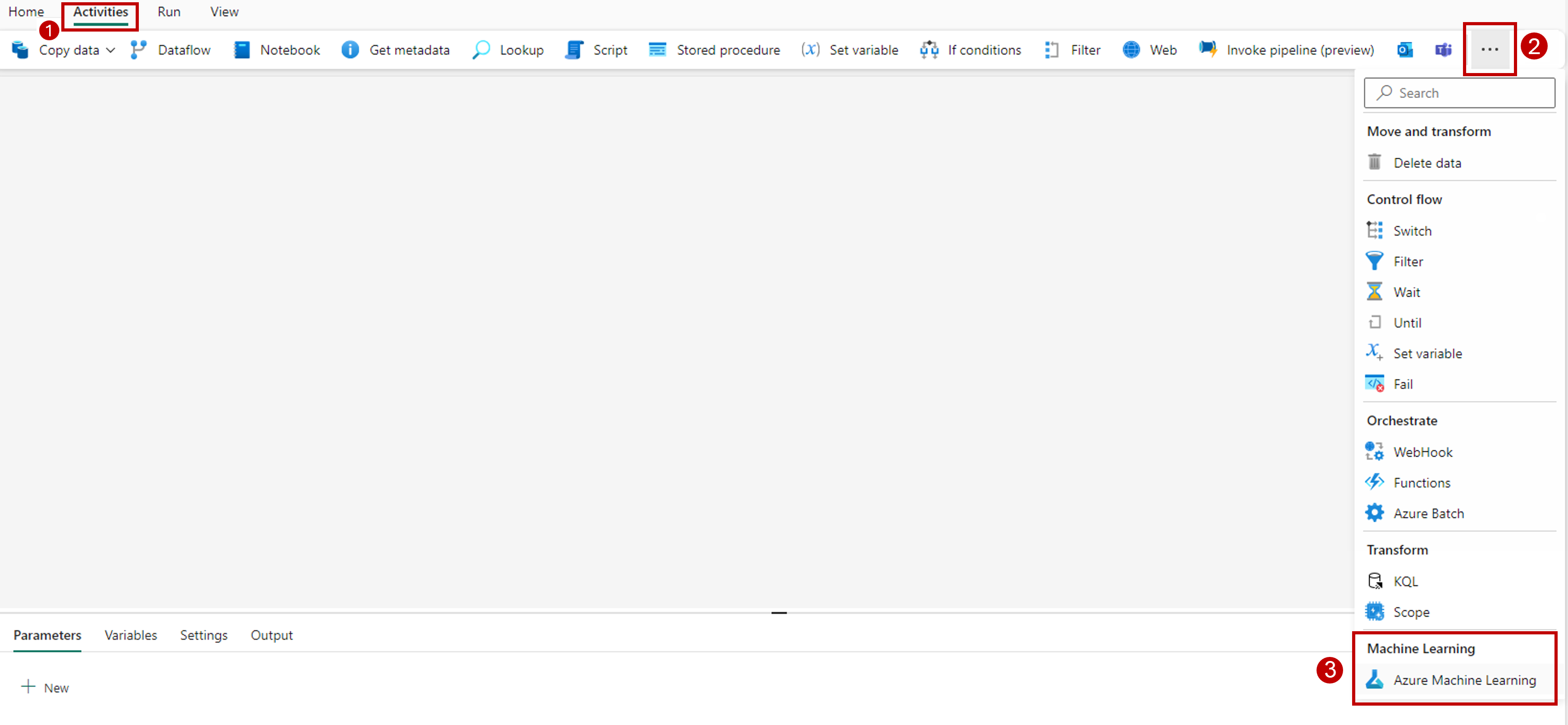
Gå till fliken Inställningar och konfigurera aktiviteten enligt följande:
Välj Ny bredvid Azure Machine Learning-anslutning för att skapa en ny anslutning till Azure Machine Learning-arbetsytan som innehåller distributionen.
