Skapa jobb och indata för batchslutpunkter
När du använder batchslutpunkter i Azure Machine Learning kan du utföra långa batchåtgärder över stora mängder indata. Data kan finnas på olika platser, till exempel i olika regioner. Vissa typer av batchslutpunkter kan också ta emot literalparametrar som indata.
Den här artikeln beskriver hur du anger parameterindata för batchslutpunkter och skapar distributionsjobb. Processen stöder arbete med data från olika källor, till exempel datatillgångar, datalager, lagringskonton och lokala filer.
Förutsättningar
En batchslutpunkt och distribution. Information om hur du skapar dessa resurser finns i Distribuera MLflow-modeller i batchdistributioner i Azure Machine Learning.
Behörigheter för att köra en batchslutpunktsdistribution. Du kan använda rollerna AzureML Dataforskare, Deltagare och Ägare för att köra en distribution. Information om hur du granskar specifika behörigheter som krävs för anpassade rolldefinitioner finns i Auktorisering på batchslutpunkter.
Autentiseringsuppgifter för att anropa en slutpunkt. Mer information finns i Upprätta autentisering.
Läs åtkomst till indata från beräkningsklustret där slutpunkten distribueras.
Dricks
Vissa situationer kräver att du använder ett datalager utan autentiseringsuppgifter eller ett externt Azure Storage-konto som indata. I dessa scenarier ska du se till att du konfigurerar beräkningskluster för dataåtkomst eftersom den hanterade identiteten för beräkningsklustret används för montering av lagringskontot. Du har fortfarande detaljerad åtkomstkontroll eftersom jobbets identitet (anroparen) används för att läsa underliggande data.
Upprätta autentisering
För att anropa en slutpunkt behöver du en giltig Microsoft Entra-token. När du anropar en slutpunkt skapar Azure Machine Learning ett batchdistributionsjobb under den identitet som är associerad med token.
- Om du använder Azure Machine Learning CLI (v2) eller Azure Machine Learning SDK för Python (v2) för att anropa slutpunkter behöver du inte hämta Microsoft Entra-token manuellt. Under inloggningen autentiserar systemet din användaridentitet. Den hämtar och skickar även token åt dig.
- Om du använder REST-API:et för att anropa slutpunkter måste du hämta token manuellt.
Du kan använda dina egna autentiseringsuppgifter för anropet enligt beskrivningen i följande procedurer.
Använd Azure CLI för att logga in med interaktiv kod eller enhetskodautentisering :
az login
Mer information om olika typer av autentiseringsuppgifter finns i Så här kör du jobb med olika typer av autentiseringsuppgifter.
Skapa grundläggande jobb
Om du vill skapa ett jobb från en batchslutpunkt anropar du slutpunkten. Anrop kan göras med hjälp av Azure Machine Learning CLI, Azure Machine Learning SDK för Python eller ett REST API-anrop.
I följande exempel visas grunderna för anrop för en batchslutpunkt som tar emot en enda indatamapp för bearbetning. Exempel som omfattar olika indata och utdata finns i Förstå indata och utdata.
Använd åtgärden invoke under batchslutpunkter:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Anropa en specifik distribution
Batch-slutpunkter kan vara värdar för flera distributioner under samma slutpunkt. Standardslutpunkten används om inte användaren anger något annat. Du kan använda följande procedurer för att ändra den distribution som du använder.
Använd argumentet --deployment-name eller -d för att ange namnet på distributionen:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Konfigurera jobbegenskaper
Du kan konfigurera vissa jobbegenskaper vid anrop.
Kommentar
För närvarande kan du bara konfigurera jobbegenskaper i batchslutpunkter med distributioner av pipelinekomponenter.
Konfigurera experimentnamnet
Använd följande procedurer för att konfigurera experimentnamnet.
Använd argumentet --experiment-name för att ange namnet på experimentet:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Förstå indata och utdata
Batch-slutpunkter tillhandahåller ett beständiga API som konsumenterna kan använda för att skapa batchjobb. Samma gränssnitt kan användas för att ange indata och utdata som distributionen förväntar sig. Använd indata för att skicka all information som slutpunkten behöver för att utföra jobbet.
