Felsökning av ParallelRunStep
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här artikeln får du lära dig hur du felsöker när du får fel med hjälp av klassen ParallelRunStep från Azure Machine Learning SDK.
Allmänna tips om hur du felsöker en pipeline finns i Felsöka maskininlärningspipelines.
Testa skript lokalt
ParallelRunStep körs som ett steg i ML-pipelines. Du kanske vill testa dina skript lokalt som ett första steg.
Krav för postskript
Postskriptet för en ParallelRunStepmåste innehålla en run() funktion och innehåller eventuellt en init() funktion:
-
init(): Använd den här funktionen för eventuella kostsamma eller vanliga förberedelser för senare bearbetning. Använd den till exempel för att läsa in modellen i ett globalt objekt. Den här funktionen anropas bara en gång i början av processen.Kommentar
Om din
initmetod skapar en utdatakatalog anger du detparents=Trueochexist_ok=True. Metodeninitanropas från varje arbetsprocess på varje nod där jobbet körs. -
run(mini_batch): Funktionen körs för varjemini_batchinstans.-
mini_batch:ParallelRunStepanropar körningsmetoden och skickar antingen en lista eller pandasDataFramesom ett argument till metoden. Varje post i mini_batch kan vara en filsökväg om indata är enFileDataseteller en PandasDataFrameom indata är enTabularDataset. -
response: run()-metoden ska returnera en PandasDataFrameeller en matris. För append_row output_action läggs dessa returnerade element till i den gemensamma utdatafilen. För summary_only ignoreras innehållet i elementen. För alla utdataåtgärder anger varje returnerat utdataelement en lyckad körning av indataelementet i minibatchen för indata. Se till att tillräckligt med data ingår i körningsresultatet för att mappa indata för att köra utdataresultatet. Körningsutdata skrivs i utdatafilen och garanteras inte vara i ordning. Du bör använda en nyckel i utdata för att mappa den till indata.Kommentar
Ett utdataelement förväntas för ett indataelement.
-
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Om du har en annan fil eller mapp i samma katalog som ditt slutsatsdragningsskript kan du referera till den genom att hitta den aktuella arbetskatalogen. Om du vill importera paketen kan du också lägga till paketmappen i sys.path.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
packages_dir = os.path.join(file_path, '<your_package_folder>')
if packages_dir not in sys.path:
sys.path.append(packages_dir)
from <your_package> import <your_class>
Parametrar för ParallelRunConfig
ParallelRunConfig är den viktigaste konfigurationen för ParallelRunStep instansen i Azure Machine Learning-pipelinen. Du använder det för att omsluta skriptet och konfigurera nödvändiga parametrar, inklusive alla följande poster:
entry_script: Ett användarskript som en lokal filsökväg som ska köras parallellt på flera noder. Omsource_directoryfinns ska relativ sökväg användas. Annars använder du alla sökvägar som är tillgängliga på datorn.mini_batch_size: Storleken på mini-batchen som skickas till ett endarun()anrop. (valfritt; standardvärdet är10filer förFileDatasetoch1MBförTabularDataset.)- För
FileDatasetär det antalet filer med ett minsta värde på1. Du kan kombinera flera filer i en mini-batch. - För
TabularDatasetär det storleken på data. Exempelvärden är1024,1024KB,10MBoch1GB. Det rekommenderade värdet är1MB. Mini-batchen frånTabularDatasetkommer aldrig att korsa filgränserna. Om det till exempel finns flera .csv filer med olika storlekar är den minsta 100 kB och den största är 10 MB. Ommini_batch_size = 1MBhar angetts behandlas filerna som är mindre än 1 MB som en mini-batch och filerna som är större än 1 MB delas upp i flera minibatch.Kommentar
TabularDatasets som backas upp av SQL kan inte partitioneras. TabularDatasets från en enskild parquet-fil och en radgrupp kan inte partitioneras.