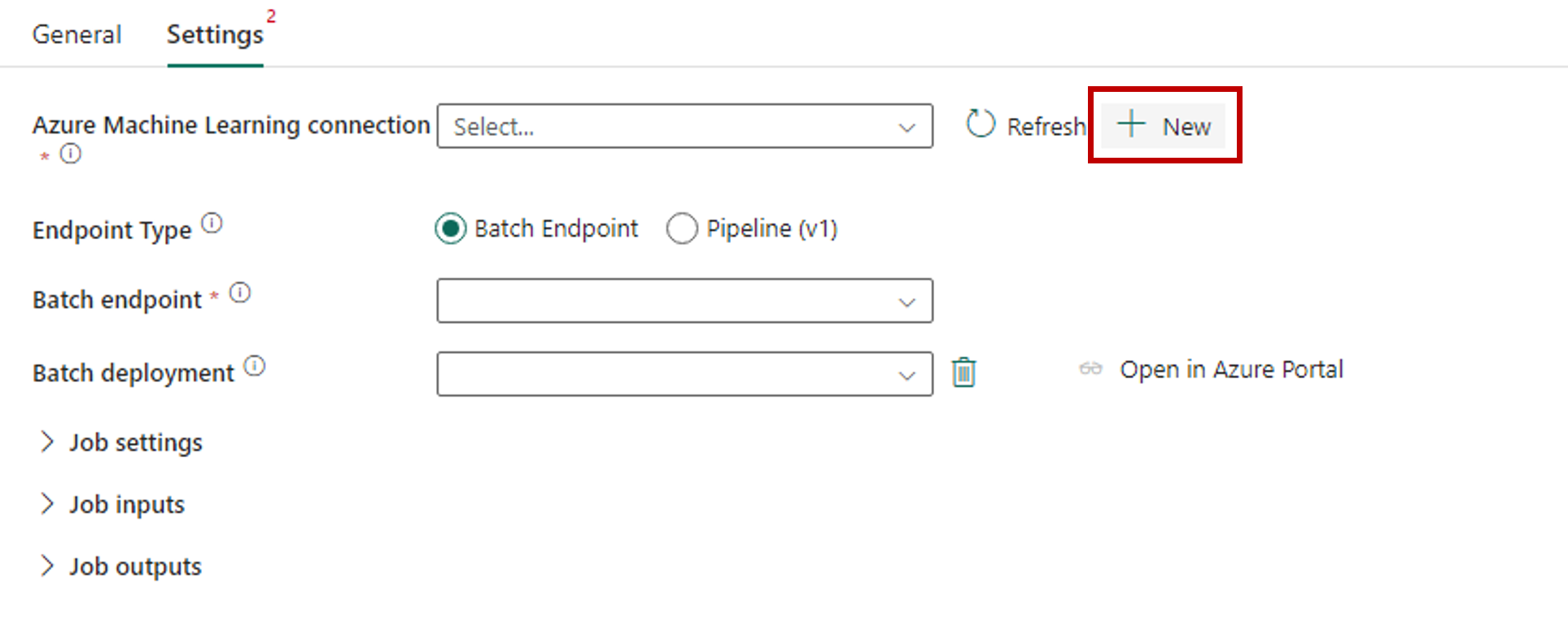
I avsnittet Anslutningsinställningar i guiden för att skapa anger du värdena för prenumerations-ID, Resursgruppnamn och Arbetsytenamn, där slutpunkten distribueras.
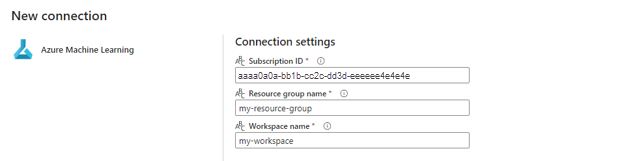
I avsnittet Anslutningsautentiseringsuppgifter väljer du Organisationskonto som värde för autentiseringstypen för din anslutning. Organisationskontot använder den anslutna användarens autentiseringsuppgifter. Du kan också använda tjänstens huvudnamn. I produktionsinställningarna rekommenderar vi att du använder tjänstens huvudnamn. Oavsett autentiseringstyp kontrollerar du att den identitet som är associerad med anslutningen har behörighet att anropa batchslutpunkten som du distribuerade.
