Skapa bedömningsskript för batchdistributioner
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Med batchslutpunkter kan du distribuera modeller som utför långvarig slutsatsdragning i stor skala. När du distribuerar modeller måste du skapa och ange ett bedömningsskript (även kallat ett batchdrivrutinsskript) för att ange hur du använder det via indata för att skapa förutsägelser. I den här artikeln får du lära dig hur du använder bedömningsskript i modelldistributioner för olika scenarier. Du får också lära dig mer om metodtips för batchslutpunkter.
Dricks
MLflow-modeller kräver inte ett bedömningsskript. Den genereras automatiskt åt dig. Mer information om hur batchslutpunkter fungerar med MLflow-modeller finns i självstudiekursen Använda MLflow-modeller i batchdistributioner .
Varning
Om du vill distribuera en automatiserad ML-modell under en batchslutpunkt bör du tänka på att automatiserad ML tillhandahåller ett bedömningsskript som endast fungerar för onlineslutpunkter. Det bedömningsskriptet är inte utformat för batchkörning. Följ dessa riktlinjer om du vill ha mer information om hur du skapar ett bedömningsskript, anpassat för vad din modell gör.
Förstå bedömningsskriptet
Bedömningsskriptet är en Python-fil (.py) som anger hur modellen ska köras och läser indata som batchdistributionskörningen skickar. Varje modelldistribution tillhandahåller bedömningsskriptet (tillsammans med alla andra nödvändiga beroenden) när den skapas. Bedömningsskriptet ser vanligtvis ut så här:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
Bedömningsskriptet måste innehålla två metoder:
Metoden init
init() Använd metoden för alla kostsamma eller vanliga förberedelser. Använd den till exempel för att läsa in modellen i minnet. Starten av hela batchjobbet anropar den här funktionen en gång. Filerna i din modell är tillgängliga i en sökväg som bestäms av miljövariabeln AZUREML_MODEL_DIR. Beroende på hur din modell har registrerats kan dess filer finnas i en mapp. I nästa exempel har modellen flera filer i en mapp med namnet model. Mer information finns i hur du kan fastställa vilken mapp som din modell använder.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
I det här exemplet placerar vi modellen i den globala variabeln model. Använd globala variabler för att göra de tillgångar som krävs för att utföra slutsatsdragning på bedömningsfunktionen tillgängliga.
Metoden run
run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] Använd metoden för att hantera bedömning av varje mini-batch som batchdistributionen genererar. Den här metoden anropas en gång för varje mini_batch som genereras för dina indata. Batchdistributioner läser data i batchar beroende på hur distributionskonfigurationen.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
Metoden tar emot en lista över filsökvägar som en parameter (mini_batch). Du kan använda den här listan för att iterera över och individuellt bearbeta varje fil, eller för att läsa hela batchen och bearbeta allt på en gång. Det bästa alternativet beror på ditt beräkningsminne och det dataflöde du behöver uppnå. Ett exempel som beskriver hur du läser hela batchar med data samtidigt finns i Distributioner med högt dataflöde.
Kommentar
Hur distribueras arbetet?
Batchdistributioner distribuerar arbete på filnivå, vilket innebär att en mapp som innehåller 100 filer, med mini-batchar med 10 filer, genererar 10 batchar med 10 filer vardera. Observera att storleken på de relevanta filerna inte har någon relevans. För filer som är för stora för att bearbetas i stora minibatch föreslår vi att du antingen delar upp filerna i mindre filer för att uppnå en högre nivå av parallellitet eller minskar antalet filer per mini-batch. För närvarande kan batchdistribution inte ta hänsyn till skevhet i filens storleksfördelning.
Metoden run() bör returnera en Pandas DataFrame eller en matris/lista. Varje returnerat utdataelement anger en lyckad körning av ett indataelement i indata mini_batch. För fil- eller mappdatatillgångar representerar varje returnerad rad/element en enskild fil som bearbetas. För en tabelldatatillgång representerar varje returnerad rad/element en rad i en bearbetad fil.
Viktigt!
Hur skriver jag förutsägelser?
Allt som run() funktionen returnerar läggs till i utdataförutsägelsefilen som batchjobbet genererar. Det är viktigt att returnera rätt datatyp från den här funktionen. Returnera matriser när du behöver mata ut en enda förutsägelse. Returnera Pandas DataFrames när du behöver returnera flera informationsdelar. För tabelldata kanske du till exempel vill lägga till dina förutsägelser i den ursprungliga posten. Använd en Pandas DataFrame för att göra detta. Även om en Pandas DataFrame kan innehålla kolumnnamn innehåller utdatafilen inte dessa namn.
om du vill skriva förutsägelser på ett annat sätt kan du anpassa utdata i batchdistributioner.
Varning
I funktionen run ska du inte mata ut komplexa datatyper (eller listor med komplexa datatyper) i stället för pandas.DataFrame. Dessa utdata omvandlas till strängar och blir svåra att läsa.
Den resulterande dataramen eller matrisen läggs till i den angivna utdatafilen. Det finns inget krav på resultatets kardinalitet. En fil kan generera 1 eller många rader/element i utdata. Alla element i resultatdataramen eller matrisen skrivs till utdatafilen som den är (med tanke på output_action att inte summary_onlyär ).
Python-paket för bedömning
Du måste ange alla bibliotek som ditt bedömningsskript kräver för att köras i den miljö där batchdistributionen körs. För bedömningsskript anges miljöer per distribution. Vanligtvis anger du dina krav med hjälp av en conda.yml beroendefil, som kan se ut så här:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Besök Skapa en batchdistribution för mer information om hur du anger miljön för din modell.
Skriva förutsägelser på ett annat sätt
Som standard skriver batchdistributionen modellens förutsägelser i en enda fil som anges i distributionen. I vissa fall måste du dock skriva förutsägelserna i flera filer. För partitionerade indata skulle du till exempel förmodligen också vilja generera partitionerade utdata. I dessa fall kan du anpassa utdata i batchdistributioner för att ange:
- Filformatet (CSV, parquet, json osv.) som används för att skriva förutsägelser
- Hur data partitioneras i utdata
Gå till Anpassa utdata i batchdistributioner för mer information om hur du uppnår det.
Källkontroll för bedömningsskript
Det är mycket lämpligt att placera bedömningsskript under källkontroll.
Metodtips för att skriva bedömningsskript
När du skriver bedömningsskript som hanterar stora mängder data måste du ta hänsyn till flera faktorer, inklusive
- Storleken på varje fil
- Mängden data på varje fil
- Mängden minne som krävs för att läsa varje fil
- Mängden minne som krävs för att läsa en hel uppsättning filer
- Modellens minnesfotavtryck
- Modellminnets fotavtryck när de körs över indata
- Det tillgängliga minnet i din beräkning
Batchdistributioner distribuerar arbete på filnivå. Det innebär att en mapp som innehåller 100 filer, i mini-batchar med 10 filer, genererar 10 batchar med 10 filer vardera (oavsett storleken på de aktuella filerna). För filer som är för stora för att bearbetas i stora mini-batchar rekommenderar vi att du delar upp filerna i mindre filer, uppnår en högre nivå av parallellitet eller att du minskar antalet filer per mini-batch. För närvarande kan batchdistribution inte ta hänsyn till skevhet i filens storleksfördelning.
Relation mellan graden av parallellitet och bedömningsskriptet
Distributionskonfigurationen styr både storleken på varje mini-batch och antalet arbetare på varje nod. Detta blir viktigt när du bestämmer om du vill läsa hela mini-batchen för att utföra slutsatsdragning, köra slutsatsdragningsfilen efter fil eller köra slutsatsdragningsraden efter rad (för tabell). Mer information finns i Köra slutsatsdragning på mini-batch-, fil- eller radnivå .
När du kör flera arbetare på samma instans bör du ta hänsyn till att minnet delas mellan alla arbetare. En ökning av antalet arbetare per nod bör vanligtvis åtfölja en minskning av mini-batchstorleken, eller genom en ändring i bedömningsstrategin om datastorleken och beräknings-SKU:n förblir desamma.
Köra slutsatsdragning på mini-batch-, fil- eller radnivå
Batchslutpunkter anropar run() funktionen i ett bedömningsskript en gång per mini-batch. Du kan dock bestämma om du vill köra slutsatsdragningen över hela batchen, över en fil i taget eller över en rad i taget för tabelldata.
Mini-batch-nivå
Du vill vanligtvis köra slutsatsdragning över batchen på en gång för att uppnå högt dataflöde i batchbedömningsprocessen. Detta händer om du kör slutsatsdragning över en GPU, där du vill uppnå mättnad av slutsatsdragningsenheten. Du kan också förlita dig på en datainläsare som kan hantera själva batchbearbetningen om data inte passar för minne, som TensorFlow eller PyTorch datainläsare. I dessa fall kanske du vill köra slutsatsdragning på hela batchen.
Varning
Att köra slutsatsdragning på batchnivå kan kräva noggrann kontroll över indatastorleken, för att korrekt ta hänsyn till minneskraven och för att undvika undantag som inte finns i minnet. Om du kan läsa in hela mini-batchen i minnet beror på storleken på mini-batchen, storleken på instanserna i klustret, antalet arbetare på varje nod och storleken på mini-batchen.
Gå till Distributioner med högt dataflöde för att lära dig hur du gör detta. I det här exemplet bearbetas en hel uppsättning filer åt gången.
Filnivå
Ett av de enklaste sätten att utföra slutsatsdragning är iteration över alla filer i mini-batchen och kör sedan modellen över den. I vissa fall, till exempel bildbearbetning, kan det vara en bra idé. För tabelldata kan du behöva göra en bra uppskattning av antalet rader i varje fil. Den här uppskattningen kan visa om din modell kan hantera minneskraven för att både läsa in hela data i minnet och utföra slutsatsdragningar över dem. Vissa modeller (särskilt de modeller som baseras på återkommande neurala nätverk) utvecklar och presenterar ett minnesfotavtryck med ett potentiellt icke-linjärt radantal. För en modell med hög minneskostnad bör du överväga att köra slutsatsdragning på radnivå.
Dricks
Överväg att dela upp filer som är för stora för att kunna läsas samtidigt i flera mindre filer för att ta hänsyn till bättre parallellisering.
Gå till Bildbearbetning med batchdistributioner för att lära dig hur du gör detta. Det exemplet bearbetar en fil i taget.
Radnivå (tabell)
För modeller som utgör utmaningar med deras indatastorlekar kanske du vill köra slutsatsdragning på radnivå. Batchdistributionen ger fortfarande ditt bedömningsskript en mini-batch med filer. Men du läser en fil, en rad i taget. Detta kan verka ineffektivt, men för vissa djupinlärningsmodeller kan det vara det enda sättet att dra slutsatser utan att skala upp maskinvaruresurserna.
Gå till Textbearbetning med batchdistributioner för att lära dig hur du gör detta. Det exemplet bearbetar en rad i taget.
Använda modeller som är mappar
Miljövariabeln AZUREML_MODEL_DIR innehåller sökvägen till den valda modellplatsen och funktionen använder den init() vanligtvis för att läsa in modellen i minnet. Vissa modeller kan dock innehålla sina filer i en mapp, och du kan behöva ta hänsyn till det när du läser in dem. Du kan identifiera mappstrukturen för din modell enligt följande:
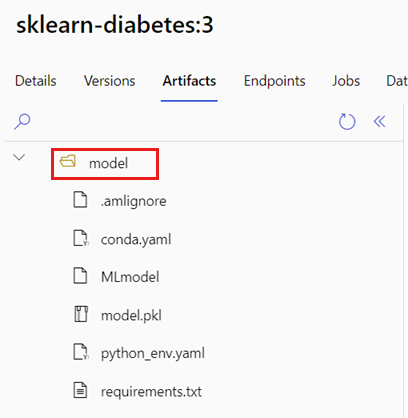
Gå till Azure Machine Learning-portalen.
Gå till avsnittet Modeller.
Välj den modell som du vill distribuera och välj fliken Artefakter .
Observera den mapp som visas. Den här mappen angavs när modellen registrerades.

Använd den här sökvägen för att läsa in modellen:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)