- För
error_threshold: Antalet postfel förTabularDatasetoch filfel förFileDatasetsom ska ignoreras under bearbetningen. När felantalet för hela indata överskrider det här värdet avbryts jobbet. Tröskelvärdet för fel gäller för hela indata och inte för enskilda minibatch som skickas tillrun()metoden. Intervallet är[-1, int.max].-1anger att alla fel ignoreras under bearbetningen.output_action: Ett av följande värden anger hur utdata organiseras:-
summary_only: Användarskriptet måste lagra utdatafilerna. Utdatarun()från används endast för feltröskelberäkningen. -
append_row: För alla indataParallelRunStepskapar du en enda fil i utdatamappen för att lägga till alla utdata avgränsade med rad.
-
append_row_file_name: Om du vill anpassa utdatafilens namn för append_row output_action (valfritt, ärparallel_run_step.txtstandardvärdet ).source_directory: Sökvägar till mappar som innehåller alla filer som ska köras på beräkningsmålet (valfritt).compute_target: EndastAmlComputestöds.node_count: Antalet beräkningsnoder som ska användas för att köra användarskriptet.process_count_per_node: Antalet arbetsprocesser per nod för att köra inmatningsskriptet parallellt. För en GPU-dator är standardvärdet 1. För en CPU-dator är standardvärdet antalet kärnor per nod. En arbetsprocess anroparrun()upprepade gånger genom att skicka den minibatch som den får som en parameter. Det totala antalet arbetsprocesser i jobbet ärprocess_count_per_node * node_count, som bestämmer det maximala antaletrun()som ska köras parallellt.environment: Python-miljödefinitionen. Du kan konfigurera den så att den använder en befintlig Python-miljö eller för att konfigurera en tillfällig miljö. Definitionen ansvarar också för att ange nödvändiga programberoenden (valfritt).logging_level: Log verbosity. Värden i ökande verbositet är:WARNING,INFOochDEBUG. (valfritt; standardvärdet ärINFO)run_invocation_timeout: Tidsgränsenrun()för metodens anrop i sekunder. (valfritt; standardvärdet är60)run_max_try: Maximalt antalrun()försök för en mini-batch. Arun()misslyckas om ett undantag utlöses eller inget returneras närrun_invocation_timeouthar nåtts (valfritt; standardvärdet är3).
Du kan ange mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeoutoch run_max_try som PipelineParameter, så att du kan finjustera parametervärdena när du skicka en pipelinekörning igen.
SYNLIGHET FÖR CUDA-enheter
För beräkningsmål som är utrustade med GPU:er anges miljövariabeln CUDA_VISIBLE_DEVICES i arbetsprocesser. I AmlCompute hittar du det totala antalet GPU-enheter i miljövariabeln AZ_BATCHAI_GPU_COUNT_FOUND, som anges automatiskt. Om du vill att varje arbetsprocess ska ha en dedikerad GPU anger du process_count_per_node lika med antalet GPU-enheter på en dator. Sedan tilldelas varje arbetsprocess med ett unikt index till CUDA_VISIBLE_DEVICES. När en arbetsprocess stoppas av någon anledning antar nästa påbörjade arbetsprocess det frisläppta GPU-indexet.
När det totala antalet GPU-enheter är mindre än process_count_per_nodekan arbetsprocesserna med mindre index tilldelas GPU-index tills alla GPU:er har ockuperats.
Med tanke på att det totala antalet GPU-enheter är 2 och process_count_per_node = 4 som exempel tar process 0 och process 1 index 0 och 1. Process 2 och 3 har inte miljövariabeln. För ett bibliotek som använder den här miljövariabeln för GPU-tilldelning har process 2 och 3 inte GPU:er och försöker inte hämta GPU-enheter. Process 0 släpper GPU-index 0 när det stoppas. Nästa process om tillämpligt, som är process 4, har GPU-index 0 tilldelat.
Mer information finns i CUDA Pro-tips: Kontrollera GPU-synlighet med CUDA_VISIBLE_DEVICES.
