Köra Python-skriptkomponent
I den här artikeln beskrivs komponenten Kör Python-skript i Azure Machine Learning-designern.
Använd den här komponenten för att köra Python-kod. Mer information om arkitektur- och designprinciperna i Python finns i hur du kör Python-kod i Azure Machine Learning Designer.
Med Python kan du utföra uppgifter som befintliga komponenter inte stöder, till exempel:
- Visualisera data med hjälp
matplotlibav . - Använda Python-bibliotek för att räkna upp datauppsättningar och modeller på din arbetsyta.
- Läsa, läsa in och ändra data från källor som komponenten Importera data inte stöder.
- Kör din egen djupinlärningskod.
Python-paket som stöds
Azure Machine Learning använder Anaconda-distributionen av Python, som innehåller många vanliga verktyg för databearbetning. Vi uppdaterar Anaconda-versionen automatiskt. Den aktuella versionen är:
- Anaconda 4.5+ distribution för Python 3.6
En fullständig lista finns i avsnittet Förinstallerade Python-paket.
Om du vill installera paket som inte finns i den förinstallerade listan (till exempel scikit-misc) lägger du till följande kod i skriptet:
import os
os.system(f"pip install scikit-misc")
Använd följande kod för att installera paket för bättre prestanda, särskilt för slutsatsdragning:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Kommentar
Om din pipeline innehåller flera Execute Python Script-komponenter som behöver paket som inte finns i den förinstallerade listan installerar du paketen i varje komponent.
Varning
Excute Python Script-komponenten stöder inte installation av paket som är beroende av extra interna bibliotek med kommandon som "apt-get", till exempel Java, PyODBC och så vidare. Det beror på att den här komponenten körs i en enkel miljö med Python förinstallerat och med icke-administratörsbehörighet.
Åtkomst till aktuell arbetsyta och registrerade datauppsättningar
Du kan läsa följande exempelkod för åtkomst till de registrerade datauppsättningarna på din arbetsyta:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Ladda upp filer
