Så här väljer du algoritmer för Azure Machine Learning
Om du undrar vilken maskininlärningsalgoritm som ska användas beror svaret främst på två aspekter av ditt datavetenskapsscenario:
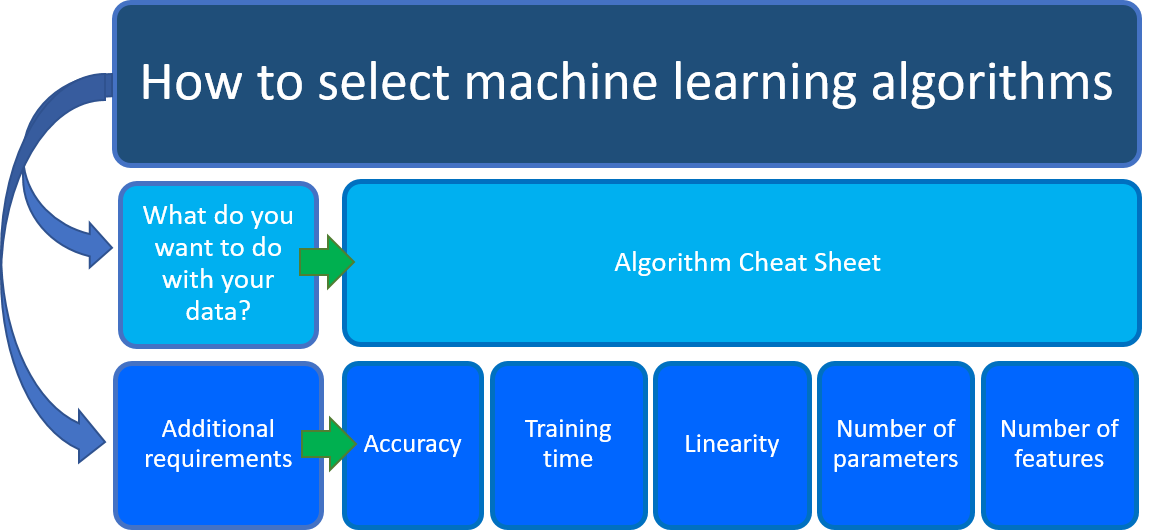
Vad vill du göra med dina data? Mer specifikt, vilken affärsfråga vill du besvara genom att lära dig av dina tidigare data?
Vilka är kraven i ditt datavetenskapsscenario? Vilka är de funktioner, noggrannhet, träningstid, linjäritet och parametrar som din lösning stöder?
Kommentar
Azure Machine Learning-designern stöder två typer av komponenter: klassiska fördefinierade komponenter (v1) och anpassade komponenter (v2). Dessa två typer av komponenter är INTE kompatibla.
Klassiska fördefinierade komponenter är främst för databearbetning och traditionella maskininlärningsuppgifter som regression och klassificering. Den här typen av komponent stöds fortfarande, men inga nya komponenter läggs till.
Med anpassade komponenter kan du omsluta din egen kod som en komponent. De har stöd för delning av komponenter mellan arbetsytor och sömlös redigering i gränssnitten Studio, CLI v2 och SDK v2.
För nya projekt rekommenderar vi starkt att du använder anpassade komponenter som är kompatibla med AzureML V2 och fortsätter att ta emot nya uppdateringar.
Den här artikeln gäller för klassiska fördefinierade komponenter och är inte kompatibel med CLI v2 och SDK v2.
Fuskblad för Azure Machine Learning-algoritm
Azure Machine Learning-algoritmens fuskblad hjälper dig med det första övervägandet: Vad vill du göra med dina data? Leta efter den uppgift du vill göra på fuskbladet och leta sedan upp en Azure Machine Learning-designeralgoritm för lösningen för förutsägelseanalys.
Kommentar
Du kan ladda ned maskininlärningsalgoritmens fuskblad.
Designern tillhandahåller en omfattande portfölj med algoritmer, till exempel Beslutsskog för flera grupper, rekommendationssystem, neural nätverksregression, neuralt nätverk med flera grupper och K-means-klustring. Varje algoritm är utformad för att hantera olika typer av maskininlärningsproblem. Se algoritm- och komponentreferensen för en fullständig lista tillsammans med dokumentation om hur varje algoritm fungerar och hur du justerar parametrar för att optimera algoritmen.
Tillsammans med den här vägledningen bör du ha andra krav i åtanke när du väljer en maskininlärningsalgoritm. Följande är ytterligare faktorer att tänka på, till exempel noggrannhet, träningstid, linjäritet, antal parametrar och antal funktioner.
Jämförelse av maskininlärningsalgoritmer
Vissa algoritmer gör särskilda antaganden om datastrukturen eller önskade resultat. Om du hittar en som passar dina behov kan det ge dig mer användbara resultat, mer exakta förutsägelser eller snabbare träningstider.