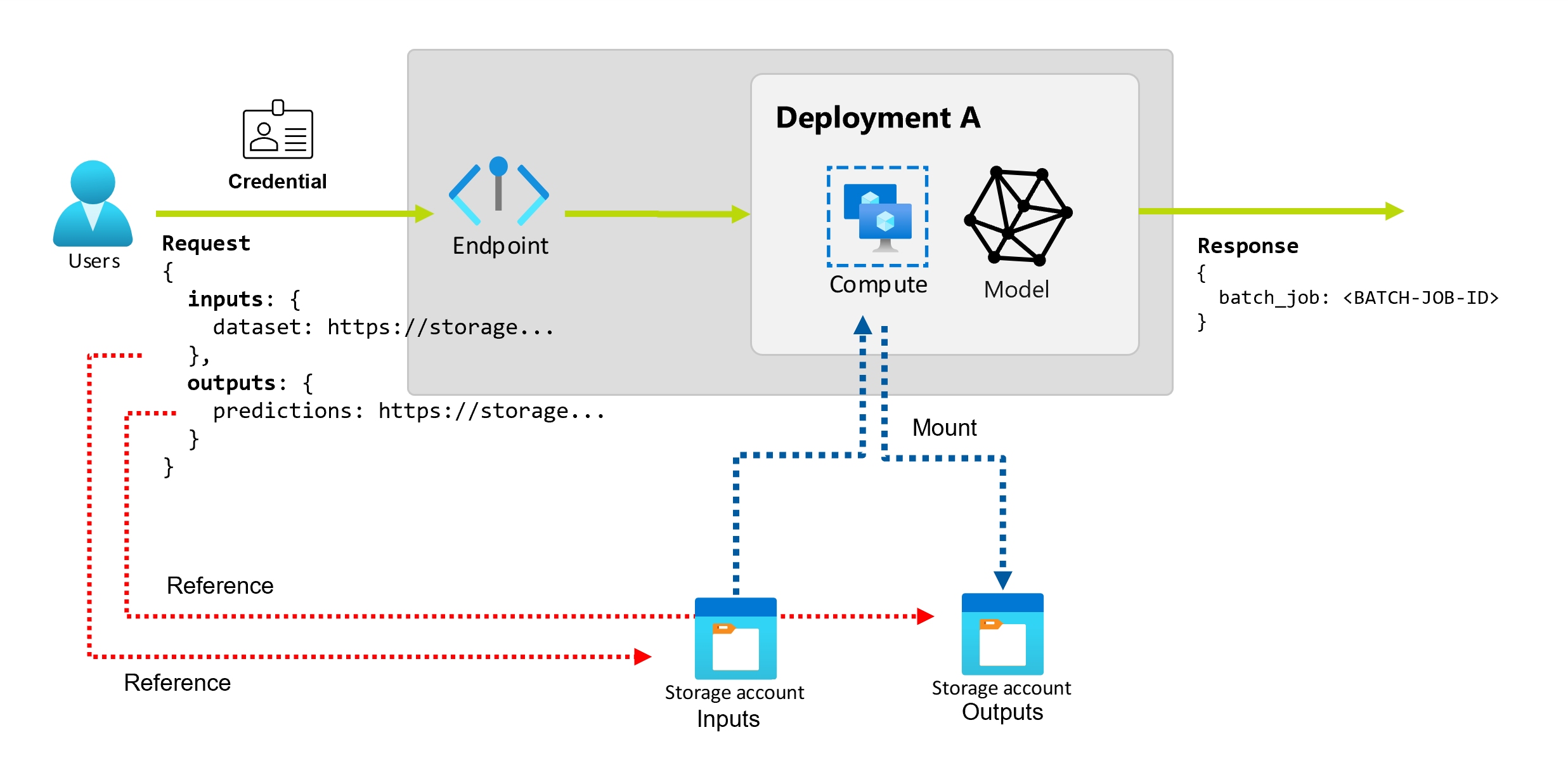
Batch-slutpunkter stöder två typer av indata:
- Dataindata eller pekare till en specifik lagringsplats eller Azure Machine Learning-tillgång
- Literala indata eller literalvärden som tal eller strängar som du vill skicka till jobbet
Antalet och typen av indata och utdata beror på typen av batchdistribution. Modelldistributioner kräver alltid en datainmatning och skapar ett datautdata. Literala indata stöds inte i modelldistributioner. Distributioner av pipelinekomponenter ger däremot en mer allmän konstruktion för att skapa slutpunkter. I en pipelinekomponentdistribution kan du ange valfritt antal dataindata, literala indata och utdata.
I följande tabell sammanfattas indata och utdata för batchdistributioner:
| Distributionstyp | Antal indata | Indatatyper som stöds | Antal utdata | Utdatatyper som stöds |
|---|---|---|---|---|
| Modelldistribution | 1 | Dataindata | 1 | Datautdata |
| Distribution av pipelinekomponenter | 0-N | Indata och literala indata | 0-N | Datautdata |
Dricks
Indata och utdata namnges alltid. Varje namn fungerar som en nyckel för att identifiera data och skicka värdet under anropet. Eftersom modelldistributioner alltid kräver en indata och utdata ignoreras namnen under anrop i modelldistributioner. Du kan tilldela det namn som bäst beskriver ditt användningsfall, till exempel sales_estimation.
