Storleksguide för Azure HDInsight Interaktiv fråga Cluster (Hive LLAP)
Det här dokumentet beskriver storleken på HDInsight Interaktiv fråga-klustret (Hive LLAP-klustret) för en typisk arbetsbelastning för att uppnå rimlig prestanda. Observera att rekommendationerna i det här dokumentet är allmänna riktlinjer och att specifika arbetsbelastningar kan behöva justeras specifikt.
Azure Default VM Types for HDInsight Interaktiv fråga Cluster (LLAP)
| Nodtyp | Instans | Storlek |
|---|---|---|
| Head | D13 v2 | 8 vcpus, 56 GB RAM,400 GB SSD |
| Arbetare | D14 v2 | 16 vcpus, 112 GB RAM, 800 GB SSD |
| ZooKeeper | A4 v2 | 4 vcpus, 8 GB RAM, 40 GB SSD |
Obs! Alla rekommenderade konfigurationsvärden baseras på arbetsnod av typen D14 v2
Konfiguration:
| Konfigurationsnyckel | Rekommenderat värde | beskrivning |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | 102400 (MB) | Totalt minne i MB för alla YARN-containrar på en nod |
| yarn.scheduler.maximum-allocation-mb | 102400 (MB) | Den maximala allokeringen för varje containerbegäran på RM, i MBs. Minnesbegäranden som är högre än det här värdet börjar inte gälla |
| yarn.scheduler.maximum-allocation-vcores | 12 | Det maximala antalet CPU-kärnor för varje containerbegäran i Resource Manager. Begäranden som är högre än det här värdet börjar inte gälla. |
| yarn.nodemanager.resource.cpu-vcores | 12 | Antal CPU-kärnor per NodeManager som kan allokeras för containrar. |
| yarn.scheduler.capacity.root.llap.capacity | 85 (%) | YARN-kapacitetsallokering för LLAP-kö |
| tez.am.resource.memory.mb | 4 096 (MB) | Mängden minne i MB som ska användas av tez AppMaster |
| hive.server2.tez.sessions.per.default.queue | <number_of_worker_nodes> | Antalet sessioner för varje kö med namnet i köerna hive.server2.tez.default.. Det här talet motsvarar antalet frågekoordinatorer (Tez AMs) |
| hive.tez.container.size | 4 096 (MB) | Angiven Tez-containerstorlek i MB |
| hive.llap.daemon.num.executors | 19 | Antal utförare per LLAP-daemon |
| hive.llap.io.threadpool.size | 19 | Storlek på trådpool för utförare |
| hive.llap.daemon.yarn.container.mb | 81920 (MB) | Totalt minne i MB som används av enskilda LLAP-daemoner (minne per daemon) |
| hive.llap.io.memory.size | 242688 (MB) | Cachestorlek i MB per LLAP-daemon angivet SSD-cache är aktiverat |
| hive.auto.convert.join.noconditionaltask.size | 2048 (MB) | minnesstorlek i MB för att göra kartkoppling |
LLAP-arkitektur/komponenter:
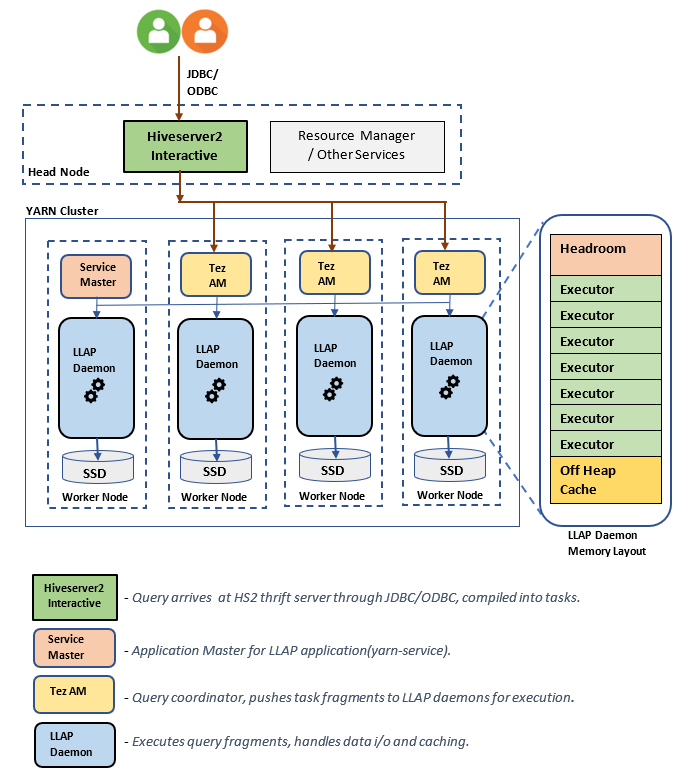
Storleksuppskattningar för LLAP-daemon:
1. Fastställa total YARN-minnesallokering för alla containrar på en nod
Konfiguration: yarn.nodemanager.resource.memory-mb
Det här värdet anger en maximal summa minne i MB som kan användas av YARN-containrarna på varje nod. Det angivna värdet bör vara mindre än den totala mängden fysiskt minne på noden.