Parametrar för att skapa ParallelRunStep
Skapa ParallelRunStep med hjälp av skriptet, miljökonfigurationen och parametrarna. Ange det beräkningsmål som du redan har kopplat till din arbetsyta som mål för körningen för ditt slutsatsdragningsskript. Använd ParallelRunStep för att skapa steget för batchinferenspipeline, som tar alla följande parametrar:
-
name: Namnet på steget med följande namngivningsbegränsningar: unikt, 3–32 tecken och regex ^[a-z]([-a-z0-9]*[a-z0-9])?$. -
parallel_run_config: EttParallelRunConfigobjekt enligt definitionen tidigare. -
inputs: En eller flera Azure Machine Learning-datauppsättningar som ska partitioneras för parallell bearbetning. -
side_inputs: En eller flera referensdata eller datauppsättningar som används som sidoindata utan att behöva partitioneras. -
output: EttOutputFileDatasetConfigobjekt som representerar katalogsökvägen där utdata ska lagras. -
arguments: En lista med argument som skickas till användarskriptet. Använd unknown_args för att hämta dem i ditt postskript (valfritt). -
allow_reuse: Om steget ska återanvända tidigare resultat när det körs med samma inställningar/indata. Om den här parametern ärFalsegenereras alltid en ny körning för det här steget under pipelinekörningen. (valfritt; standardvärdet ärTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Felsöka skript från fjärrkontext
Övergången från att felsöka ett bedömningsskript lokalt till att felsöka ett bedömningsskript i en faktisk pipeline kan vara ett svårt steg. Information om hur du hittar loggarna i portalen finns i avsnittet pipelines för maskininlärning om felsökning av skript från en fjärrkontext. Information i det avsnittet gäller även för en ParallelRunStep.
På grund av den distribuerade typen av ParallelRunStep-jobb finns det loggar från flera olika källor. Två konsoliderade filer skapas dock som ger information på hög nivå:
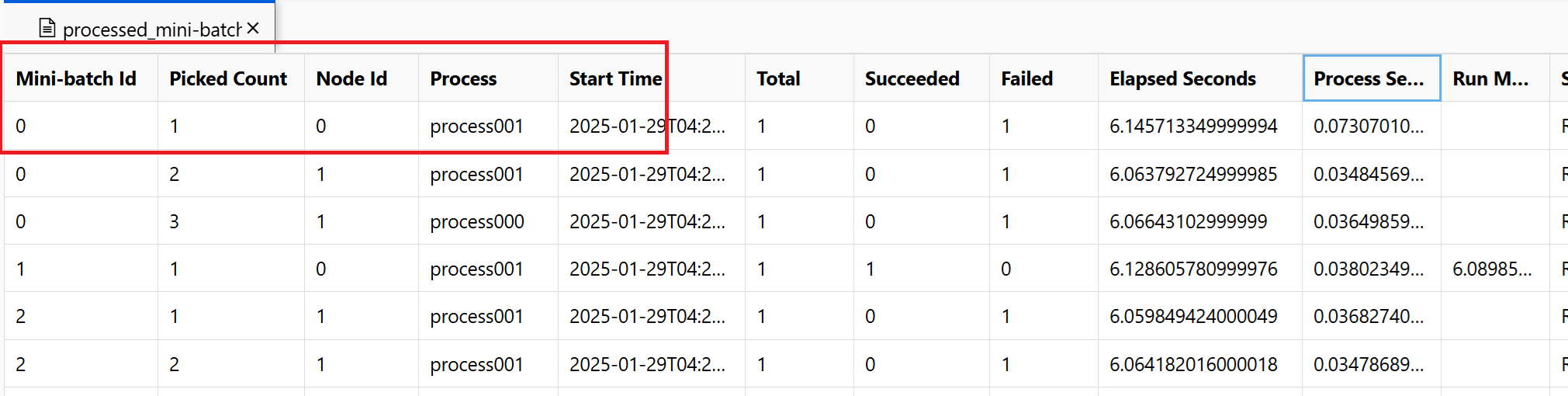
~/logs/job_progress_overview.txt: Den här filen innehåller information på hög nivå om antalet minibatch (även kallade uppgifter) som skapats hittills och antalet minibatch som bearbetats hittills. I det här slutet visar den resultatet av jobbet. Om jobbet misslyckas visas felmeddelandet och var felsökningen ska startas.~/logs/job_result.txt: Det visar resultatet av jobbet. Om jobbet misslyckades visas felmeddelandet och var felsökningen ska startas.~/logs/job_error.txt: Den här filen sammanfattar felen i skriptet.~/logs/sys/master_role.txt: Den här filen innehåller huvudnoden (även kallad orchestrator) för det jobb som körs. Innehåller uppgiftsskapande, förloppsövervakning, körningsresultatet.~/logs/sys/job_report/processed_mini-batches.csv: En tabell med alla minibatcher som har bearbetats. Den visar resultatet av varje körning av minibatch, dess körningsagentnod-ID och processnamn. Dessutom ingår den förflutna tiden och felmeddelandena. Loggar för varje körning av minibatcher kan hittas genom att följa nod-ID:t och processnamnet.