Utforska dataindata
Dataindata refererar till indata som pekar på en plats där data placeras. Eftersom batchslutpunkter vanligtvis förbrukar stora mängder data kan du inte skicka indata som en del av begäran om anrop. I stället anger du den plats där batchslutpunkten ska gå för att leta efter data. Indata monteras och strömmas på målberäkningsinstansen för att förbättra prestandan.
Batch-slutpunkter kan läsa filer som finns i följande typer av lagring:
-
Azure Machine Learning-datatillgångar, inklusive typerna mapp (
uri_folder) och fil (uri_file). - Azure Machine Learning-datalager, inklusive Azure Blob Storage, Azure Data Lake Storage Gen1 och Azure Data Lake Storage Gen2.
- Azure Storage-konton, inklusive Blob Storage, Data Lake Storage Gen1 och Data Lake Storage Gen2.
- Lokala datamappar och filer när du använder Azure Machine Learning CLI eller Azure Machine Learning SDK för Python för att anropa slutpunkter. Men lokala data laddas upp till standarddatalagret för din Azure Machine Learning-arbetsyta.
Viktigt!
Utfasningsmeddelande: Datatillgångar av typen FileDataset (V1) är inaktuella och dras tillbaka i framtiden. Befintliga batchslutpunkter som förlitar sig på den här funktionen fortsätter att fungera. Men det finns inget stöd för V1-datauppsättningar i batchslutpunkter som skapas med:
- Versioner av Azure Machine Learning CLI v2 som är allmänt tillgängliga (2.4.0 och senare).
- Versioner av REST API som är allmänt tillgängliga (2022-05-01 och senare).
Utforska literalindata
Literala indata refererar till indata som kan representeras och matchas vid anrop, till exempel strängar, tal och booleska värden. Du använder vanligtvis literala indata för att skicka parametrar till slutpunkten som en del av en pipelinekomponentdistribution. Batch-slutpunkter stöder följande literaltyper:
stringbooleanfloatinteger
Literala indata stöds endast i pipelinekomponentdistributioner. Information om hur du anger literala slutpunkter finns i Skapa jobb med literala indata.
Utforska datautdata
Datautdata refererar till den plats där resultatet av ett batchjobb placeras. Varje utdata har ett identifierbart namn och Azure Machine Learning tilldelar automatiskt en unik sökväg till varje namngiven utdata. Du kan ange en annan sökväg om du behöver.
Viktigt!
Batch-slutpunkter stöder endast skrivning av utdata i Blob Storage-datalager. Om du behöver skriva till ett lagringskonto med hierarkiska namnområden aktiverade, till exempel Data Lake Storage Gen2, kan du registrera lagringstjänsten som ett Blob Storage-datalager eftersom tjänsterna är helt kompatibla. På så sätt kan du skriva utdata från batchslutpunkter till Data Lake Storage Gen2.
Skapa jobb med dataindata
I följande exempel visas hur du skapar jobb när du tar dataindata från datatillgångar, datalager och Azure Storage-konton.
Använda indata från en datatillgång
Azure Machine Learning-datatillgångar (tidigare kallade datauppsättningar) stöds som indata för jobb. Följ de här stegen för att köra ett batchslutpunktsjobb som använder indata som lagras i en registrerad datatillgång i Azure Machine Learning.
Varning
Datatillgångar av typen table (MLTable) stöds för närvarande inte.
Skapa datatillgången. I det här exemplet består den av en mapp som innehåller flera CSV-filer. Du använder batchslutpunkter för att bearbeta filerna parallellt. Du kan hoppa över det här steget om dina data redan är registrerade som en datatillgång.
Skapa en datatillgångsdefinition i en YAML-fil med namnet heart-data.yml:
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataSkapa datatillgången:
az ml data create -f heart-data.yml
Konfigurera indata:
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)Datatillgångs-ID:t har formatet
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>.Kör slutpunkten:
--setAnvänd argumentet för att ange indata. Ersätt först eventuella bindestreck i datatillgångens namn med understreckstecken. Nycklar kan bara innehålla alfanumeriska tecken och understreckstecken.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDFör en slutpunkt som hanterar en modelldistribution kan du använda
--inputargumentet för att ange dataindata, eftersom en modelldistribution alltid bara kräver en datainmatning.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_IDArgumentet
--settenderar att generera långa kommandon när du anger flera indata. I sådana fall kan du lista dina indata i en fil och sedan referera till filen när du anropar slutpunkten. Du kan till exempel skapa en YAML-fil med namnet inputs.yml som innehåller följande rader:inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1Sedan kan du köra följande kommando, som använder
--fileargumentet för att ange indata:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Använda indata från ett datalager
Dina batchdistributionsjobb kan direkt referera till data som finns i Azure Machine Learning-registrerade datalager. I det här exemplet laddar du först upp vissa data till ett datalager på din Azure Machine Learning-arbetsyta. Sedan kör du en batchdistribution på dessa data.