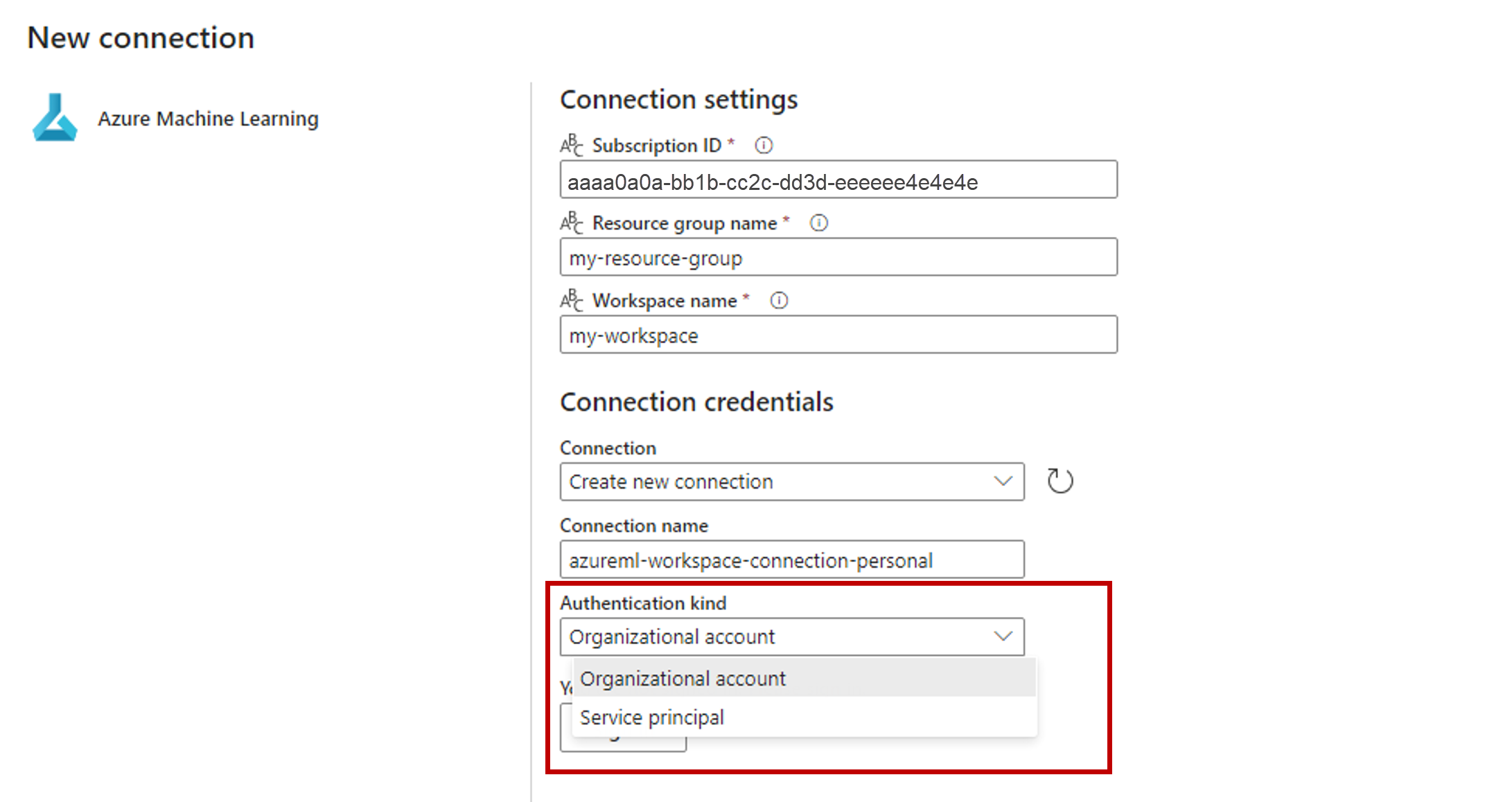
Spara anslutningen. När anslutningen har valts fyller Fabric automatiskt i de tillgängliga batchslutpunkterna i den valda arbetsytan.
För Batch-slutpunkt väljer du den batchslutpunkt som du vill anropa. I det här exemplet väljer du hjärtklassificerare-....
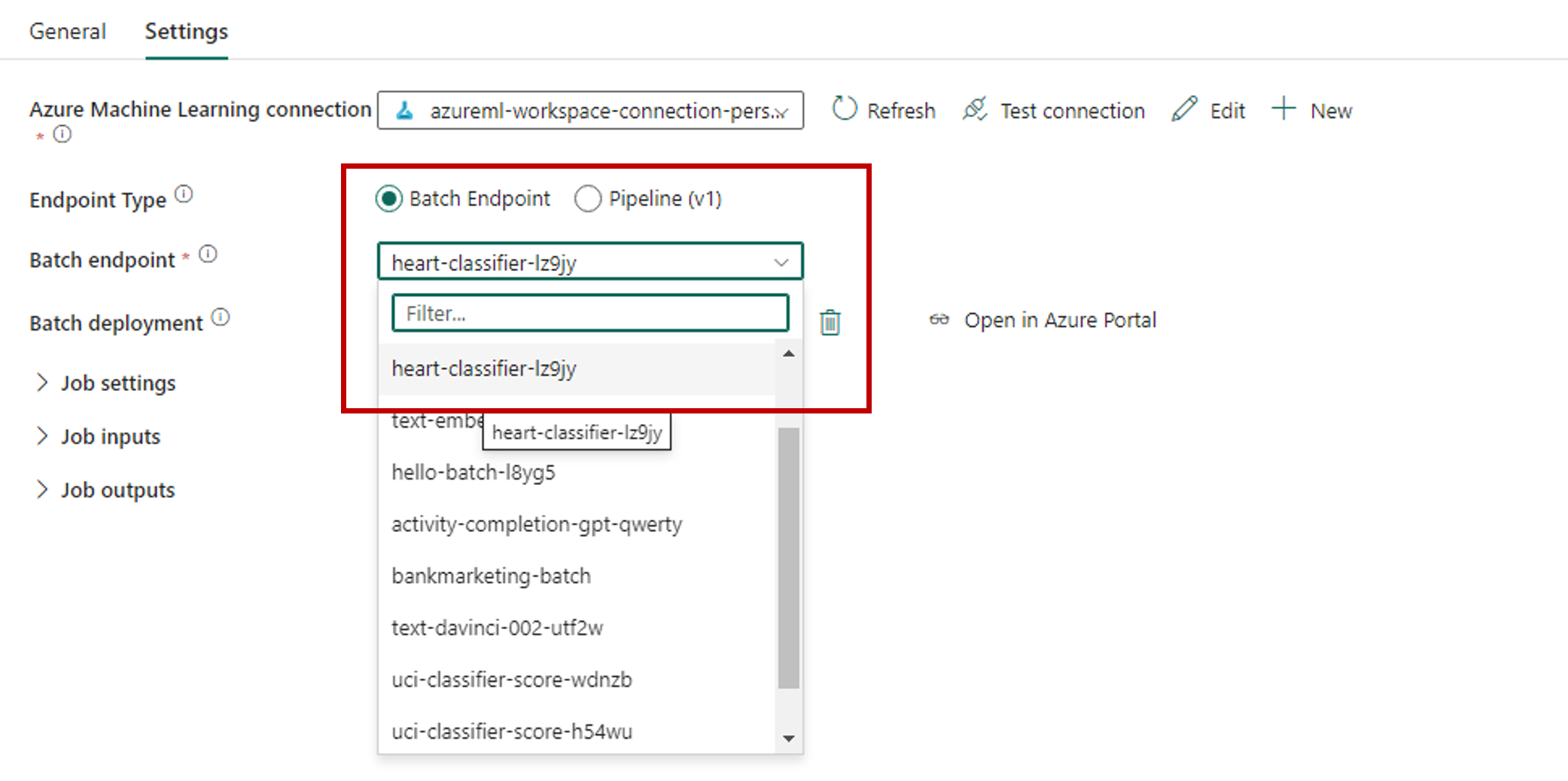
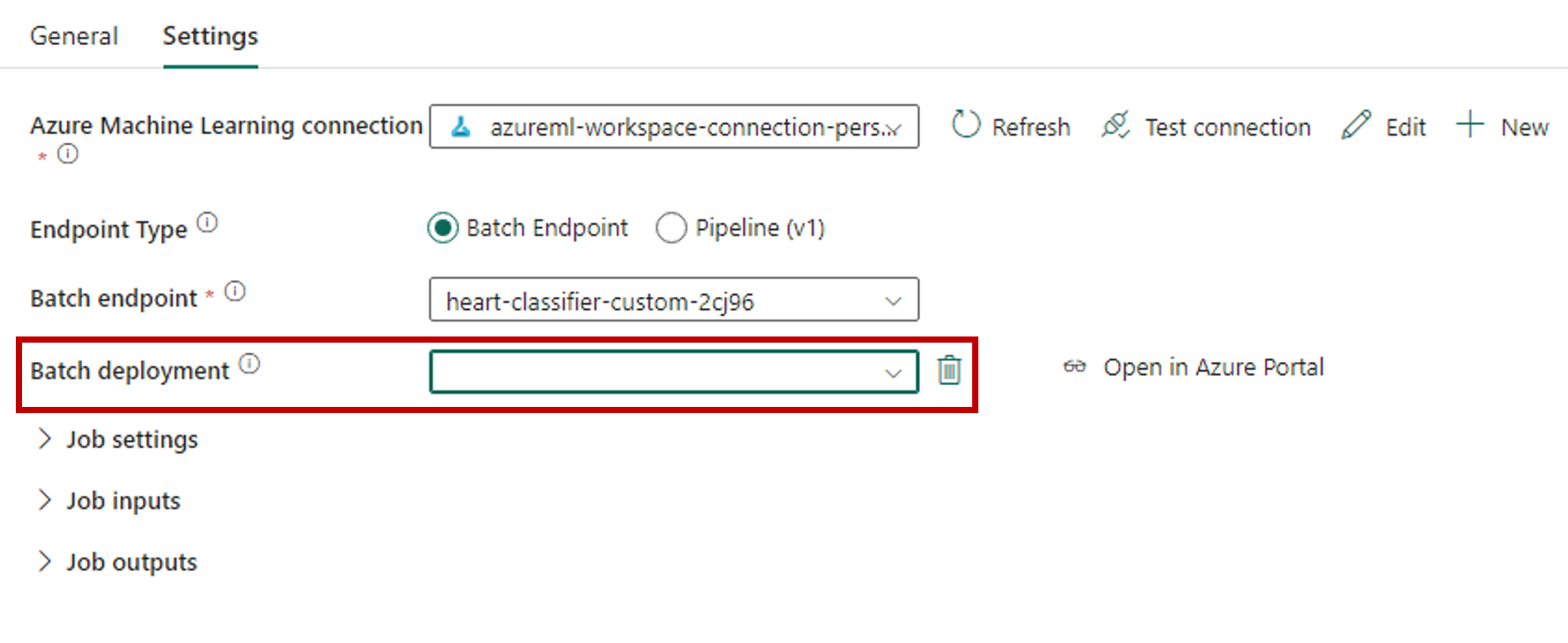
Avsnittet Batch-distribution fylls automatiskt i med tillgängliga distributioner under slutpunkten.
För Batch-distribution väljer du en specifik distribution i listan om det behövs. Om du inte väljer en distribution anropar Fabric standarddistributionen under slutpunkten så att batchslutpunktens skapare kan bestämma vilken distribution som anropas. I de flesta scenarier vill du behålla det här standardbeteendet.







Konfigurera indata och utdata för batchslutpunkten
I det här avsnittet konfigurerar du indata och utdata från batchslutpunkten. Indata till batchslutpunkter innehåller data och parametrar som behövs för att köra processen. Azure Machine Learning-batchpipelinen i Fabric stöder både modelldistributioner och pipelinedistributioner. Antalet och typen av indata som du anger beror på distributionstypen. I det här exemplet använder du en modelldistribution som kräver exakt en indata och genererar en utdata.
