Interaktiv R-utveckling
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Den här artikeln visar hur du använder R i Azure Machine Learning-studio på en beräkningsinstans som kör en R-kernel i en Jupyter Notebook.
Den populära RStudio IDE fungerar också. Du kan installera RStudio eller Posit Workbench i en anpassad container på en beräkningsinstans. Detta har dock begränsningar när det gäller att läsa och skriva till din Azure Machine Learning-arbetsyta.
Viktigt!
Koden som visas i den här artikeln fungerar på en Azure Machine Learning-beräkningsinstans. Beräkningsinstansen har en miljö och konfigurationsfil som krävs för att koden ska kunna köras.
Förutsättningar
- Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning idag
- En Azure Machine Learning-arbetsyta och en beräkningsinstans
- En grundläggande förståelse för hur du använder Jupyter Notebooks i Azure Machine Learning-studio. Mer information finns i Modellutveckling på en molnarbetsstationsresurs .
Kör R i en notebook-fil i studio
Du använder en notebook-fil på din Azure Machine Learning-arbetsyta på en beräkningsinstans.
Logga in på Azure Machine Learning-studio
Öppna arbetsytan om den inte redan är öppen
I det vänstra navigeringsfönstret väljer du Notebooks
Skapa en ny notebook-fil med namnet RunR.ipynb
Dricks
Om du inte är säker på hur du skapar och arbetar med notebook-filer i studio kan du läsa Kör Jupyter-anteckningsböcker på din arbetsyta
Välj anteckningsboken.
Kontrollera att beräkningsinstansen körs i notebook-verktygsfältet. Annars startar du det nu.
I notebook-verktygsfältet växlar du kerneln till R.
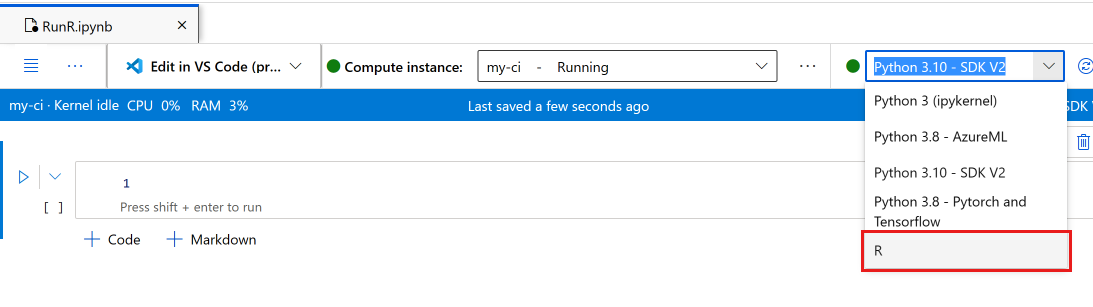

Anteckningsboken är nu redo att köra R-kommandon.
Åtkomst till data
Du kan ladda upp filer till arbetsytans fillagringsresurs och sedan komma åt filerna i R. Men för filer som lagras i Azure-datatillgångar eller data från datalager måste du installera vissa paket.
I det här avsnittet beskrivs hur du använder Python och reticulate paketet för att läsa in dina datatillgångar och datalager i R från en interaktiv session. Du använder Python-paketet azureml-fsspec och reticulate R-paketet för att läsa tabelldata som Pandas DataFrames. Det här avsnittet innehåller också ett exempel på hur du läser datatillgångar och datalager i en R data.frame.
Så här installerar du följande paket:
Skapa en ny fil på beräkningsinstansen med namnet setup.sh.
Kopiera den här koden till filen:
#!/bin/bash set -e # Installs azureml-fsspec in default conda environment # Does not need to run as sudo eval "$(conda shell.bash hook)" conda activate azureml_py310_sdkv2 pip install azureml-fsspec conda deactivate # Checks that version 1.26 of reticulate is installed (needs to be done as sudo) sudo -u azureuser -i <<'EOF' R -e "if (packageVersion('reticulate') >= 1.26) message('Version OK') else install.packages('reticulate')" EOFVälj Spara och kör skript i terminalen för att köra skriptet
Installationsskriptet hanterar följande steg:
pipazureml-fsspecinstallerar i conda-standardmiljön för beräkningsinstansen- Installerar R-paketet
reticulateom det behövs (versionen måste vara 1.26 eller senare)
Läsa tabelldata från registrerade datatillgångar eller datalager
För data som lagras i en datatillgång som skapats i Azure Machine Learning använder du dessa steg för att läsa tabellfilen i en Pandas DataFrame eller en R data.frame:
Kommentar
Läsning av en fil med reticulate fungerar bara med tabelldata.
Kontrollera att du har rätt version av
reticulate. För en version som är mindre än 1,26 kan du försöka använda en nyare beräkningsinstans.packageVersion("reticulate")Läs in
reticulateoch ange conda-miljön därazureml-fsspecinstalleradeslibrary(reticulate) use_condaenv("azureml_py310_sdkv2") print("Environment is set")Hitta URI-sökvägen till datafilen.
Börja med att hämta ett handtag till din arbetsyta
py_code <- "from azure.identity import DefaultAzureCredential from azure.ai.ml import MLClient credential = DefaultAzureCredential() ml_client = MLClient.from_config(credential=credential)" py_run_string(py_code) print("ml_client is configured")Använd den här koden för att hämta tillgången. Ersätt
<MY_NAME>och<MY_VERSION>med namnet och numret på datatillgången.Dricks
I Studio väljer du Data i det vänstra navigeringsfältet för att hitta namnet och versionsnumret för din datatillgång.
# Replace <MY_NAME> and <MY_VERSION> with your values py_code <- "my_name = '<MY_NAME>' my_version = '<MY_VERSION>' data_asset = ml_client.data.get(name=my_name, version=my_version) data_uri = data_asset.path"Kör koden för att hämta URI:n.
py_run_string(py_code) print(paste("URI path is", py$data_uri))
Använd Pandas-läsfunktioner för att läsa filen eller filerna i R-miljön.
pd <- import("pandas") cc <- pd$read_csv(py$data_uri) head(cc)
Du kan också använda en Datastore-URI för att komma åt olika filer på ett registrerat datalager och läsa dessa resurser i en R data.frame.
I det här formatet skapar du en Datastore-URI med dina egna värden:
subscription <- '<subscription_id>' resource_group <- '<resource_group>' workspace <- '<workspace>' datastore_name <- '<datastore>' path_on_datastore <- '<path>' uri <- paste0("azureml://subscriptions/", subscription, "/resourcegroups/", resource_group, "/workspaces/", workspace, "/datastores/", datastore_name, "/paths/", path_on_datastore)Dricks
I stället för att komma ihåg URI-formatet för datalager kan du kopiera och klistra in datalager-URI:n från Studio-användargränssnittet om du vet vilket datalager där filen finns:
- Navigera till den fil/mapp som du vill läsa i R
- Välj elipsis (...) bredvid den.
- Välj på menyn Kopiera URI.
- Välj den Datastore-URI som du vill kopiera till notebook-filen/skriptet.
Observera att du måste skapa en variabel för
<path>i koden.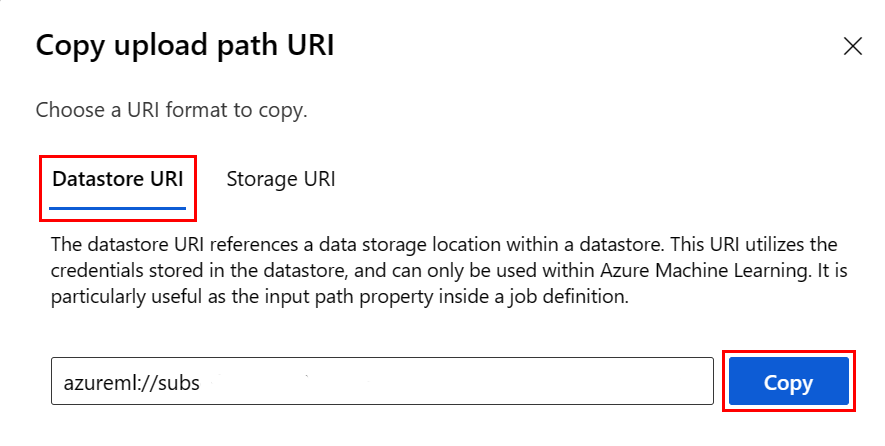
Skapa ett filarkivobjekt med hjälp av den tidigare nämnda URI:n:
fs <- azureml.fsspec$AzureMachineLearningFileSystem(uri, sep = "")
- Läs in i ett R
data.frame:
df <- with(fs$open("<path>)", "r") %as% f, {
x <- as.character(f$read(), encoding = "utf-8")
read.csv(textConnection(x), header = TRUE, sep = ",", stringsAsFactors = FALSE)
})
print(df)
Installera R-paket
En beräkningsinstans har många förinstallerade R-paket.
Om du vill installera andra paket måste du uttryckligen ange plats och beroenden.
Dricks
När du skapar eller använder en annan beräkningsinstans måste du installera om alla paket som du har installerat.
Om du till exempel vill installera tsibble paketet:
install.packages("tsibble",
dependencies = TRUE,
lib = "/home/azureuser")
Kommentar
Om du installerar paket i en R-session som körs i en Jupyter-anteckningsbok dependencies = TRUE krävs. Annars installeras inte beroende paket automatiskt. Lib-platsen krävs också för att installera på rätt plats för beräkningsinstansen.
Läsa in R-bibliotek
Lägg till /home/azureuser I R-bibliotekssökvägen.
.libPaths("/home/azureuser")
Dricks
Du måste uppdatera .libPaths i varje interaktivT R-skript för att få åtkomst till användarinstallerade bibliotek. Lägg till den här koden överst i varje interaktiv R-skript eller notebook-fil.
När libPath har uppdaterats läser du in bibliotek som vanligt.
library('tsibble')
Använda R i notebook-filen
Utöver de problem som beskrevs tidigare använder du R på samma sätt som i andra miljöer, inklusive din lokala arbetsstation. I notebook-filen eller skriptet kan du läsa och skriva till sökvägen där notebook-filen/skriptet lagras.
Kommentar
- Från en interaktiv R-session kan du bara skriva till arbetsytans filsystem.
- Från en interaktiv R-session kan du inte interagera med MLflow (till exempel loggmodell eller frågeregister).