I det här exemplet används standarddatalagret, men du kan använda ett annat datalager. I valfri Azure Machine Learning-arbetsyta är namnet på standard-blobdatalagret workspaceblobstore. Om du vill använda ett annat datalager i följande steg ersätter workspaceblobstore du med namnet på ditt önskade datalager.
Ladda upp exempeldata till datalagret. Exempeldata är tillgängliga på lagringsplatsen azureml-examples . Du hittar data i mappen sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data på lagringsplatsen.
- I Azure Machine Learning-studio öppnar du sidan med datatillgångar för standardlagringen av blobdata och letar sedan upp namnet på dess blobcontainer.
- Använd ett verktyg som Azure Storage Explorer eller AzCopy för att ladda upp exempeldata till en mapp med namnet heart-disease-uci-unlabeled i containern.
Konfigurera indatainformationen:
Placera filsökvägen i variabeln
INPUT_PATH:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"Observera hur
pathsmappen är en del av indatasökvägen. Det här formatet anger att värdet som följer är en sökväg.Kör slutpunkten:
--setAnvänd argumentet för att ange indata:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHFör en slutpunkt som hanterar en modelldistribution kan du använda
--inputargumentet för att ange dataindata, eftersom en modelldistribution alltid bara kräver en datainmatning.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderArgumentet
--settenderar att generera långa kommandon när du anger flera indata. I sådana fall kan du lista dina indata i en fil och sedan referera till filen när du anropar slutpunkten. Du kan till exempel skapa en YAML-fil med namnet inputs.yml som innehåller följande rader:inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>Om dina data finns i en fil använder du
uri_filetypen för indata i stället.Sedan kan du köra följande kommando, som använder
--fileargumentet för att ange indata:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Använda indata från ett Azure Storage-konto
Azure Machine Learning-batchslutpunkter kan läsa data från molnplatser i Azure Storage-konton, både offentliga och privata. Använd följande steg för att köra ett batchslutpunktsjobb med data i ett lagringskonto.
Mer information om extra nödvändiga konfigurationer för att läsa data från lagringskonton finns i Konfigurera beräkningskluster för dataåtkomst.
Konfigurera indata:
Ange variabeln
INPUT_DATA:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Om dina data finns i en fil använder du ett format som liknar följande för att definiera indatasökvägen:
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Kör slutpunkten:
--setAnvänd argumentet för att ange indata:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAFör en slutpunkt som hanterar en modelldistribution kan du använda
--inputargumentet för att ange dataindata, eftersom en modelldistribution alltid bara kräver en datainmatning.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderArgumentet
--settenderar att generera långa kommandon när du anger flera indata. I sådana fall kan du lista dina indata i en fil och sedan referera till filen när du anropar slutpunkten. Du kan till exempel skapa en YAML-fil med namnet inputs.yml som innehåller följande rader:inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataSedan kan du köra följande kommando, som använder
--fileargumentet för att ange indata:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlOm dina data finns i en fil använder du
uri_filetypen i den inputs.yml filen för dataindata.
Skapa jobb med literala indata
Distributioner av pipelinekomponenter kan ta literala indata. Ett exempel på en batchdistribution som innehåller en grundläggande pipeline finns i Distribuera pipelines med batchslutpunkter.
I följande exempel visas hur du anger en indata med namnet score_mode, av typen string, med värdet append:
Placera dina indata i en YAML-fil, till exempel en med namnet inputs.yml:
inputs:
score_mode:
type: string
default: append
Kör följande kommando, som använder --file argumentet för att ange indata.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Du kan också använda --set argumentet för att ange typ och standardvärde. Men den här metoden tenderar att generera långa kommandon när du anger flera indata:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Skapa jobb med datautdata
I följande exempel visas hur du ändrar platsen för utdata med namnet score. För fullständighet konfigurerar exemplet även indata med namnet heart_data.
I det här exemplet används standarddatalagret, workspaceblobstore. Men du kan använda andra datalager på din arbetsyta så länge det är ett Blob Storage-konto. Om du vill använda ett annat datalager ersätter workspaceblobstore du i följande steg med namnet på ditt önskade datalager.
Hämta ID:t för datalagret.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Datalager-ID:t har formatet
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore.Skapa ett datautdata:
Definiera in- och utdatavärdena i en fil med namnet inputs-and-outputs.yml. Använd datalager-ID:t i utdatasökvägen. För fullständighet definierar du även indata.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathKommentar
Observera hur
pathsmappen är en del av utdatasökvägen. Det här formatet anger att värdet som följer är en sökväg.Kör distributionen:
--fileAnvänd argumentet för att ange indata- och utdatavärdena:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml