Konfigurera asynkrona inställningar för hög tillgänglighet, skalning och minnesanvändning
Broker-resursen är den viktigaste resursen som definierar de övergripande inställningarna för en MQTT-koordinator. Den avgör också antalet och typen av poddar som kör Broker-konfigurationen, till exempel klientdelarna och serverdelarna. Du kan också använda Broker-resursen för att konfigurera dess minnesprofil. Självåterställningsmekanismer är inbyggda i asynkron meddelandekö och kan ofta återställas automatiskt från komponentfel. Ett exempel är om en nod misslyckas i ett Kubernetes-kluster som har konfigurerats för hög tillgänglighet.
Du kan skala MQTT-koordinatorn vågrätt genom att lägga till fler klientdelsrepliker och serverdelspartitioner. Klientdelsreplikerna ansvarar för att acceptera MQTT-anslutningar från klienter och vidarebefordra dem till serverdelspartitionerna. Serverdelspartitionerna ansvarar för att lagra och leverera meddelanden till klienterna. Klientdelspoddarna distribuerar meddelandetrafik över serverdelspoddarna. Backend-redundansfaktorn avgör antalet datakopior för att ge återhämtning mot nodfel i klustret.
En lista över tillgängliga inställningar finns i referensen för Broker API.
Konfigurera skalningsinställningar
Viktigt!
Den här inställningen kräver att du ändrar Broker-resursen. Den konfigureras endast vid den första distributionen med hjälp av Azure CLI eller Azure Portal. En ny distribution krävs om konfigurationsändringar i Broker behövs. Mer information finns i Anpassa standard broker.
