Minnesanvändningsoptimering för Apache Spark
Den här artikeln beskriver hur du optimerar minneshantering av ditt Apache Spark-kluster för bästa prestanda i Azure HDInsight.
Översikt
Spark fungerar genom att placera data i minnet. Att hantera minnesresurser är därför en viktig aspekt av att optimera körningen av Spark-jobb. Det finns flera tekniker som du kan använda för att använda klustrets minne effektivt.
- Föredrar mindre datapartitioner och konto för datastorlek, typer och distribution i partitioneringsstrategin.
- Överväg den nyare, effektivare
Kryo data serialization, snarare än standard-Java-serialiseringen. - Föredrar att använda YARN, eftersom det separerar
spark-submitefter batch. - Övervaka och justera Spark-konfigurationsinställningar.
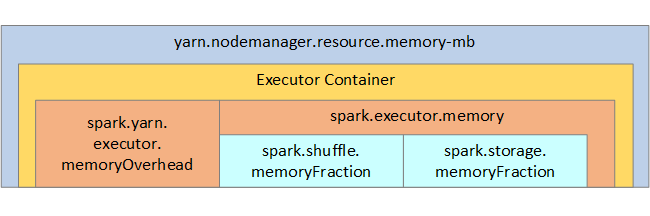
Som referens visas Spark-minnesstrukturen och några nyckelexekutorminnesparametrar i nästa bild.
Överväganden för Spark-minne
Om du använder Apache Hadoop YARN styr YARN det minne som används av alla containrar på varje Spark-nod. Följande diagram visar nyckelobjekten och deras relationer.
Om du vill ta itu med meddelanden om "slut på minne" provar du:
- Granska DAG Management Shuffles. Minska genom att återskapa källdata på kartsidan, förpartitionera (eller bucketisera) källdata, maximera enskilda blandningar och minska mängden data som skickas.
- Föredrar
ReduceByKeymed sin fasta minnesgräns tillGroupByKey, vilket ger aggregeringar, fönster och andra funktioner, men den har ann obundna minnesgräns. - Föredrar
TreeReduce, vilket gör mer arbete på exekutorer eller partitioner, tillReduce, som fungerar alla på drivrutinen. - Använd DataFrames i stället för RDD-objekt på lägre nivå.
- Skapa ComplexTypes som kapslar in åtgärder, till exempel "Top N", olika sammansättningar eller fönsteråtgärder.
Ytterligare felsökningssteg finns i OutOfMemoryError-undantag för Apache Spark i Azure HDInsight.