Komponenten Kör Python-skript stöder uppladdning av filer med hjälp av Azure Machine Learning Python SDK.
I följande exempel visas hur du laddar upp en bildfil i komponenten Kör Python-skript:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
När pipelinekörningen är klar kan du förhandsgranska bilden i komponentens högra panel.
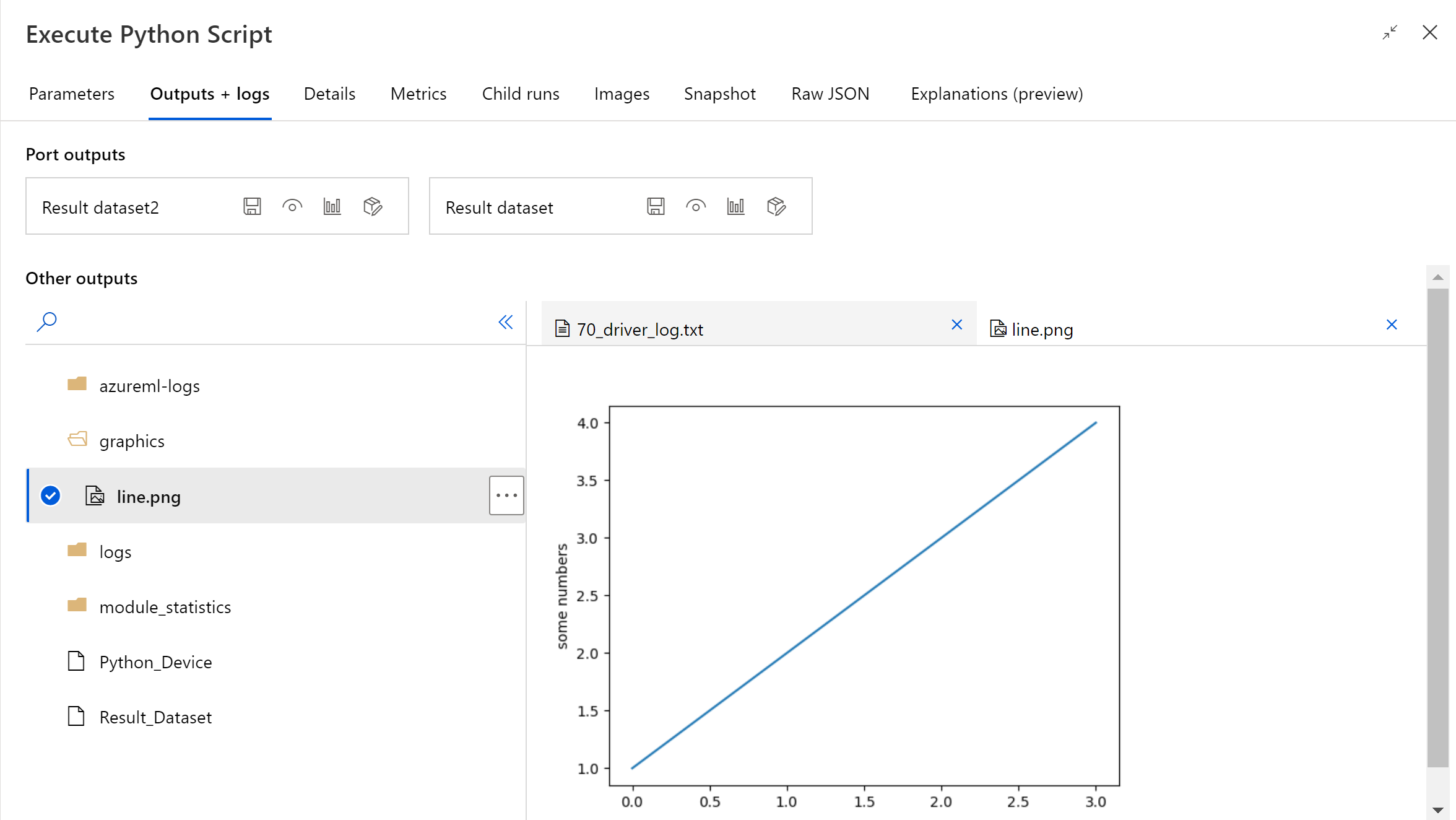
Du kan också ladda upp filen till alla datalager med hjälp av följande kod. Du kan bara förhandsgranska filen i ditt lagringskonto.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Så här konfigurerar du Kör Python-skript
Komponenten Kör Python-skript innehåller python-exempelkod som du kan använda som utgångspunkt. Om du vill konfigurera komponenten Kör Python-skript anger du en uppsättning indata och Python-kod som ska köras i textrutan Python-skript .
Lägg till komponenten Execute Python Script (Kör Python-skript) i pipelinen.
Lägg till och anslut på Dataset1 alla datauppsättningar från designern som du vill använda för indata. Referera till den här datauppsättningen i Python-skriptet som DataFrame1.
Det är valfritt att använda en datauppsättning. Använd den om du vill generera data med hjälp av Python eller använda Python-kod för att importera data direkt till komponenten.
Den här komponenten stöder tillägg av en andra datauppsättning på Dataset2. Referera till den andra datauppsättningen i Python-skriptet som DataFrame2.
Datauppsättningar som lagras i Azure Machine Learning konverteras automatiskt till Pandas-dataramar när de läses in med den här komponenten.
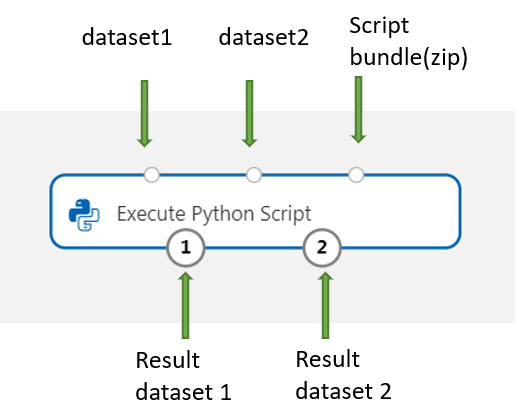
Om du vill inkludera nya Python-paket eller kod ansluter du den zippade filen som innehåller dessa anpassade resurser till skriptpaketporten . Eller om skriptet är större än 16 kB använder du skriptpaketporten för att undvika fel som att CommandLine överskrider gränsen på 16597 tecken.