Totalt minne för alla YARN-containrar på en nod = (Totalt fysiskt minne – minne för OS + andra tjänster)
Ange det här värdet till ~90 % av den tillgängliga RAM-storleken.
För D14 v2 är det rekommenderade värdet 102400 MB.
2. Fastställa maximal mängd minne per YARN-containerbegäran
Konfiguration: yarn.scheduler.maximum-allocation-mb
Det här värdet anger den maximala allokeringen för varje containerbegäran i Resource Manager i MB. Minnesbegäranden som är högre än det angivna värdet börjar inte gälla. Resource Manager kan ge minne till containrar i steg av yarn.scheduler.minimum-allocation-mb och får inte överskrida den storlek som anges av yarn.scheduler.maximum-allocation-mb. Det angivna värdet får inte vara mer än det totala angivna minnet för alla containrar på noden som anges av yarn.nodemanager.resource.memory-mb.
För D14 v2-arbetsnoder är det rekommenderade värdet 102400 MB
3. Fastställa maximal mängd vcores per YARN-containerbegäran
Konfiguration: yarn.scheduler.maximum-allocation-vcores
Det här värdet anger det maximala antalet virtuella CPU-kärnor för varje containerbegäran i Resource Manager. Att begära ett högre antal vcores än det här värdet börjar inte gälla. Det är en global egenskap för YARN-schemaläggaren. För LLAP-daemoncontainern kan det här värdet anges till 75 % av det totala antalet tillgängliga vcores. Återstående 25 % bör reserveras för NodeManager, DataNode och andra tjänster som körs på arbetsnoderna.
Det finns 16 vcores virtuella D14 v2-datorer och 75 % av det totala antalet 16 vcores kan användas av LLAP-daemoncontainern.
För D14 v2 är det rekommenderade värdet 12.
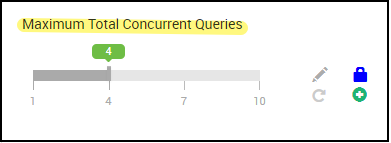
4. Antal samtidiga frågor
Konfiguration: hive.server2.tez.sessions.per.default.queue
Det här konfigurationsvärdet bestämmer antalet Tez-sessioner som kan startas parallellt. Dessa Tez-sessioner startas för var och en av de köer som anges av "hive.server2.tez.default.queues". Det motsvarar antalet Tez-AMs (frågekoordinatorer). Vi rekommenderar att du är samma som antalet arbetsnoder. Antalet Tez-AMs kan vara högre än antalet LLAP-daemonnoder. Tez AM:s primära ansvar är att samordna frågekörningen och tilldela frågeplansfragment till motsvarande LLAP-daemoner för körning. Behåll det här värdet som flera av många LLAP-daemonnoder för att uppnå högre dataflöde.
Standard-HDInsight-kluster har fyra LLAP-daemoner som körs på fyra arbetsnoder, så det rekommenderade värdet är 4.
Ambari UI-skjutreglage för Hive-konfigurationsvariabel hive.server2.tez.sessions.per.default.queue:
5. Tez Container och Tez Application Master storlek
Konfiguration: tez.am.resource.memory.mb, hive.tez.container.size
tez.am.resource.memory.mb – definierar Tez-programmets huvudstorlek.
Det rekommenderade värdet är 4 096 MB.
hive.tez.container.size – definierar mängden minne som ges för Tez-containern. Det här värdet måste anges mellan YARN minsta containerstorlek (yarn.scheduler.minimum-allocation-mb) och YARN största containerstorlek (yarn.scheduler.maximum-allocation-mb). LLAP-daemonkörningarna använder det här värdet för att begränsa minnesanvändningen per körning.
Det rekommenderade värdet är 4 096 MB.
6. LLAP-kökapacitetsallokering
Konfiguration: yarn.scheduler.capacity.root.llap.capacity
Det här värdet anger en procentandel av kapaciteten som ges till LLAP-kön. Kapacitetsallokeringarna kan ha olika värden för olika arbetsbelastningar beroende på hur YARN-köerna konfigureras. Om din arbetsbelastning är skrivskyddad bör det fungera att ange den så hög som 90 % av kapaciteten. Men om din arbetsbelastning är en blandning av åtgärder för uppdatering/borttagning/sammanslagning med hanterade tabeller rekommenderar vi att du ger 85 % av kapaciteten för LLAP-kön. Den återstående kapaciteten på 15 % kan användas av andra uppgifter, till exempel komprimering osv. för att allokera containrar från standardkön. På så sätt kommer uppgifter i standardkön inte att beröva YARN-resurser.
För D14v2-arbetsnoder är det rekommenderade värdet för LLAP-kön 85.
(För skrivskyddade arbetsbelastningar kan den ökas upp till 90 som lämpliga.)
7. LLAP-daemoncontainerstorlek
Konfiguration: hive.llap.daemon.yarn.container.mb
LLAP-daemon körs som en YARN-container på varje arbetsnod. Den totala minnesstorleken för LLAP-daemoncontainern beror på följande faktorer:
- Konfigurationer av YARN-containerstorlek (yarn.scheduler.minimum-allocation-mb, yarn.scheduler.maximum-allocation-mb, yarn.nodemanager.resource.memory-mb)
- Antal Tez-datorer på en nod
- Totalt minne som konfigurerats för alla containrar på en nod och LLAP-kökapacitet
Minne som behövs av Tez Application Masters (Tez AM) kan beräknas på följande sätt.
Tez AM fungerar som frågekoordinator och antalet Tez AMs ska konfigureras baserat på många samtidiga frågor som ska hanteras. Teoretiskt sett kan vi överväga en Tez AM per arbetsnod. Det är dock möjligt att du kan se mer än en Tez AM på en arbetsnod. I beräkningssyfte förutsätter vi en enhetlig fördelning av Tez-AMs över alla LLAP-daemonnoder/arbetsnoder.
Vi rekommenderar att du har 4 GB minne per Tez AM.
Antal Tez Ams = värde som anges av Hive config hive.server2.tez.sessions.per.default.queue.
Antal LLAP-daemonnoder = som anges av env-variabeln num_llap_nodes_for_llap_daemons i Ambari-användargränssnittet.
Tez AM container size = value specified by Tez config tez.am.resource.memory.mb.
Tez AM-minne per nod = (ceil(Antal Tez AMs / Antal LLAP-daemonnoder) x Tez AM-containerstorlek**)**
För D14 v2 har standardkonfigurationen fyra Tez-AMs och fyra LLAP-daemonnoder.
Tez AM-minne per nod = (ceil(4/4) x 4 GB) = 4 GB
Totalt tillgängligt minne för LLAP-kö per arbetsnod kan beräknas på följande sätt:
Det här värdet beror på den totala mängden minne som är tillgängligt för alla YARN-containrar på en nod (yarn.nodemanager.resource.memory-mb) och den procentandel kapacitet som konfigurerats för LLAP-kön (yarn.scheduler.capacity.root.llap.capacity).
Totalt minne för LLAP-kön på arbetsnoden = Totalt tillgängligt minne för alla YARN-containrar på en nod x Procentandel kapacitet för LLAP-kön.
För D14 v2 är det här värdet (100 GB x 0,85) = 85 GB.
LLAP-daemoncontainerns storlek beräknas på följande sätt.
LLAP-daemoncontainerstorlek = (Totalt minne för LLAP-kö på en arbetsnod) – (Tez AM-minne per nod) – (Containerstorlek för Tjänsthanteraren)
Det finns bara en tjänsthanterare (programhanterare för LLAP-tjänsten) i klustret som skapas på en av arbetsnoderna. I beräkningssyfte överväger vi en tjänsthanterare per arbetsnod.
För arbetsnoden D14 v2 är HDI 4.0 – det rekommenderade värdet (85 GB – 4 GB – 1 GB)) = 80 GB
8. Fastställa antalet utförare per LLAP-daemon
Konfiguration: hive.llap.daemon.num.executors, hive.llap.io.threadpool.size
hive.llap.daemon.num.executors:
Den här konfigurationen styr antalet exekverare som kan köra uppgifter parallellt per LLAP-daemon. Det här värdet beror på antalet virtuella kärnor, mängden minne som används per exekveringar och mängden tillgängligt minne för LLAP-daemon-containern. Antalet utförare kan överprenumereras till 120 % av tillgängliga virtuella kärnor per arbetsnod. Den bör dock justeras om den inte uppfyller minneskraven baserat på minne som behövs per köre och LLAP-daemoncontainerns storlek.