I följande tabell sammanfattas några av de viktigaste egenskaperna för algoritmer från klassificerings-, regressions- och klustringsfamiljerna:
| Algoritm | Noggrannhet | Träningstid | Linearitet | Parameters | Anteckningar |
|---|---|---|---|---|---|
| Klassificeringsfamilj | |||||
| Logistisk regression i två klasser | Bra | Snabbt | Ja | 4 | |
| Beslutsskog med två klasser | Utmärkt | Måttlig | Nej | 5 | Visar långsammare bedömningstider. Vi rekommenderar att du inte arbetar med en-mot-alla-multiklass på grund av långsammare bedömningstider som orsakas av trådlåsning i ackumulerande trädförutsägelser |
| Tvåklasssförstärkning av beslutsträd | Utmärkt | Måttlig | Nej | 6 | Stort minnesfotavtryck |
| Neuralt nätverk med två klasser | Bra | Måttlig | Nej | 8 | |
| Genomsnittlig perceptron med två klasser | Bra | Måttlig | Ja | 4 | |
| Stödvektordator med två klasser | Bra | Snabbt | Ja | 5 | Bra för stora funktionsuppsättningar |
| Logistisk regression för flera grupper | Bra | Snabbt | Ja | 4 | |
| Beslutsskog för flera grupper | Utmärkt | Måttlig | Nej | 5 | Visar långsammare bedömningstider |
| Flerklasssförstärkning av beslutsträd | Utmärkt | Måttlig | Nej | 6 | Tenderar att förbättra noggrannheten med viss liten risk för mindre täckning |
| Neuralt nätverk med flera grupper | Bra | Måttlig | Nej | 8 | |
| En-mot-alla-multiklass | - | - | - | - | Se egenskaperna för den valda tvåklassmetoden |
| Regressionsfamilj | |||||
| Linjär regression | Bra | Snabbt | Ja | 4 | |
| Beslutsskogsregression | Utmärkt | Måttlig | Nej | 5 | |
| Förbättrad regression av beslutsträd | Utmärkt | Måttlig | Nej | 6 | Stort minnesfotavtryck |
| Neural nätverksregression | Bra | Måttlig | Nej | 8 | |
| Klustringsfamilj | |||||
| K-means-klustring | Utmärkt | Måttlig | Ja | 8 | En klustringsalgoritm |
Krav för datavetenskapsscenario
När du vet vad du vill göra med dina data måste du fastställa andra krav för ditt datavetenskapsscenario.
Gör val och eventuellt kompromisser för följande krav:
- Noggrannhet
- Träningstid
- Linearitet
- Antal parametrar
- Antal funktioner
Noggrannhet
Noggrannhet i maskininlärning mäter effektiviteten hos en modell som andelen sanna resultat till totala fall. I designern beräknar komponenten Evaluate Model en uppsättning utvärderingsmått av branschstandard. Du kan använda den här komponenten för att mäta noggrannheten för en tränad modell.
Det är inte alltid nödvändigt att få det bästa möjliga svaret. Ibland är en uppskattning tillräcklig, beroende på vad du vill använda den till. Om så är fallet kanske du kan minska bearbetningstiden dramatiskt genom att hålla dig till mer ungefärliga metoder. Ungefärliga metoder tenderar också naturligt att undvika överanpassning.
Det finns tre sätt att använda komponenten Utvärdera modell:
- Generera poäng över dina träningsdata för att utvärdera modellen.
- Generera poäng på modellen, men jämför dessa poäng med poäng på en reserverad testuppsättning.
- Jämför poäng för två olika men relaterade modeller med samma uppsättning data.
En fullständig lista över mått och metoder som du kan använda för att utvärdera noggrannheten för maskininlärningsmodeller finns i Utvärdera modellkomponent.
Träningstid
I övervakad inlärning innebär träning att använda historiska data för att skapa en maskininlärningsmodell som minimerar fel. Antalet minuter eller timmar som krävs för att träna en modell varierar mycket mellan algoritmerna. Träningstiden är ofta nära knuten till noggrannhet; den ena följer vanligtvis med den andra.
Dessutom är vissa algoritmer mer känsliga för antalet datapunkter än andra. Du kan välja en specifik algoritm eftersom du har en tidsbegränsning, särskilt när datamängden är stor.
I designern är det vanligtvis en trestegsprocess att skapa och använda en maskininlärningsmodell:
Konfigurera en modell genom att välja en viss typ av algoritm och sedan definiera dess parametrar eller hyperparametrar.
Ange en datauppsättning som är märkt och har data som är kompatibla med algoritmen. Anslut både data och modellen till komponenten Träna modell.
När träningen har slutförts använder du den tränade modellen med en av bedömningskomponenterna för att göra förutsägelser om nya data.
Linearitet
Linjäritet i statistik och maskininlärning innebär att det finns en linjär relation mellan en variabel och en konstant i datamängden. Till exempel förutsätter linjära klassificeringsalgoritmer att klasser kan avgränsas med en rät linje (eller dess högre dimensionella analog).
Många maskininlärningsalgoritmer använder linjäritet. I Azure Machine Learning-designern inkluderar de:
Linjära regressionsalgoritmer förutsätter att datatrender följer en rak linje. Det här antagandet är inte dåligt för vissa problem, men för andra minskar det noggrannheten. Trots nackdelarna är linjära algoritmer populära som en första strategi. De tenderar att vara algoritmiskt enkla och snabba att träna.
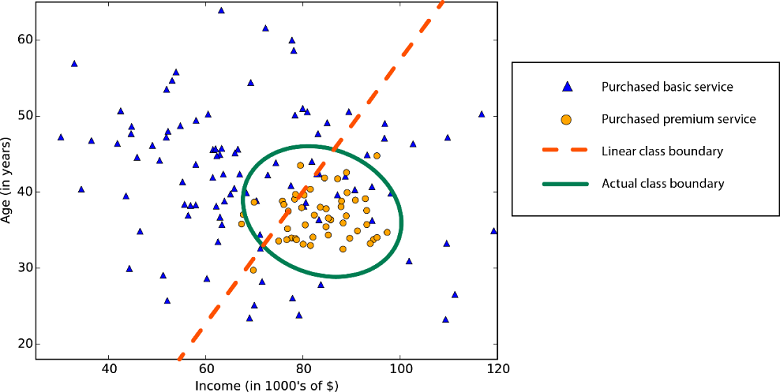
Icke-linjär klassgräns: Att förlita sig på en linjär klassificeringsalgoritm skulle resultera i låg noggrannhet.
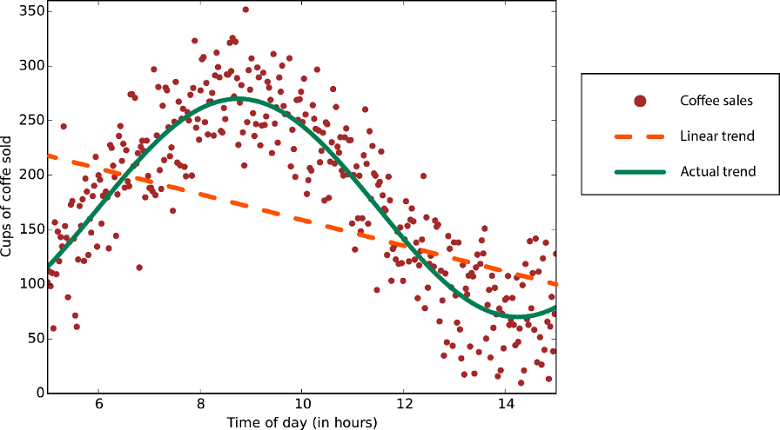
Data med en icke-linjär trend: Om du använder en linjär regressionsmetod genereras mycket större fel än nödvändigt.
Antal parametrar
Parametrar är de rattar som en dataexpert får vända när du konfigurerar en algoritm. Det är tal som påverkar algoritmens beteende, till exempel feltolerans eller antal iterationer, eller alternativ mellan varianter av hur algoritmen beter sig. Algoritmens träningstid och noggrannhet kan ibland vara känslig för att få precis rätt inställningar. Vanligtvis kräver algoritmer med ett stort antal parametrar mest utvärdering och fel för att hitta en bra kombination.
Alternativt finns komponenten Tune Model Hyperparameters i designern. Målet med den här komponenten är att fastställa optimala hyperparametrar för en maskininlärningsmodell. Komponenten bygger och testar flera modeller med hjälp av olika kombinationer av inställningar. Den jämför mått över alla modeller för att få kombinationerna av inställningar.
Även om det här är ett bra sätt att se till att du sträckte dig över parameterutrymmet ökar den tid som krävs för att träna en modell exponentiellt med antalet parametrar. Fördelen är att många parametrar vanligtvis indikerar att en algoritm har större flexibilitet. Det kan ofta uppnå mycket god noggrannhet, förutsatt att du kan hitta rätt kombination av parameterinställningar.
Antal funktioner
I maskininlärning är en funktion en kvantifierbar variabel för fenomenet som du försöker analysera. För vissa typer av data kan antalet funktioner vara mycket stort jämfört med antalet datapunkter. Detta är ofta fallet med genetik eller textdata.
Ett stort antal funktioner kan bogsera vissa inlärningsalgoritmer, vilket gör träningstiden ogenomförbar lång. Stödvektordatorer passar bra för scenarier med ett stort antal funktioner. Därför har de använts i många program från informationshämtning till text- och bildklassificering. Stödvektordatorer kan användas för både klassificerings- och regressionsaktiviteter.
Funktionsval avser processen för att tillämpa statistiska tester på indata, givet ett angivet utdata. Målet är att avgöra vilka kolumner som är mer förutsägande för utdata. Komponenten Filterbaserad funktionsval i designern innehåller flera algoritmer för funktionsval att välja mellan. Komponenten innehåller korrelationsmetoder som Pearson-korrelation och chi-kvadratvärden.
Du kan också använda komponenten Funktionsbetydelse för permutation för att beräkna en uppsättning funktionsviktspoäng för din datamängd. Du kan sedan använda dessa poäng för att avgöra vilka funktioner som är bäst att använda i en modell.