Om du vill konfigurera skalningsinställningarna för MQTT-koordinatorn anger du kardinalitetsfälten i specifikationen för Broker-resursen under Azure IoT Operations-distributionen.
Kardinalitet för automatisk distribution
Om du vill fastställa den inledande kardinaliteten automatiskt under distributionen utelämnar du kardinalitetsfältet i Broker-resursen.
Automatisk kardinalitet stöds inte ännu när du distribuerar IoT-åtgärder via Azure Portal. Du kan ange klusterdistributionsläget manuellt som enskild nod eller flera noder. Mer information finns i Distribuera Azure IoT-åtgärder.
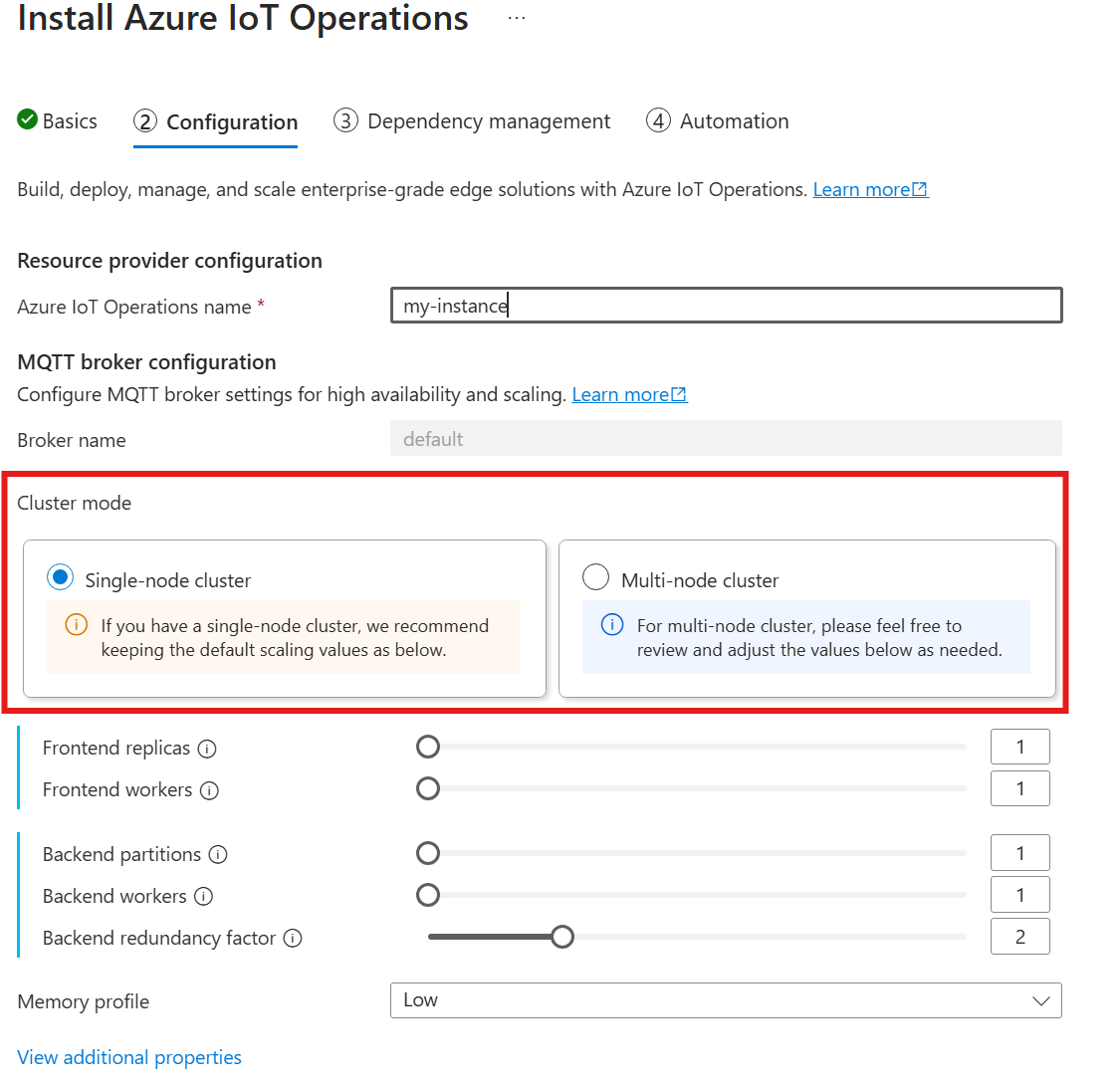
MQTT-koordinatoroperatorn distribuerar automatiskt lämpligt antal poddar baserat på antalet tillgängliga noder vid tidpunkten för distributionen. Den här funktionen är användbar för icke-produktionsscenarier där du inte behöver hög tillgänglighet eller skalning.
Den här funktionen är inte autoskalning. Operatorn skalar inte automatiskt antalet poddar baserat på belastningen. Operatorn avgör det ursprungliga antalet poddar som endast ska distribueras baserat på klustermaskinvaran. Som tidigare nämnts anges kardinaliteten endast vid den första distributionstiden. En ny distribution krävs om kardinalitetsinställningarna behöver ändras.
Konfigurera kardinalitet direkt
Om du vill konfigurera kardinalitetsinställningarna direkt anger du vart och ett av kardinalitetsfälten.
När du följer guiden för att distribuera IoT-åtgärder går du till avsnittet Konfiguration och tittar under MQTT-koordinatorkonfiguration. Här kan du ange antalet klientdelsrepliker, serverdelspartitioner och serverdelsarbetare.
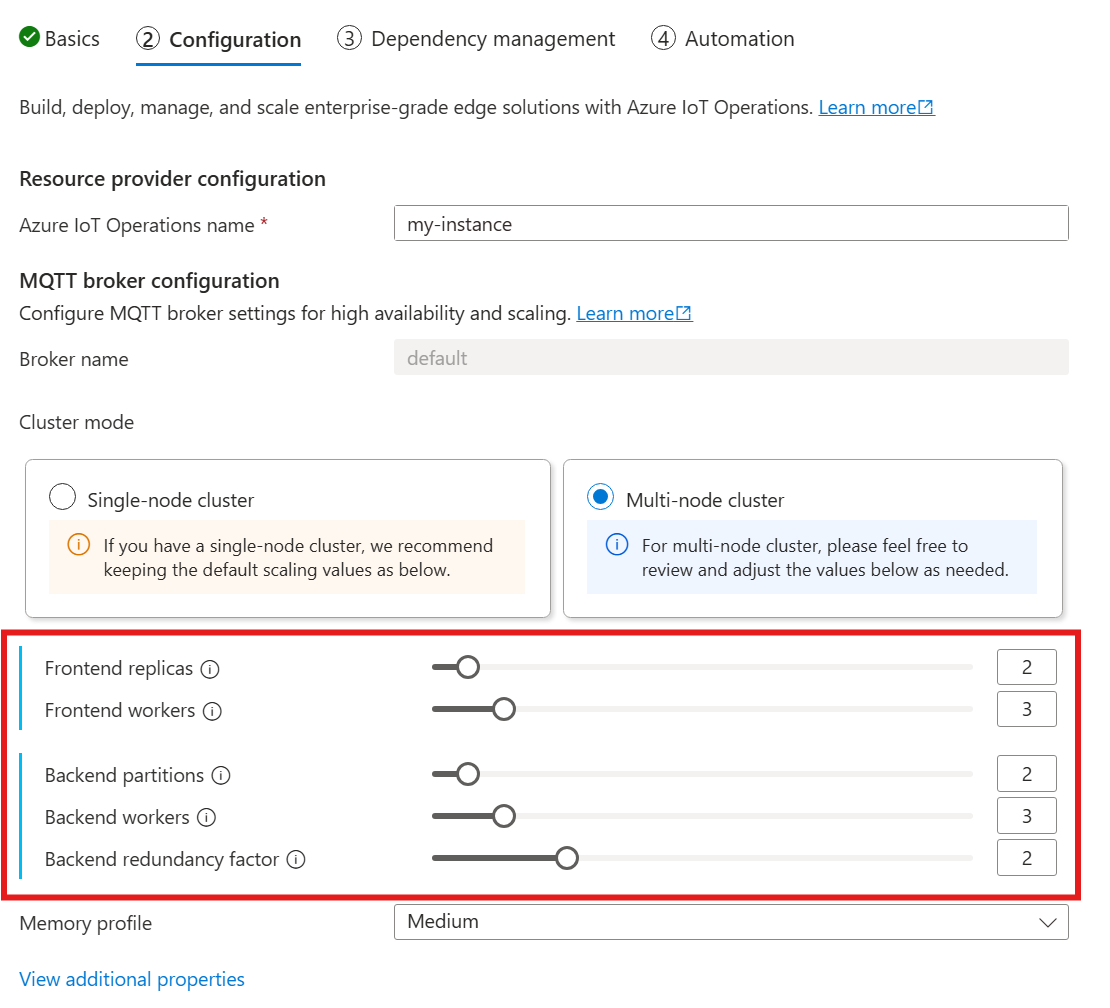
Förstå kardinalitet
Kardinalitet innebär antalet instanser av en viss entitet i en uppsättning. I samband med MQTT-koordinatorn refererar kardinaliteten till antalet klientdelsrepliker, serverdelspartitioner och serverdelsarbetare som ska distribueras. Kardinalitetsinställningarna används för att skala koordinatorn vågrätt och förbättra hög tillgänglighet om det uppstår podd- eller nodfel.
Kardinalitetsfältet är ett kapslat fält med underfält för klientdelen och serverdelskedjan. Vart och ett av dessa underfält har sina egna inställningar.
Klientdel
Klientdelsunderfältet definierar inställningarna för klientdelspoddarna. De två huvudinställningarna är:
- Repliker: Antalet klientdelsrepliker (poddar) som ska distribueras. Om du ökar antalet klientdelsrepliker får du hög tillgänglighet om någon av klientdelspoddarna misslyckas.
- Arbetare: Antalet logiska klientdelsarbetare per replik. Varje arbetare kan använda upp till en processorkärna som mest.
Serverdelskedja
Serverdelskedjans underfält definierar inställningarna för serverdelspartitionerna. De tre huvudinställningarna är:
- Partitioner: Antalet partitioner som ska distribueras. Genom en process som kallas horisontell partitionering ansvarar varje partition för en del av meddelandena, dividerat med ämnes-ID och sessions-ID. Klientdelspoddarna distribuerar meddelandetrafik över partitionerna. Om du ökar antalet partitioner ökar antalet meddelanden som asynkron meddelandekö kan hantera.
- Redundansfaktor: Antalet serverdelsrepliker (poddar) som ska distribueras per partition. Om du ökar redundansfaktorn ökar antalet datakopior för att ge återhämtning mot nodfel i klustret.
- Arbetare: Antalet arbetare som ska distribueras per serverdelsreplik. Om du ökar antalet arbetare per serverdelsreplik kan du öka antalet meddelanden som serverdelspodden kan hantera. Varje arbetare kan förbruka högst två CPU-kärnor, så var försiktig när du ökar antalet arbetare per replik till att inte överskrida antalet CPU-kärnor i klustret.
Att tänka på
När du ökar kardinalitetsvärdena förbättras brokerns kapacitet att hantera fler anslutningar och meddelanden i allmänhet, och det förbättrar hög tillgänglighet om det finns podd- eller nodfel. Den ökade kapaciteten leder också till högre resursförbrukning. När du justerar kardinalitetsvärdena bör du därför tänka på minnesprofilinställningarna och koordinatorns CPU-resursbegäranden. Om du ökar antalet arbetare per klientdelsreplik kan du öka processorkärnans användning om du upptäcker att processoranvändningen i klientdelen är en flaskhals. Att öka antalet serverdelsarbetare kan hjälpa till med dataflödet för meddelanden om processoranvändningen i serverdelen är en flaskhals.
Om klustret till exempel har tre noder, var och en med åtta CPU-kärnor, anger du sedan antalet klientdelsrepliker så att det matchar antalet noder (3) och anger antalet arbetare till 1. Ange antalet serverdelspartitioner så att de matchar antalet noder (3) och ange serverdelsarbetarna till 1. Ange redundansfaktorn som önskat (2 eller 3). Öka antalet klientdelsarbetare om du upptäcker att processoranvändningen i klientdelen är en flaskhals. Kom ihåg att serverdels- och klientdelsarbetare kan konkurrera om CPU-resurser med varandra och andra poddar.
Konfigurera minnesprofil
Viktigt!
Den här inställningen kräver att du ändrar Broker-resursen. Den konfigureras endast vid den första distributionen med hjälp av Azure CLI eller Azure Portal. En ny distribution krävs om konfigurationsändringar i Broker behövs. Mer information finns i Anpassa standard broker.
Om du vill konfigurera minnesprofilinställningarna för MQTT-koordinatorn anger du fälten för minnesprofilen i specifikationen för Broker-resursen under IoT Operations-distributionen.
När du använder följande guide för att distribuera IoT-åtgärder går du till avsnittet Konfiguration och tittar under MQTT-koordinatorkonfiguration och letar reda på inställningen Minnesprofil. Här kan du välja från de tillgängliga minnesprofilerna i en listruta.
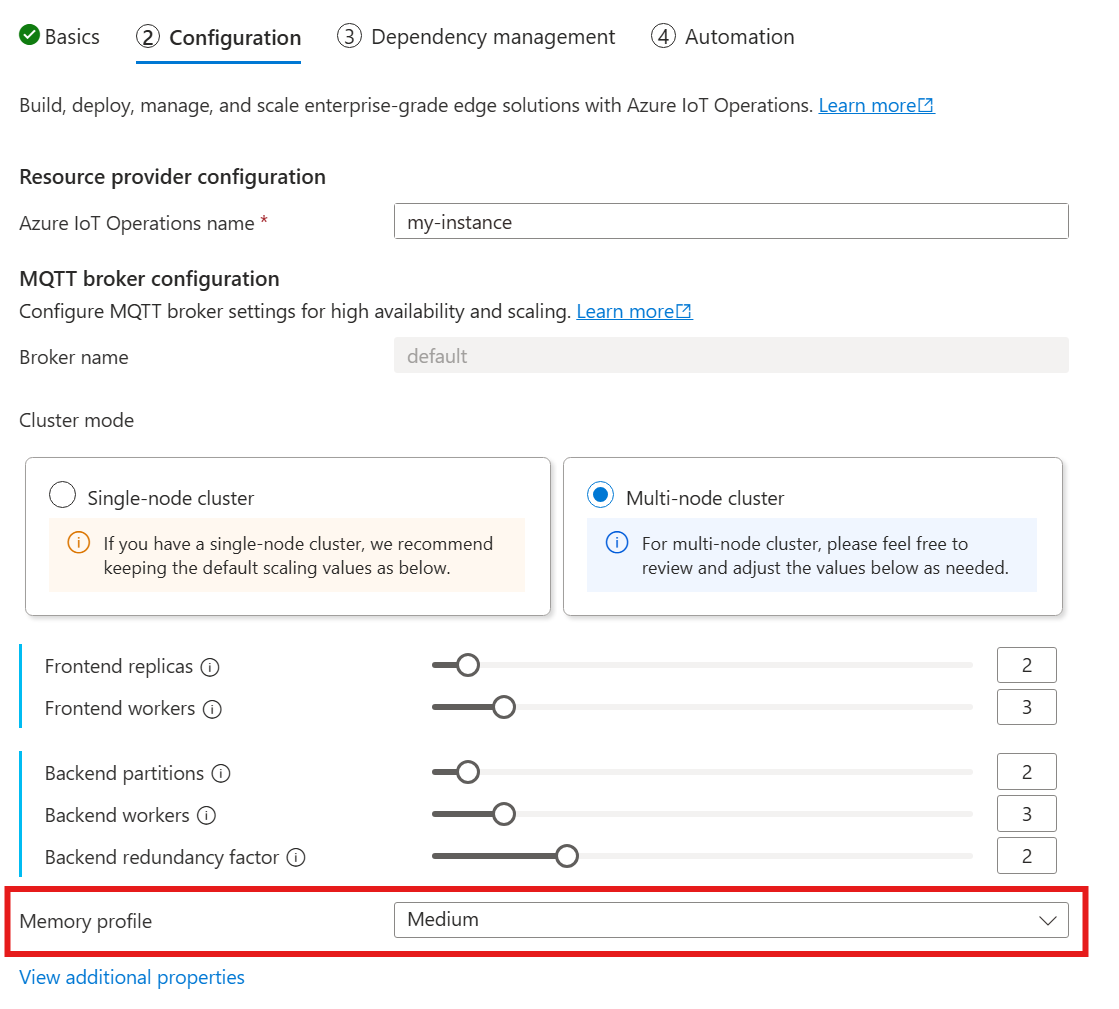
Det finns några minnesprofiler att välja mellan, var och en med olika minnesanvändningsegenskaper.
Pytteliten
När du använder den här profilen:
- Maximal minnesanvändning för varje klientdelsreplik är cirka 99 MiB, men den faktiska maximala minnesanvändningen kan vara högre.
- Maximal minnesanvändning för varje serverdelsreplik är cirka 102 MiB multiplicerat med antalet serverdelsarbetare, men den faktiska maximala minnesanvändningen kan vara högre.
Rekommendationer när du använder den här profilen:
- Endast en klientdel ska användas.
- Klienter bör inte skicka stora paket. Du bör bara skicka paket som är mindre än 4 MiB.
Låg
När du använder den här profilen:
- Maximal minnesanvändning för varje klientdelsreplik är cirka 387 MiB, men den faktiska maximala minnesanvändningen kan vara högre.
- Maximal minnesanvändning för varje serverdelsreplik är cirka 390 MiB multiplicerat med antalet serverdelsarbetare, men den faktiska maximala minnesanvändningen kan vara högre.
Rekommendationer när du använder den här profilen:
- Endast en eller två klientdelar ska användas.
- Klienter bör inte skicka stora paket. Du bör bara skicka paket som är mindre än 10 MiB.
Medium
Medium är standardprofilen.
- Maximal minnesanvändning för varje klientdelsreplik är cirka 1,9 GiB, men den faktiska maximala minnesanvändningen kan vara högre.
- Maximal minnesanvändning för varje serverdelsreplik är cirka 1,5 GiB multiplicerat med antalet serverdelsarbetare, men den faktiska maximala minnesanvändningen kan vara högre.
Högt
- Maximal minnesanvändning för varje klientdelsreplik är cirka 4,9 GiB, men den faktiska maximala minnesanvändningen kan vara högre.
- Maximal minnesanvändning för varje serverdelsreplik är cirka 5,8 GiB multiplicerat med antalet serverdelsarbetare, men den faktiska maximala minnesanvändningen kan vara högre.
Resursgränser för kardinalitet och Kubernetes
För att förhindra resurssvält i klustret konfigureras koordinatorn som standard för att begära Kubernetes CPU-resursgränser. Genom att skala antalet repliker eller arbetare proportionellt ökar processorresurserna som krävs. Ett distributionsfel genereras om det inte finns tillräckligt med processorresurser i klustret. Det här meddelandet hjälper dig att undvika situationer där den begärda kardinaliteten för asynkron meddelandekö saknar tillräckligt med resurser för att köras optimalt. Det hjälper också till att undvika potentiella CPU-konkurrens och poddavhysningar.
MQTT-koordinatorn begär för närvarande en (1,0) CPU-enhet per klientdelsarbetare och två (2,0) CPU-enheter per backend worker. Mer information finns i Kubernetes CPU-resursenheter.
Följande kardinalitet skulle till exempel begära följande CPU-resurser:
- För klientdelar: 2 CPU-enheter per klientdelspodd, totalt 6 CPU-enheter.
- För serverdelar: 4 CPU-enheter per serverdelspodd (för två serverdelsarbetare), gånger 2 (redundansfaktor), gånger 3 (antal partitioner), totalt 24 CPU-enheter.
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
Om du vill inaktivera den här inställningen anger du fältet generateResourceLimits.cpu till Disabled i broker-resursen.
Det går inte att generateResourceLimits ändra fältet i Azure Portal. Om du vill inaktivera den här inställningen använder du Azure CLI.
Distribution med flera noder
För att säkerställa hög tillgänglighet och motståndskraft med distributioner med flera noder anger IoT Operations MQTT-asynkrona asynkrona regler för tillhörighetsbegränsning för serverdelspoddar.
Dessa regler är fördefinierade och kan inte ändras.
Syftet med regler mot tillhörighet
Reglerna mot tillhörighet ser till att serverdelspoddar från samma partition inte körs på samma nod. Den här funktionen hjälper till att distribuera belastningen och ger motståndskraft mot nodfel. Mer specifikt har serverdelspoddar från samma partition antitillhörighet med varandra.
Verifiera inställningar för tillhörighetsskydd
Använd följande kommando för att verifiera inställningarna för antitillhörighet för en serverdelspodd:
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
Utdata visar konfigurationen mot tillhörighet, ungefär som i följande exempel:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
Dessa regler är de enda regler för tillhörighetsskydd som angetts för koordinatorn.