Varje exekverare motsvarar en Tez-container och kan förbruka 4 GB (Tez-containerstorlek) minne. Alla utförare i LLAP-daemon delar samma heapminne. Med antagandet att inte alla exekverare kör minnesintensiva åtgärder samtidigt kan du överväga 75 % av Tez-containerstorleken (4 GB) per exekverare. På så sätt kan du öka antalet exekverare genom att ge varje exekverare mindre minne (till exempel 3 GB) för ökad parallellitet. Vi rekommenderar dock att du justerar den här inställningen för målarbetsbelastningen.
Det finns 16 virtuella kärnor på virtuella D14 v2-datorer. För D14 v2 är det rekommenderade värdet för antalet utförare (16 virtuella kärnor x 120 %) ~= 19 på varje arbetsnod med 3 GB per köre.
hive.llap.io.threadpool.size:
Det här värdet anger storleken på trådpoolen för utförare. Eftersom exekverare har åtgärdats enligt angivet är det samma som antalet exekverare per LLAP-daemon.
För D14 v2 är det rekommenderade värdet 19.
9. Fastställa llap-daemoncachestorlek
Konfiguration: hive.llap.io.memory.size
LLAP-daemoncontainerns minne består av följande komponenter;
- Huvudrum
- Heapminne som används av utförare (Xmx)
- Minnesintern cache per daemon (dess minnesstorlek utanför heap, inte tillämpligt när SSD-cache är aktiverat)
- Cachemetadatastorlek i minnet (gäller endast när SSD-cachen är aktiverad)
Utrymmesstorlek: Den här storleken anger en del av minnet utanför heapen som används för omkostnader för virtuella Java-datorer (metaområde, trådstacken, gc datastrukturer osv.). I allmänhet är den här kostnaden cirka 6 % av heapstorleken (Xmx). För att vara på den säkrare sidan kan det här värdet beräknas som 6 % av den totala LLAP-daemonminnesstorleken.
För D14 v2 är det rekommenderade värdet ceil(80 GB x 0,06) ~= 4 GB.
Heap size(Xmx): Det är mängden heapminne som är tillgängligt för alla utförare.
Total heapstorlek = Antal exekverare x 3 GB
För D14 v2 är det här värdet 19 x 3 GB = 57 GB
Ambari environment variable for LLAP heap size:

När SSD-cachen är inaktiverad är minnesintern cache mängden minne som finns kvar när du har tagit ut utrymmesstorlek och Heap-storlek från LLAP-daemoncontainerns storlek.
Cachestorleksberäkningen skiljer sig åt när SSD-cachen är aktiverad.
Om du anger hive.llap.io.allocator.mmap = true aktiveras SSD-cachelagring.
När SSD-cachen är aktiverad används en del av minnet för att lagra metadata för SSD-cachen. Metadata lagras i minnet och förväntas vara ~8 % av SSD-cachestorleken.
SSD Cache in-memory metadata size = LLAP daemon container size - (Head room + Heap size)
För D14 v2, med HDI 4.0, SSD cacheminne metadatastorlek = 80 GB - (4 GB + 57 GB) = 19 GB
Med tanke på storleken på tillgängligt minne för lagring av SSD-cachemetadata kan vi beräkna storleken på SSD-cachen som kan stödjas.
Storlek på SSD-cache in-memory = LLAP daemon containerstorlek - (Head rum + Heap storlek) = 19 GB
Storleken på SSD-cache = storleken på minnesinterna metadata för SSD-cache (19 GB) /0,08 (8 procent)
För D14 v2 och HDI 4.0 rekommenderas SSD-cachestorlek = 19 GB/0,08 ~= 237 GB
10. Justera kartkopplingsminne
Konfiguration: hive.auto.convert.join.noconditionaltask.size
Kontrollera att hive.auto.convert.join.noconditionaltask har aktiverats för att den här parametern ska börja gälla.
Den här konfigurationen avgör tröskelvärdet för MapJoin-val av Hive-optimerare som anser att överprenumerering av minne från andra utförare har mer utrymme för minnesinterna hash-tabeller för att tillåta fler konverteringar av kartkopplingar. Med tanke på 3 GB per köre kan den här storleken överprenumereras till 3 GB, men en del heapminne kan också användas för sorteringsbuffertar, shuffle-buffertar osv. av de andra åtgärderna.