Mer information om indata och utdata för batchslutpunkter finns i Förstå indata och utdata i Batch-slutpunkter.
Konfigurera indataavsnittet
Konfigurera avsnittet Jobbindata på följande sätt:
Expandera avsnittet Jobbindata .
Välj Ny för att lägga till en ny indata till slutpunkten.
Ge indata
input_datanamnet . Eftersom du använder en modelldistribution kan du använda valfritt namn. För pipelinedistributioner måste du dock ange det exakta namnet på de indata som din modell förväntar sig.Välj den nedrullningsbara menyn bredvid de indata som du nyss lade till för att öppna indataegenskapen (namn och värdefält).
Ange
JobInputTypei fältet Namn för att ange vilken typ av indata du skapar.Ange
UriFolderi fältet Värde för att ange att indata är en mappsökväg. Andra värden som stöds för det här fältet är UriFile (en filsökväg) eller Literal (valfritt literalvärde som sträng eller heltal). Du måste använda rätt typ som distributionen förväntar sig.Välj plustecknet bredvid egenskapen för att lägga till en annan egenskap för den här indatan.
Ange
Urii fältet Namn för att ange sökvägen till data.Ange
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled, sökvägen för att hitta data i fältet Värde . Här använder du en sökväg som leder till lagringskontot som både är länkat till OneLake i Fabric och till Azure Machine Learning. azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled är sökvägen till CSV-filer med förväntade indata för modellen som distribueras till batchslutpunkten. Du kan också använda en direkt sökväg till lagringskontot, till exempelhttps://<storage-account>.dfs.azure.com.
Dricks
Om dina indata är av typen Literal ersätter du egenskapen
Urimed "Value".
Om slutpunkten kräver fler indata upprepar du föregående steg för var och en av dem. I det här exemplet kräver modelldistributioner exakt en indata.
Konfigurera utdataavsnittet
Konfigurera avsnittet Jobbutdata på följande sätt:
Expandera avsnittet Jobbutdata .
Välj Ny för att lägga till nya utdata i slutpunkten.
Ge dina utdata namnet
output_data. Eftersom du använder en modelldistribution kan du använda valfritt namn. För pipelinedistributioner måste du dock ange det exakta namnet på de utdata som din modell genererar.Välj den nedrullningsbara menyn bredvid de utdata som du nyss lade till för att öppna utdataegenskapen (namn och värdefält).
Ange
JobOutputTypei fältet Namn för att ange vilken typ av utdata du skapar.Ange
UriFilei fältet Värde för att ange att utdata är en filsökväg. Det andra värdet som stöds för det här fältet är UriFolder (en mappsökväg). Till skillnad från avsnittet jobbindata stöds inte Literal (något literalvärde som sträng eller heltal) som utdata.Välj plustecknet bredvid egenskapen för att lägga till en annan egenskap för utdata.
Ange
Urii fältet Namn för att ange sökvägen till data.Ange
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')sökvägen till där utdata ska placeras i fältet Värde . Azure Machine Learning-batchslutpunkter stöder endast användning av datalagersökvägar som utdata. Eftersom utdata måste vara unika för att undvika konflikter har du använt ett dynamiskt uttryck,@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), för att konstruera sökvägen.
Om slutpunkten returnerar fler utdata upprepar du föregående steg för var och en av dem. I det här exemplet genererar modelldistributioner exakt en utdata.
(Valfritt) Konfigurera jobbinställningarna
Du kan också konfigurera jobbinställningarna genom att lägga till följande egenskaper:
För modelldistributioner:
| Inställning | beskrivning |
|---|---|
MiniBatchSize |
Batchens storlek. |
ComputeInstanceCount |
Antalet beräkningsinstanser som ska begäras från distributionen. |
För pipelinedistributioner:
| Inställning | beskrivning |
|---|---|
ContinueOnStepFailure |
Anger om pipelinen ska sluta bearbeta noder efter ett fel. |
DefaultDatastore |
Anger standarddatalagret som ska användas för utdata. |
ForceRun |
Anger om pipelinen ska tvinga alla komponenter att köras även om utdata kan härledas från en tidigare körning. |
När du har konfigurerat kan du testa pipelinen.