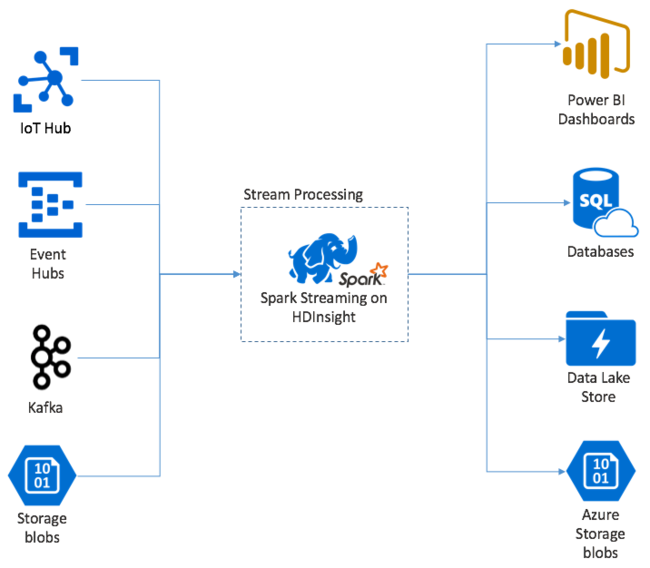
Översikt över Apache Spark Streaming
Apache Spark Streaming tillhandahåller dataströmbearbetning i HDInsight Spark-kluster. Med en garanti för att alla indatahändelser bearbetas exakt en gång, även om ett nodfel inträffar. En Spark Stream är ett tidskrävande jobb som tar emot indata från en mängd olika källor, inklusive Azure Event Hubs. Dessutom: Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ, råa TCP-socketar eller från övervakning av Apache Hadoop YARN-filsystem. Till skillnad från en händelsedriven process matar en Spark Stream-batch in data i tidsfönster. Till exempel ett tvåsekunderssegment och omvandlar sedan varje batch med data med hjälp av åtgärder för att mappa, minska, koppla och extrahera. Spark Stream skriver sedan ut transformerade data till filsystem, databaser, instrumentpaneler och konsolen.
Spark Streaming-program måste vänta en bråkdel av en sekund för att samla in var och micro-batch en av händelserna innan batchen skickas för bearbetning. Däremot bearbetar ett händelsedrivet program varje händelse omedelbart. Spark Streaming-svarstiden är vanligtvis under några sekunder. Fördelarna med mikrobatchmetoden är effektivare databehandling och enklare aggregeringsberäkningar.
Introduktion till DStream
Spark Streaming representerar en kontinuerlig ström av inkommande data med hjälp av en diskret ström som kallas DStream. En DStream kan skapas från indatakällor som Event Hubs eller Kafka. Eller genom att tillämpa transformeringar på en annan DStream.
En DStream innehåller ett abstraktionslager ovanpå rådata för händelser.
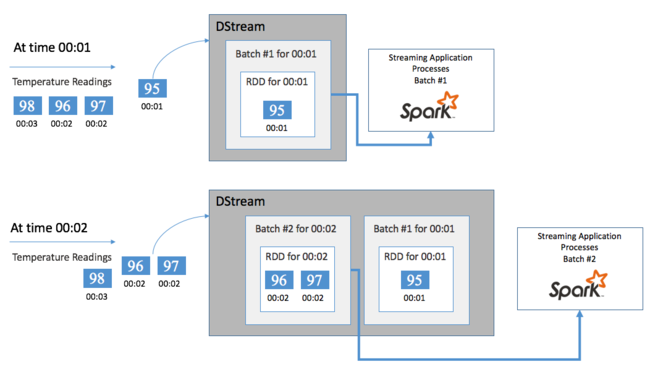
Börja med en enda händelse, till exempel en temperaturavläsning från en ansluten termostat. När den här händelsen kommer till ditt Spark Streaming-program lagras händelsen på ett tillförlitligt sätt, där den replikeras på flera noder. Den här feltoleransen säkerställer att felet för en enskild nod inte leder till förlust av din händelse. Spark-kärnan använder en datastruktur som distribuerar data över flera noder i klustret. Där varje nod vanligtvis underhåller sina egna data i minnet för bästa prestanda. Den här datastrukturen kallas för en elastisk distribuerad datamängd (RDD).
Varje RDD representerar händelser som samlats in under en användardefinierad tidsram som kallas batchintervall. När varje batchintervall förflutit skapas en ny RDD som innehåller alla data från det intervallet. Den kontinuerliga uppsättningen RDD:er samlas in i en DStream. Om batchintervallet till exempel är en sekund långt genererar DStream en batch varje sekund som innehåller en RDD som innehåller alla data som matas in under den sekunden. När du bearbetar DStream visas temperaturhändelsen i någon av dessa batchar. Ett Spark Streaming-program bearbetar de batchar som innehåller händelserna och agerar slutligen på de data som lagras i varje RDD.