Så för D14 v2, med 3 GB minne per köre, rekommenderar vi att du anger det här värdet till 2 048 MB.
(Obs! Det här värdet kan behöva justeringar som är lämpliga för din arbetsbelastning. Om du ställer in det här värdet för lågt kanske du inte använder funktionen autokonvertera. Och om du ställer in den för högt kan det leda till minnesfel eller GC-pauser som kan leda till sämre prestanda.)
11. Antal LLAP-daemoner
Miljövariabler i Ambari: num_llap_nodes, num_llap_nodes_for_llap_daemons
num_llap_nodes – anger antalet noder som används av Hive LLAP-tjänsten, omfattar detta noder som kör LLAP-daemon, LLAP Service Master och Tez Application Master (Tez AM).
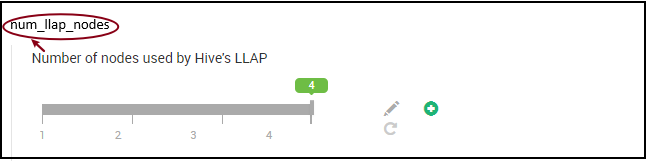
num_llap_nodes_for_llap_daemons – angivet antal noder som endast används för LLAP-daemoner. LLAP-daemoncontainerstorlekar är inställda på maximalt anpassa nod, så det resulterar i en llap daemon på varje nod.

Vi rekommenderar att du behåller båda värdena på samma sätt som antalet arbetsnoder i Interaktiv fråga kluster.
Överväganden för arbetsbelastningshantering
Om du vill aktivera arbetsbelastningshantering för LLAP kontrollerar du att du reserverar tillräckligt med kapacitet för att arbetsbelastningshanteringen ska fungera som förväntat. Arbetsbelastningshanteringen kräver konfiguration av en anpassad YARN-kö, som är utöver llap kön. Se till att du delar upp den totala klusterresurskapaciteten mellan llap kön och arbetsbelastningshanteringskön i enlighet med dina arbetsbelastningskrav.
Arbetsbelastningshantering skapar Tez Application Masters (Tez AMs) när en resursplan aktiveras.
Obs!
- Tez AMs som skapas genom att aktivera en resursplan förbrukar resurser från arbetsbelastningshanteringskön enligt vad som anges av
hive.server2.tez.interactive.queue. - Antalet virtuella Tez-datorer beror på värdet
QUERY_PARALLELISMför det som anges i resursplanen. - När arbetsbelastningshanteringen är aktiv används inte Tez AMs i LLAP-kön. Endast Tez AMs från arbetsbelastningshanteringskön används för frågesamordning. Virtuella datorer i
llapkön används när arbetsbelastningshantering inaktiveras.
Till exempel: Total klusterkapacitet = 100 GB minne, uppdelat mellan LLAP, arbetsbelastningshantering och standardköer enligt följande:
- LLAP-kökapacitet = 70 GB
- Kökapacitet för arbetsbelastningshantering = 20 GB
- Standardkökapacitet = 10 GB
Med 20 GB i kökapacitet för arbetsbelastningshantering kan en resursplan ange QUERY_PARALLELISM värdet som fem, vilket innebär att arbetsbelastningshantering kan starta fem Tez-AMs med 4 GB containerstorlek vardera. Om QUERY_PARALLELISM är högre än kapaciteten kan vissa Tez AMs sluta svara i ACCEPTED tillståndet. Hive server 2 Interactive kan inte skicka frågefragment till de Tez AMs som inte är i RUNNING tillstånd.
Nästa steg
Om det inte gick att lösa problemet genom att ange dessa värden kan du gå till något av följande...
Få svar från Azure-experter via Azure Community Support.
Anslut med @AzureSupport – det officiella Microsoft Azure-kontot för att förbättra kundupplevelsen genom att ansluta Azure-communityn till rätt resurser: svar, support och experter.
Om du behöver mer hjälp kan du skicka en supportbegäran från Azure Portal. Välj Support i menyraden eller öppna hubben Hjälp + support . Mer detaljerad information finns i Skapa en Azure Support begäran. Tillgång till support för prenumerationshantering och fakturering ingår i din Microsoft Azure-prenumeration och teknisk support ges via ett supportavtal för Azure.
Andra referenser: