Hög tillgänglighet och haveriberedskap för IoT Hub
Som ett första steg mot att implementera en elastisk IoT-lösning måste arkitekter, utvecklare och företagare definiera drifttidsmålen för de lösningar som de skapar. Dessa mål kan definieras främst baserat på specifika affärsmål för varje scenario. I det här sammanhanget beskriver artikeln teknisk vägledning för Azure Business Continuity ett allmänt ramverk som hjälper dig att tänka på affärskontinuitet och haveriberedskap. Dokumentet Haveriberedskap och hög tillgänglighet för Azure-program innehåller arkitekturvägledning för strategier för Azure-program för att uppnå hög tillgänglighet (HA) och haveriberedskap (DR).
I den här artikeln beskrivs ha- och DR-funktionerna som erbjuds specifikt av IoT Hub-tjänsten. De breda områden som beskrivs i den här artikeln är:
- Ha inom regionen
- Dr för flera regioner
- Uppnå ha för flera regioner
Beroende på vilka drifttidsmål du definierar för dina IoT-lösningar bör du bestämma vilka av alternativen som beskrivs i den här artikeln bäst passar dina affärsmål. För att införliva något av dessa alternativ för hög tillgänglighet och tillgänglighet i din IoT-lösning krävs en noggrann utvärdering av kompromisserna mellan:
- Återhämtningsnivå som du behöver
- Implementerings- och underhållskomplexitet
- KSG-påverkan
Ha inom regionen
IoT Hub-tjänsten tillhandahåller ha inom regionen genom att implementera redundanser i nästan alla lager i tjänsten. Serviceavtalet som publiceras av IoT Hub-tjänsten uppnås genom att dessa redundanser används. Det krävs inget extra arbete av utvecklarna av en IoT-lösning för att dra nytta av dessa HA-funktioner. Även om IoT Hub erbjuder en ganska hög drifttidsgaranti kan tillfälliga fel fortfarande förväntas som med alla distribuerade databehandlingsplattformar. Om du precis har börjat migrera dina lösningar till molnet från en lokal lösning måste fokus skifta från att optimera "genomsnittlig tid mellan fel" till "genomsnittlig tid för återställning". Med andra ord ska tillfälliga fel betraktas som normala när de används med molnet i mixen. Lämpliga återförsöksmönster måste vara inbyggda i de komponenter som interagerar med ett molnprogram för att hantera tillfälliga fel.
Tillgänglighetszoner
IoT Hub stöder Azure-tillgänglighetszoner. En tillgänglighetszon är ett erbjudande med hög tillgänglighet som skyddar dina program och data från datacenterfel. En region med stöd för tillgänglighetszoner består av tre zoner som stöder den regionen. Varje zon innehåller ett eller flera datacenter, var och en på en unik fysisk plats med oberoende ström, kylning och nätverk. Den här konfigurationen ger replikering och redundans i regionen.
Tillgänglighetszoner ger två fördelar: dataåterhämtning och smidigare distributioner.
Dataåterhämtning kommer från att ersätta de underliggande lagringstjänsterna med lagring som stöds av tillgänglighetszoner. Dataresiliens är viktigt för IoT-lösningar eftersom dessa lösningar ofta fungerar i komplexa, dynamiska och osäkra miljöer där fel eller störningar kan få betydande konsekvenser. Oavsett om en IoT-lösning stöder tillverkningsgolv, detaljhandels- eller restaurangmiljöer, sjukvårdssystem eller infrastruktur, är tillgängligheten och kvaliteten på data nödvändig för att återställas från fel och för att tillhandahålla tillförlitliga och konsekventa tjänster.
Smidigare distributioner kommer från att ersätta den underliggande datacentermaskinvaran med nyare maskinvara som stöder tillgänglighetszoner . Dessa maskinvaruförbättringar minimerar kundernas påverkan från enhetens frånkopplingar och återanslutningar samt annan distributionsrelaterad stilleståndstid. IoT Hub-teknikteamet distribuerar flera uppdateringar till varje IoT-hubb någonsin i månaden, av både säkerhetsskäl och för att tillhandahålla funktionsförbättringar. Maskinvara som stöds av tillgänglighetszoner är uppdelad i 15 uppdateringsdomäner så att varje uppdatering blir smidigare, med minimal påverkan på dina arbetsflöden. Mer information om uppdateringsdomäner finns i Tillgänglighetsuppsättningar.
Stöd för tillgänglighetszoner för IoT Hub aktiveras automatiskt för nya IoT Hub-resurser som skapats i följande Azure-regioner:
| Region | Dataåterhämtning | Smidigare distributioner |
|---|---|---|
| Australien, östra | ||
| Brasilien, södra | ||
| Kanada, centrala | ||
| Indien, centrala | ||
| Central US | ||
| East US | ||
| Frankrike, centrala | ||
| Tyskland, västra centrala | ||
| Japan, östra | ||
| Sydkorea, centrala | ||
| Europa, norra | ||
| Norge, östra | ||
| Qatar, centrala | ||
| USA, södra centrala | ||
| Sydostasien | ||
| Storbritannien, södra | ||
| Europa, västra | ||
| USA, västra 2 | ||
| USA, västra 3 |
Dr för flera regioner
Det kan finnas vissa sällsynta situationer när ett datacenter drabbas av utökade avbrott på grund av strömavbrott eller andra fel som rör fysiska tillgångar. Sådana händelser är sällsynta under vilka funktionen för intraregion ha som beskrivits tidigare kanske inte alltid hjälper. IoT Hub tillhandahåller flera lösningar för återställning efter sådana utökade avbrott.
Återställningsalternativen som är tillgängliga för kunder i en sådan situation är Microsoft-initierad redundans och manuell redundans. Den grundläggande skillnaden mellan de två är att Microsoft initierar det förra och att användaren initierar det senare. Manuell redundans ger också ett lägre mål för återställningstid (RTO) jämfört med det Microsoft-initierade redundansalternativet. De specifika RTO:er som erbjuds med varje alternativ beskrivs i följande avsnitt. När något av dessa alternativ för att utföra redundansväxling av en IoT-hubb från den primära regionen används blir hubben fullt fungerande i motsvarande geo-kopplade Azure-region.
Båda dessa redundansalternativ erbjuder följande mål för återställningspunkter :)
| Datatyp | Mål för återställningspunkt (RPO) |
|---|---|
| Identitetsregister | Dataförlust på 0–5 minuter |
| Enhetstvillingdata | Dataförlust på 0–5 minuter |
| Meddelandenfrån moln till enhet 1 | Dataförlust på 0–5 minuter |
| Överordnad1 - och enhetsjobb | Dataförlust på 0–5 minuter |
| Meddelanden från enheten till molnet | Alla olästa meddelanden går förlorade |
| Feedbackmeddelanden från moln till enhet | Alla olästa meddelanden går förlorade |
1Meddelanden från moln till enhet och överordnade jobb återställs inte som en del av manuell redundans.
När redundansåtgärden för IoT-hubben har slutförts förväntas alla åtgärder från enheten och serverdelsprogrammen fortsätta att fungera utan manuella åtgärder. Det innebär att dina meddelanden från enhet till moln ska fortsätta att fungera och att hela enhetsregistret är intakt. Händelser som genereras via Event Grid kan användas via samma prenumerationer som konfigurerades tidigare så länge event grid-prenumerationerna fortsätter att vara tillgängliga. Ingen ytterligare hantering krävs för anpassade slutpunkter.
Varning
- Event Hubs-kompatibelt namn och slutpunkt för den inbyggda IoT Hub-händelseslutpunkten ändras efter redundansväxling. När du tar emot telemetrimeddelanden från den inbyggda slutpunkten med antingen Event Hubs-klienten eller händelseprocessorvärden bör du använda IoT Hub-anslutningssträng för att upprätta anslutningen. Detta säkerställer att dina serverdelsprogram fortsätter att fungera utan manuella åtgärder efter redundansväxling. Om du använder det Event Hub-kompatibla namnet och slutpunkten i ditt program direkt måste du hämta den nya Event Hub-kompatibla slutpunkten efter redundansväxlingen för att fortsätta åtgärderna. Mer information finns i Manuell redundans och Händelsehubb.
- Om du använder Azure Functions eller Azure Stream Analytics för att ansluta den inbyggda händelseslutpunkten kan du behöva utföra en omstart. Detta beror på att tidigare förskjutningar under redundansväxlingen inte längre är giltiga.
- När du dirigerar till lagring rekommenderar vi att du listar blobar eller filer och sedan itererar över dem, för att säkerställa att alla blobbar eller filer läss utan att göra några antaganden om partition. Partitionsintervallet kan eventuellt ändras under en Microsoft-initierad redundansväxling eller manuell redundansväxling. Du kan använda LIST Blobs-API:et för att räkna upp listan över blobar eller ADLS Gen2-API för lista över filer. Mer information finns i Azure Storage som en routningsslutpunkt.
Microsoft-initierad redundans
Microsoft-initierad redundans används av Microsoft i sällsynta fall för att redundansväxla alla IoT-hubbar från en berörd region till motsvarande geo-kopplade region. Den här processen är ett standardalternativ och kräver inga åtgärder från användaren. Microsoft förbehåller sig rätten att avgöra när det här alternativet ska användas. Den här mekanismen omfattar inte ett användarmedgivande innan användarens hubb redväxras. Microsoft-initierad redundans har ett mål för återställningstid (RTO) på 2–26 timmar.
Den stora RTO:en beror på att Microsoft måste utföra redundansåtgärden för alla berörda kunder i den regionen. Om du kör en mindre kritisk IoT-lösning som kan upprätthålla en stilleståndstid på ungefär en dag är det ok att du är beroende av det här alternativet för att uppfylla de övergripande målen för haveriberedskap för din IoT-lösning. Den totala tiden för körningsåtgärder att bli helt i drift när den här processen har utlösts beskrivs i avsnittet "Tid att återställa".
Endast användare som distribuerar IoT-hubbar till regionerna Brasilien, södra och Sydostasien (Singapore) kan välja bort den här funktionen. Mer information finns i Inaktivera haveriberedskap.
Kommentar
Azure IoT Hub lagrar eller bearbetar inte kunddata utanför den geografiska plats där du distribuerar tjänstinstansen. Mer information finns i Replikering mellan regioner i Azure.
Manuell redundans
Om dina affärsupptidsmål inte uppfylls av den RTO som Microsoft initierade redundans tillhandahåller kan du överväga att använda manuell redundans för att utlösa redundansväxlingen själv. RtO med det här alternativet kan vara någonstans mellan 10 minuter och ett par timmar. RTO är för närvarande en funktion av det antal enheter som registrerats mot att IoT Hub-instansen redväxeras. Du kan förvänta dig att RTO för en hubb som är värd för cirka 100 000 enheter är i bollplanen på 15 minuter. Den totala tiden för körningsåtgärder att bli helt i drift när den här processen har utlösts beskrivs i avsnittet "Tid att återställa".
Det manuella redundansalternativet är alltid tillgängligt för användning oavsett om den primära regionen har driftstopp eller inte. Därför kan det här alternativet eventuellt användas för att utföra planerade redundansväxlingar. Ett exempel på användning av planerade redundansväxlingar är att utföra regelbundna redundanstest. Ett varningens ord är dock att en planerad redundansåtgärd resulterar i en stilleståndstid för hubben för den period som definieras av RTO för det här alternativet, och även resulterar i en dataförlust enligt definitionen i RPO-tabellen ovan. Du kan överväga att konfigurera en test-IoT Hub-instans för att använda det planerade redundansalternativet regelbundet för att få förtroende för din förmåga att få igång dina lösningar från slutpunkt till slutpunkt när en verklig katastrof inträffar.
Manuell redundans är tillgänglig utan extra kostnad för IoT-hubbar som skapats efter den 18 maj 2017
Stegvisa instruktioner finns i Självstudie: Utföra manuell redundans för en IoT-hubb
Manuell redundans och Event Hubs
Event Hubs-kompatibelt namn och slutpunkt för den inbyggda IoT Hub-händelseslutpunkten ändras efter manuell redundansväxling. Det beror på att Event Hubs-klienten inte har insyn i IoT Hub-händelser. Detsamma gäller för andra molnbaserade klienter som Functions och Azure Stream Analytics. Om du vill hämta slutpunkten och namnet kan du använda Azure Portal eller .NET SDK.
Använda portalen
Mer information om hur du använder portalen för att hämta den Event Hub-kompatibla slutpunkten och det Event Hub-kompatibla namnet finns i Ansluta till den inbyggda slutpunkten.
Använda .NET SDK
Om du vill använda IoT Hub-anslutningssträng för att återerövra den Event Hubs-kompatibla slutpunkten använder du ett exempel som finns på https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubs. Kodexemplet använder anslutningssträng för att hämta den nya Event Hubs-slutpunkten och återupprätta anslutningen. Visual Studio måste vara installerat.
Köra testtester
Testtester bör inte utföras på IoT-hubbar som används i dina produktionsmiljöer.
Använd inte manuell redundans för att migrera IoT Hub till en annan region
Manuell redundans bör inte användas som en mekanism för att permanent migrera din hubb mellan de geo-kopplade Azure-regionerna. Förutsatt att enheterna ligger närmast hubbens primära region ökar svarstiden för åtgärder som utförs mot IoT-hubben när hubben redundansväxlar till en sekundär region.
Återställning efter fel
Du kan växla tillbaka till den gamla primära regionen genom att utlösa redundansåtgärden en andra gång. Om den ursprungliga redundansåtgärden utfördes för att återställa från ett utökat avbrott i den ursprungliga primära regionen rekommenderar vi att hubben ska återställas till den ursprungliga platsen när platsen har återställts från avbrottssituationen.
Viktigt!
- Användare får bara utföra 2 lyckade redundansväxlingar och 2 lyckade återställningsåtgärder per dag.
- Back to back-redundans-/återställningsåtgärder tillåts inte. Du måste vänta 1 timme mellan dessa åtgärder.
Återställningstid
Även om det fullständiga domännamnet (och därmed anslutningssträng) för IoT Hub-instansen förblir samma efter redundansväxlingen, ändras den underliggande IP-adressen. Tiden för körningsåtgärder som utförs mot din IoT Hub-instans att bli helt i drift efter redundansväxlingen kan uttryckas med hjälp av följande funktion:
Tid att återställa = RTO [10 min – 2 timmar för manuell redundans | 2–26 timmar för Microsoft-initierad redundans] + DNS-spridningsfördröjning + tid det tar för klientprogrammet att uppdatera alla cachelagrade IP-adresser för IoT Hub.
Viktigt!
IoT-SDK:erna cachelagras inte IP-adressen för IoT-hubben. Vi rekommenderar att användarkod som samverkar med SDK:erna inte ska cachelagra IP-adressen för IoT-hubben.
Inaktivera haveriberedskap
IoT Hub tillhandahåller Microsoft-initierad redundans och manuell redundans genom att replikera data till den kopplade regionen för varje IoT-hubb. För vissa regioner kan du undvika datareplikering utanför regionen genom att inaktivera haveriberedskap när du skapar en IoT-hubb. Följande regioner stöder den här funktionen:
- Brasilien, södra; parad region, USA, södra centrala.
- Sydostasien (Singapore); parat område, Asien, östra (Hongkong SAR).
Om du vill inaktivera haveriberedskap i regioner som stöds kontrollerar du att Haveriberedskap har avmarkerats när du skapar din IoT-hubb:
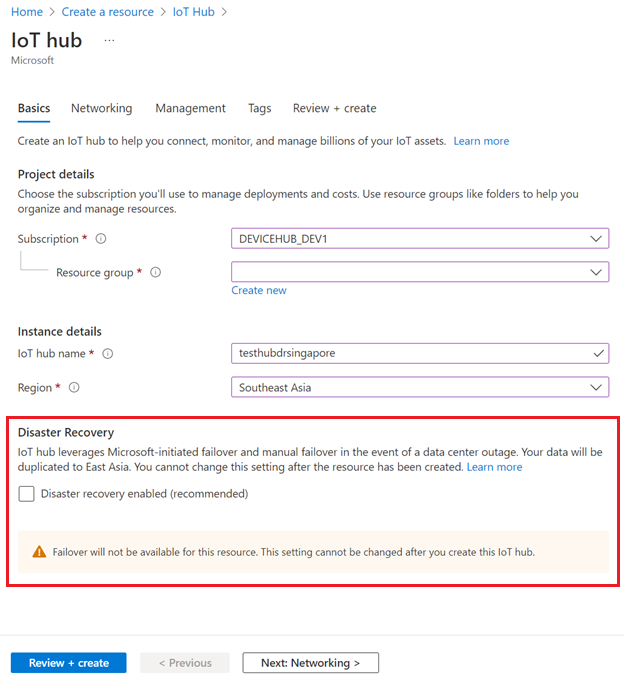
Du kan också inaktivera haveriberedskap när du skapar en IoT-hubb med hjälp av en ARM-mall.
Redundansfunktionen är inte tillgänglig om du inaktiverar haveriberedskap för en IoT-hubb.
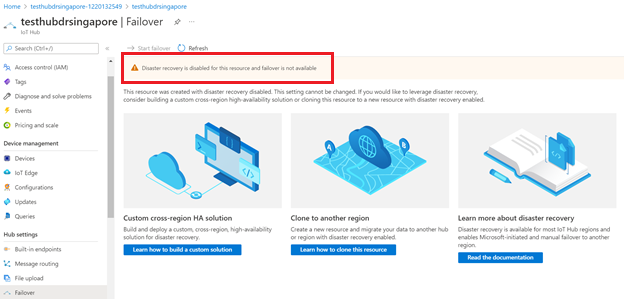
Du kan bara inaktivera haveriberedskap för att undvika datareplikering utanför den kopplade regionen i Brasilien, södra eller Sydostasien när du skapar en IoT-hubb. Om du vill konfigurera din befintliga IoT-hubb för att inaktivera haveriberedskap måste du skapa en ny IoT-hubb med haveriberedskap inaktiverad och migrera din befintliga IoT-hubb manuellt. Vägledning finns i Så här migrerar du en IoT-hubb.
Uppnå ha för flera regioner
Om dina affärsupptidsmål inte uppfylls av den RTO som antingen Microsoft-initierade redundans eller manuella redundansalternativ tillhandahåller, bör du överväga att implementera en automatisk redundansmekanism per enhet mellan regioner. En fullständig behandling av distributionstopologier i IoT-lösningar ligger utanför omfånget för den här artikeln. I artikeln beskrivs den regionala distributionsmodellen för redundans för hög tillgänglighet och haveriberedskap.
I en regional redundansmodell körs lösningens serverdel främst på en datacenterplats. En sekundär IoT-hubb och serverdel distribueras på en annan datacenterplats. Om IoT-hubben i den primära regionen drabbas av ett avbrott eller om nätverksanslutningen från enheten till den primära regionen avbryts, använder enheterna en sekundär tjänstslutpunkt. Du kan förbättra lösningens tillgänglighet genom att implementera en redundansmodell mellan regioner i stället för att stanna kvar i en enda region.
För att implementera en regional redundansmodell med IoT Hub på hög nivå måste du vidta följande steg:
En sekundär IoT-hubb och enhetsroutningslogik: Om tjänsten i din primära region avbryts måste enheterna börja ansluta till den sekundära regionen. Med tanke på de flesta tjänsters tillståndsmedvetna karaktär är det vanligt att lösningsadministratörer utlöser redundansväxlingen mellan regioner. Det bästa sättet att kommunicera den nya slutpunkten till enheter, samtidigt som du behåller kontrollen över processen, är att låta dem regelbundet kontrollera en concierge-tjänst för den aktuella aktiva slutpunkten. Concierge-tjänsten kan vara ett webbprogram som replikeras och hålls nåbart med hjälp av DNS-omdirigeringstekniker (till exempel med Hjälp av Azure Traffic Manager).
Kommentar
IoT Hub-tjänsten är inte en slutpunktstyp som stöds i Azure Traffic Manager. Rekommendationen är att integrera den föreslagna concierge-tjänsten med Azure Traffic Manager genom att implementera API:et för slutpunktens hälsoavsökning.
Replikering av identitetsregister: För att kunna användas måste den sekundära IoT-hubben innehålla alla enhetsidentiteter som kan ansluta till lösningen. Lösningen bör behålla geo-replikerade säkerhetskopior av enhetsidentiteter och ladda upp dem till den sekundära IoT-hubben innan du växlar den aktiva slutpunkten för enheterna. Funktionen för enhetsidentitetsexport i IoT Hub är användbar i den här kontexten. Mer information finns i utvecklarhandboken för IoT Hub – identitetsregister.
Sammanslagningslogik: När den primära regionen blir tillgänglig igen måste alla tillstånd och data som har skapats på den sekundära platsen migreras tillbaka till den primära regionen. Det här tillståndet och data relaterar främst till enhetsidentiteter och programmetadata, som måste sammanfogas med den primära IoT-hubben och andra programspecifika butiker i den primära regionen.
För att förenkla det här steget bör du använda idempotentåtgärder. Idempotent-åtgärder minimerar biverkningarna från den slutliga konsekventa fördelningen av händelser och från dubbletter eller leverans utan beställning av händelser. Dessutom bör programlogik utformas för att tolerera potentiella inkonsekvenser eller något inaktuellt tillstånd. Den här situationen kan inträffa på grund av den extra tid det tar för systemet att läka baserat på mål för återställningspunkter (RPO).
Välj rätt HA/DR-alternativ
Här är en sammanfattning av de HA/DR-alternativ som presenteras i den här artikeln som kan användas som referensram för att välja rätt alternativ som fungerar för din lösning.
| HA/DR-alternativ | RTO | RPO | Kräver manuella åtgärder? | Implementeringskomplexitet | Kostnadspåverkan |
|---|---|---|---|---|---|
| Microsoft-initierad redundans | 2–26 timmar | Se RPO-tabellen ovan | Nej | Ingen | Ingen |
| Manuell redundans | 10 min – 2 timmar | Se RPO-tabellen ovan | Ja | Mycket låg. Du behöver bara utlösa den här åtgärden från portalen. | Ingen |
| Ha för flera regioner | < 1 min | Beror på replikeringsfrekvensen för din anpassade HA-lösning | Nej | Högt | > 1x kostnaden för 1 IoT Hub |