- Paketering av skriptet och andra anpassade resurser till en zip-fil.
- Ladda upp zip-filen som en fildatauppsättning till studion.
- Dra datamängdskomponenten från listan Datauppsättningar i det vänstra komponentfönstret på sidan designerredigering.
- Anslut datamängdskomponenten till skriptpaketporten för Komponenten Kör Python-skript.
Alla filer som finns i det uppladdade zippade arkivet kan användas under pipelinekörningen. Om arkivet innehåller en katalogstruktur bevaras strukturen.
Viktigt!
Använd ett unikt och meningsfullt namn för filer i skriptpaketet eftersom vissa vanliga ord (t.ex
test. ochappetc) är reserverade för inbyggda tjänster.Följande är ett exempel på ett skriptpaket som innehåller en Python-skriptfil och en txt-fil:

Följande är innehållet
my_script.pyi :def my_func(dataframe1): return dataframe1Följande är exempelkod som visar hur du använder filerna i skriptpaketet:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])I textrutan Python-skript skriver eller klistrar du in ett giltigt Python-skript.
Kommentar
Var försiktig när du skriver skriptet. Kontrollera att det inte finns några syntaxfel, till exempel att använda odeklarerade variabler eller oimporterade komponenter eller funktioner. Var extra uppmärksam på den förinstallerade komponentlistan. Om du vill importera komponenter som inte visas installerar du motsvarande paket i skriptet, till exempel:
import os os.system(f"pip install scikit-misc")Textrutan Python-skript är förifyllda med några instruktioner i kommentarer och exempelkod för dataåtkomst och utdata. Du måste redigera eller ersätta den här koden. Följ Python-konventioner för indrag och hölje:
- Skriptet måste innehålla en funktion med namnet
azureml_mainsom startpunkt för den här komponenten. - Startpunktsfunktionen måste ha två indataargument
Param<dataframe1>ochParam<dataframe2>, även om dessa argument inte används i skriptet. - Zippade filer som är anslutna till den tredje indataporten packas upp och lagras i katalogen
.\Script Bundle, som också läggs till i Pythonsys.path.
Om filen .zip innehåller importerar
mymodule.pydu den med hjälpimport mymoduleav .Två datauppsättningar kan returneras till designern, som måste vara en sekvens av typen
pandas.DataFrame. Du kan skapa andra utdata i Python-koden och skriva dem direkt till Azure Storage.Varning
Vi rekommenderar inte att du ansluter till en databas eller andra externa lagringsenheter i Komponenten Kör Python-skript. Du kan använda komponenten Importera data och Exportera data
- Skriptet måste innehålla en funktion med namnet
Skicka pipelinen.
Om komponenten har slutförts kontrollerar du utdata om det är förväntat.
Om komponenten misslyckas måste du utföra felsökning. Välj komponenten och öppna Utdata+loggar i den högra rutan. Öppna 70_driver_log.txt och sök i azureml_main, så kan du hitta vilken rad som orsakade felet. Till exempel anger "File "/tmp/tmp01_ID/user_script.py", rad 17, i azureml_main" att felet inträffade på 17-raden i Python-skriptet.
Resultat
Resultatet av alla beräkningar av den inbäddade Python-koden måste anges som pandas.DataFrame, som automatiskt konverteras till Azure Machine Learning-datamängdsformatet. Du kan sedan använda resultatet med andra komponenter i pipelinen.
Komponenten returnerar två datauppsättningar:
Resultatdatauppsättning 1, definierad av den första returnerade Pandas-dataramen i ett Python-skript.
Resultatdatauppsättning 2, definierad av den andra returnerade Pandas-dataramen i ett Python-skript.
Förinstallerade Python-paket
De förinstallerade paketen är:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- cryptography==2.8
- cycler==0.10.0
- dill==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- imbalanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.