Loggar som genereras från postskript med hjälp av EntryScript-hjälpen och utskriftsinstruktioner finns i följande filer:
~/logs/user/entry_script_log/<node_id>/<process_name>.log.txt: Dessa filer är loggarna som skrivits från entry_script med hjälp av EntryScript.~/logs/user/stdout/<node_id>/<process_name>.stdout.txt: Dessa filer är loggarna från stdout (till exempel utskriftsinstruktor) för entry_script.~/logs/user/stderr/<node_id>/<process_name>.stderr.txt: Dessa filer är loggarna från stderr för entry_script.
Skärmbilden visar till exempel att minibatch 0 misslyckades på noden 0 process001. Motsvarande loggar för ditt postskript finns i ~/logs/user/entry_script_log/0/process001.log.txt, ~/logs/user/stdout/0/process001.log.txt och ~/logs/user/stderr/0/process001.log.txt
När du behöver en fullständig förståelse för hur varje nod körde poängskriptet kan du titta på de enskilda processloggarna för varje nod. Processloggarna finns i ~/logs/sys/node mappen, grupperade efter arbetsnoder:
~/logs/sys/node/<node_id>/<process_name>.txt: Den här filen innehåller detaljerad information om varje mini-batch som plockades upp eller slutfördes av en arbetare. För varje mini-batch innehåller den här filen:- IP-adressen och PID för arbetsprocessen.
- Det totala antalet objekt, antalet bearbetade objekt och antalet misslyckade objekt.
- Starttid, varaktighet, processtid och körningsmetodtid.
Du kan också visa resultatet av regelbundna kontroller av resursanvändningen för varje nod. Loggfilerna och installationsfilerna finns i den här mappen:
~/logs/perf: Ställ in--resource_monitor_intervalför att ändra kontrollintervallet i sekunder. Standardintervallet är600, vilket är cirka 10 minuter. Om du vill stoppa övervakningen anger du värdet till0. Varje<node_id>mapp innehåller:-
os/: Information om alla processer som körs i noden. En kontroll kör ett operativsystemkommando och sparar resultatet i en fil. I Linux ärpskommandot . I Windows använder dutasklist.-
%Y%m%d%H: Undermappens namn är tid till timme.-
processes_%M: Filen slutar med minut för kontrolltiden.
-
-
-
node_disk_usage.csv: Detaljerad diskanvändning av noden. -
node_resource_usage.csv: Resursanvändningsöversikt över noden. -
processes_resource_usage.csv: Översikt över resursanvändning för varje process.
-
Vanliga orsaker till jobbfel
SystemExit: 42
Utgångarna 41 och 42 är PRS-utformade slutkoder. Arbetsnoder avslutas med 41 för att meddela beräkningshanteraren att den avslutades oberoende av varandra. Det är förväntat. En ledarnod kan avslutas med 0 eller 42, vilket anger jobbresultatet. Avslut 42 innebär att jobbet misslyckades. Felorsaken finns i ~/logs/job_result.txt. Du kan följa föregående avsnitt för att felsöka jobbet.
Databehörighet
Fel i jobbet anger att beräkningen inte kan komma åt indata. Om identitetsbaserad används för ditt beräkningskluster och lagring kan du läsa Identitetsbaserad dataautentisering.
Processer avslutades oväntat
Processer kan krascha på grund av oväntade eller ohanterade undantag, systemet avlivar processer på grund av undantag om slut på minne. I PRS-systemloggar ~/logs/sys/node/<node-id>/_main.txtkan du hitta fel som nedan.
<process-name> exits with returncode -9.
Slut på minne
~/logs/perf loggar beräkningsresursförbrukning för processer. Minnesanvändningen för varje uppgiftsprocessor finns. Du kan uppskatta den totala minnesanvändningen på noden.
Fel om slut på minne finns i ~/system_logs/lifecycler/<node-id>/execution-wrapper.txt.
Vi föreslår att du minskar antalet processer per nod eller uppgraderar vm-storleken om beräkningsresurserna stänger gränserna.
Ohanterade undantag
I vissa fall kan python-processerna inte fånga den misslyckade stacken. Du kan lägga till en miljövariabel env["PYTHONFAULTHANDLER"]="true" för att aktivera en inbyggd python-felhanterare.
Minibatch Timeout
Du kan justera run_invocation_timeout argumentet enligt dina minibatch-uppgifter. Här följer några tips när du ser att körningsfunktionerna () tar längre tid än förväntat.
Kontrollera den förflutna tiden och processtiden för minibatchen. Processtiden mäter processortiden för processen. När processtiden är betydligt kortare än förflutit kan du kontrollera om det finns några tunga I/O-åtgärder eller nätverksbegäranden i aktiviteterna. Långa svarstider för dessa åtgärder är den vanliga orsaken till minibatch-timeout.
Vissa specifika minibatcher tar längre tid än andra. Du kan antingen uppdatera konfigurationen eller prova att arbeta med indata för att balansera bearbetningstiden för minibatch.
Hur gör jag för att logg från mitt användarskript från en fjärrkontext?
ParallelRunStep kan köra flera processer på en nod baserat på process_count_per_node. För att organisera loggar från varje process på noden och kombinera utskrifts- och logginstruktor rekommenderar vi ParallelRunStep-loggning som visas nedan. Du får en loggning från EntryScript och gör så att loggarna visas i loggar/användarmappen i portalen.
Ett exempelinmatningsskript med hjälp av loggern:
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
logger = entry_script.logger
logger.info("This will show up in files under logs/user on the Azure portal.")
def run(mini_batch):
"""Call once for a mini batch. Accept and return the list back."""
# This class is in singleton pattern. It returns the same instance as the one in init()
entry_script = EntryScript()
logger = entry_script.logger
logger.info(f"{__file__}: {mini_batch}.")
...
return mini_batch
Var sjunker meddelandet från Python logging till?
ParallelRunStep anger en hanterare på rotloggaren, som sänker meddelandet till logs/user/stdout/<node_id>/processNNN.stdout.txt.
logging standardvärdet för nivå INFO . Som standard visas inte nivåerna nedan INFO , till exempel DEBUG.
Hur kan jag skriva till en fil som ska visas i portalen?
Filer som skrivs till /logs mappen laddas upp och visas i portalen.
Du kan hämta mappen logs/user/entry_script_log/<node_id> som nedan och skriva din filsökväg för att skriva:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
log_dir = entry_script.log_dir
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
fil_path = log_dir / f"{proc_name}_<file_name>" # Avoid conflicting among worker processes with proc_name.
Hur hanterar jag inloggning i nya processer?
Du kan skapa nya processer i ditt inmatningsskript med subprocess modulen, ansluta till deras indata-/utdata-/felpipor och hämta deras returkoder.
Den rekommenderade metoden är att använda run() funktionen med capture_output=True. Fel visas i logs/user/error/<node_id>/<process_name>.txt.
Om du vill använda Popen()ska stdout/stderr omdirigeras till filer, till exempel:
from pathlib import Path
from subprocess import Popen
from azureml_user.parallel_run import EntryScript
def init():
"""Show how to redirect stdout/stderr to files in logs/user/entry_script_log/<node_id>/."""
entry_script = EntryScript()
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
stdout_file = str(log_dir / f"{proc_name}_demo_stdout.txt")
stderr_file = str(log_dir / f"{proc_name}_demo_stderr.txt")
proc = Popen(
["...")],
stdout=open(stdout_file, "w"),
stderr=open(stderr_file, "w"),
# ...
)
Kommentar
En arbetsprocess kör "system"-kod och postskriptkoden i samma process.
Om inget stdout eller stderr anges ärvs inställningen för arbetsprocessen av underprocesser som skapas med Popen() i ditt postskript.
stdout skriver till ~/logs/sys/node/<node_id>/processNNN.stdout.txt och stderr till ~/logs/sys/node/<node_id>/processNNN.stderr.txt.
Hur gör jag för att skriva en fil till utdatakatalogen och sedan visa den i portalen?
Du kan hämta utdatakatalogen från EntryScript klassen och skriva till den. Om du vill visa de skrivna filerna går du till steget Kör i Azure Machine Learning-portalen och väljer fliken Utdata + loggar . Välj länken Datautdata och slutför sedan de steg som beskrivs i dialogrutan.
Använd EntryScript i ditt postskript som i det här exemplet:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def run(mini_batch):
output_dir = Path(entry_script.output_dir)
(Path(output_dir) / res1).write...
(Path(output_dir) / res2).write...
Hur kan jag skicka en sidoinmatning, till exempel en fil eller filer som innehåller en uppslagstabell, till alla mina arbetare?
Användaren kan skicka referensdata till skript med hjälp av side_inputs parametern ParalleRunStep. Alla datauppsättningar som tillhandahålls som side_inputs monteras på varje arbetsnod. Användaren kan hämta monteringsplatsen genom att skicka argument.
Konstruera en datauppsättning som innehåller referensdata, ange en lokal monteringssökväg och registrera den med din arbetsyta. Skicka den till parametern side_inputs för din ParallelRunStep. Dessutom kan du lägga till sökvägen i arguments avsnittet för att enkelt komma åt den monterade sökvägen.
Kommentar
Använd endast FileDatasets för side_inputs.
local_path = "/tmp/{}".format(str(uuid.uuid4()))
label_config = label_ds.as_named_input("labels_input").as_mount(local_path)
batch_score_step = ParallelRunStep(
name=parallel_step_name,
inputs=[input_images.as_named_input("input_images")],
output=output_dir,
arguments=["--labels_dir", label_config],
side_inputs=[label_config],
parallel_run_config=parallel_run_config,
)
Därefter kan du komma åt den i skriptet (till exempel i init()-metoden på följande sätt:
parser = argparse.ArgumentParser()
parser.add_argument('--labels_dir', dest="labels_dir", required=True)
args, _ = parser.parse_known_args()
labels_path = args.labels_dir
Hur använder du indatauppsättningar med autentisering med tjänstens huvudnamn?
Användaren kan skicka indatauppsättningar med autentisering med tjänstens huvudnamn som används på arbetsytan. Om du använder en sådan datauppsättning i ParallelRunStep måste datauppsättningen registreras för att den ska kunna konstruera ParallelRunStep-konfiguration.
service_principal = ServicePrincipalAuthentication(
tenant_id="***",
service_principal_id="***",
service_principal_password="***")
ws = Workspace(
subscription_id="***",
resource_group="***",
workspace_name="***",
auth=service_principal
)
default_blob_store = ws.get_default_datastore() # or Datastore(ws, '***datastore-name***')
ds = Dataset.File.from_files(default_blob_store, '**path***')
registered_ds = ds.register(ws, '***dataset-name***', create_new_version=True)
Så här kontrollerar du förloppet och analyserar det
Det här avsnittet handlar om hur du kontrollerar förloppet för ett ParallelRunStep-jobb och kontrollerar orsaken till ett oväntat beteende.
Så här kontrollerar du jobbets förlopp?
Förutom att titta på den övergripande statusen för StepRun kan antalet schemalagda/bearbetade minibatchs och förloppet för att generera utdata visas i ~/logs/job_progress_overview.<timestamp>.txt. Filen roterar dagligen. Du kan kontrollera den med den största tidsstämpeln för den senaste informationen.
Vad ska jag kontrollera om det inte finns några framsteg på ett tag?
Du kan gå in ~/logs/sys/error för att se om det finns något undantag. Om det inte finns någon är det troligt att ditt postskript tar lång tid, du kan skriva ut förloppsinformation i koden för att hitta den tidskrävande delen eller lägga till "--profiling_module", "cProfile"arguments i för ParallelRunStep att generera en profilfil med namnet under <process_name>.profile~/logs/sys/node/<node_id> mappen.
När stoppas ett jobb?
Om det inte avbryts kan jobbet sluta med status:
- Slutförd. Alla mini-batchar bearbetas och utdata genereras för
append_rowläge. - Misslyckades. Om
error_thresholdinParameters for ParallelRunConfigöverskrids eller om systemfel uppstår under jobbet.
Var hittar du rotorsaken till felet?
Du kan följa leadet i ~/logs/job_result.txt för att hitta orsaksloggen och den detaljerade felloggen.
Påverkar nodfelet jobbresultatet?
Inte om det finns andra tillgängliga noder i det avsedda beräkningsklustret. ParallelRunStep kan köras separat på varje nod. Ett fel med en nod misslyckas inte i hela jobbet.
Vad händer om init funktionen i inmatningsskriptet misslyckas?
ParallelRunStep har en mekanism för att försöka igen under en viss tid för att ge möjlighet till återställning från tillfälliga problem utan att fördröja jobbfelet för länge. Mekanismen är följande:
- Om när en nod startar
initslutar vi att försöka efter3 * process_count_per_nodefel på alla agenter. - Om jobbet startar
initpå alla agenter för alla noder fortsätter att misslyckas, kommer vi att sluta försöka om jobbet körs mer än 2 minuter och det finns2 * node_count * process_count_per_nodefel. - Om alla agenter har fastnat i
initmer än3 * run_invocation_timeout + 30sekunder misslyckas jobbet på grund av att inga förlopp har gjorts för länge.
Vad händer på OutOfMemory? Hur kan jag kontrollera orsaken?
Processen kan avslutas av systemet. ParallelRunStep anger det aktuella försöket att bearbeta mini-batchen till felstatus och försöker starta om den misslyckade processen. Du kan söka efter ~logs/perf/<node_id> den minneskrävande processen.
Varför har jag många processNNN-filer?
ParallelRunStep startar nya arbetsprocesser i stället för de som avslutas onormalt. Och varje process genererar en uppsättning processNNN filer som logg. Men om processen misslyckades på grund av ett undantag under init funktionen för användarskriptet, och felet upprepas kontinuerligt under 3 * process_count_per_node tider, startas ingen ny arbetsprocess.
Nästa steg
Se de här Jupyter-notebook-filerna som demonstrerar Azure Machine Learning-pipelines
Se SDK-referensen för hjälp med paketet azureml-pipeline-steps .
Visa referensdokumentation för klassen ParallelRunConfig och dokumentationen för klassen ParallelRunStep.
Följ den avancerade självstudien om hur du använder pipelines med ParallelRunStep. Självstudien visar hur du skickar en annan fil som en sidoinmatning.