Struktur för ett Spark Streaming-program
Ett Spark Streaming-program är ett tidskrävande program som tar emot data från inmatningskällor. Tillämpar transformeringar för att bearbeta data och skickar sedan ut data till ett eller flera mål. Strukturen för ett Spark Streaming-program har en statisk del och en dynamisk del. Den statiska delen definierar var data kommer ifrån, vilken bearbetning som ska utföras på data. Och vart resultaten ska gå. Den dynamiska delen kör programmet på obestämd tid och väntar på en stoppsignal.
Följande enkla program tar till exempel emot en textrad över en TCP-socket och räknar antalet gånger varje ord visas.
Definiera programmet
Programlogikdefinitionen har fyra steg:
- Skapa en StreamingContext.
- Skapa en DStream från StreamingContext.
- Tillämpa transformeringar på DStream.
- Mata ut resultatet.
Den här definitionen är statisk och inga data bearbetas förrän du kör programmet.
Skapa en StreamingContext
Skapa en StreamingContext från SparkContext som pekar på klustret. När du skapar en StreamingContext anger du batchens storlek i sekunder, till exempel:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Skapa en DStream
Med StreamingContext-instansen skapar du en indata-DStream för din indatakälla. I det här fallet tittar programmet efter utseendet på nya filer i den anslutna standardlagringen.
val lines = ssc.textFileStream("/uploads/Test/")
Använda transformeringar
Du implementerar bearbetningen genom att tillämpa transformeringar på DStream. Det här programmet tar emot en textrad i taget från filen och delar upp varje rad i ord. Och använder sedan ett map-reduce-mönster för att räkna antalet gånger varje ord visas.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Utdataresultat
Push-överför transformeringsresultatet till målsystemen genom att tillämpa utdataåtgärder. I det här fallet skrivs resultatet av varje körning genom beräkningen ut i konsolens utdata.
wordCounts.print()
Kör appen
Starta strömningsprogrammet och kör tills en avslutningssignal tas emot.
ssc.start()
ssc.awaitTermination()
Mer information om Spark Stream-API:et finns i Programmeringsguide för Apache Spark-strömning.
Följande exempelprogram är fristående, så du kan köra det i en Jupyter Notebook. Det här exemplet skapar en falsk datakälla i klassen DummySource som matar ut värdet för en räknare och den aktuella tiden i millisekunder var femte sekund. Ett nytt StreamingContext-objekt har ett batchintervall på 30 sekunder. Varje gång en batch skapas undersöker det strömmande programmet den RDD som skapas. Konverterar sedan RDD:t till en Spark DataFrame och skapar en tillfällig tabell över DataFrame.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Vänta i cirka 30 sekunder efter att programmet har startats ovan. Sedan kan du fråga DataFrame regelbundet för att se den aktuella uppsättningen värden som finns i batchen, till exempel med hjälp av den här SQL-frågan:
%%sql
SELECT * FROM demo_numbers
De resulterande utdata ser ut som följande utdata:
| värde | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Det finns sex värden eftersom DummySource skapar ett värde var 5:e sekund och programmet genererar en batch var 30:e sekund.
Skjutfönster
Om du vill utföra aggregerade beräkningar på din DStream under en viss tidsperiod, till exempel för att få en medeltemperatur under de senaste två sekunderna, använder du de sliding window åtgärder som ingår i Spark Streaming. Ett skjutfönster har en varaktighet (fönsterlängden) och det intervall under vilket fönstrets innehåll utvärderas (bildintervallet).
Skjutfönster kan överlappa varandra, till exempel kan du definiera ett fönster med en längd på två sekunder, som skjuts var sekund. Den här åtgärden innebär att varje gång du gör en aggregeringsberäkning innehåller fönstret data från den sista sekunden i föregående fönster. Och alla nya data inom en sekund.
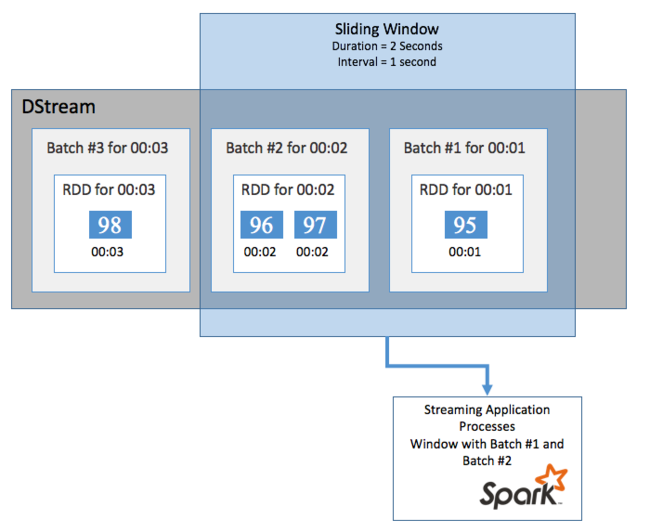
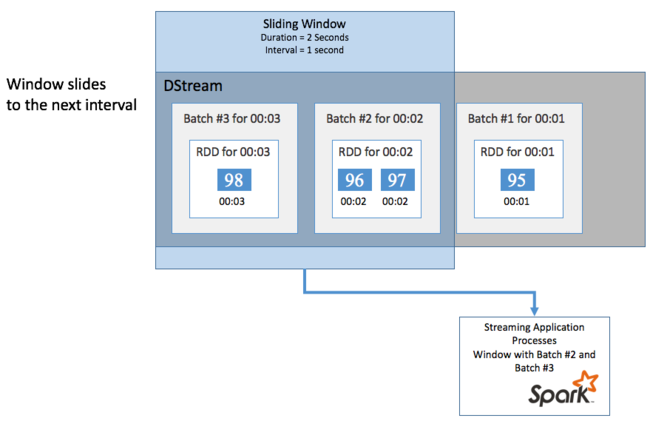
I följande exempel uppdateras koden som använder DummySource för att samla in batcharna i ett fönster med en varaktighet på en minut och en bild på en minut.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Efter den första minuten finns det 12 poster – sex poster från var och en av de två batcharna som samlats in i fönstret.
| värde | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
De skjutfönsterfunktioner som är tillgängliga i Spark Streaming-API:et inkluderar fönster, countByWindow, reduceByWindow och countByValueAndWindow. Mer information om dessa funktioner finns i Transformeringar på DStreams.
Kontrollpunkter
För att leverera återhämtning och feltolerans förlitar sig Spark Streaming på kontrollpunkter för att säkerställa att dataströmbearbetningen kan fortsätta oavbruten, även vid nodfel. Spark skapar kontrollpunkter för beständig lagring (Azure Storage eller Data Lake Storage). Dessa kontrollpunkter lagrar metadata för strömmande program, till exempel konfigurationen och de åtgärder som definieras av programmet. Dessutom har alla batchar som placerats i kö men ännu inte bearbetats. Ibland inkluderar kontrollpunkterna även att spara data i RDD:erna för att snabbare återskapa tillståndet för data från det som finns i RDD:erna som hanteras av Spark.
Distribuera Spark Streaming-program
Du skapar vanligtvis ett Spark Streaming-program lokalt i en JAR-fil. Distribuera den sedan till Spark på HDInsight genom att kopiera JAR-filen till standardansluten lagring. Du kan starta programmet med LIVY REST API:er som är tillgängliga från klustret med hjälp av en POST-åtgärd. Brödtexten i POST innehåller ett JSON-dokument som tillhandahåller sökvägen till din JAR. Och namnet på den klass vars huvudmetod definierar och kör strömningsprogrammet, och eventuellt resurskraven för jobbet (till exempel antalet exekutorer, minne och kärnor). Dessutom kräver alla konfigurationsinställningar som programkoden kräver.
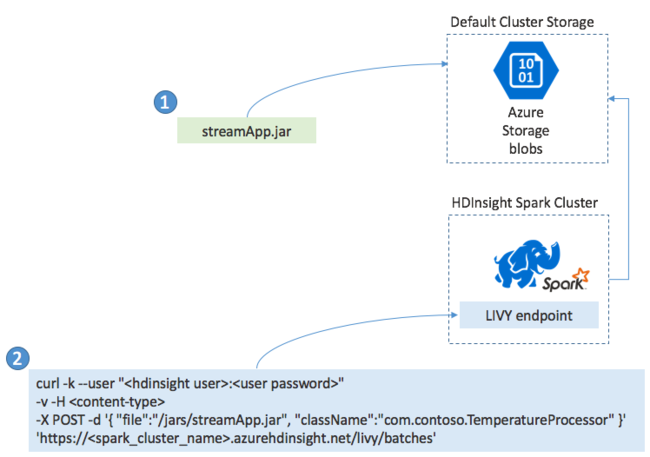
Status för alla program kan också kontrolleras med en GET-begäran mot en LIVY-slutpunkt. Slutligen kan du avsluta ett program som körs genom att utfärda en DELETE-begäran mot LIVY-slutpunkten. Mer information om LIVY-API :et finns i Fjärrjobb med Apache LIVY