Använda Apache Oozie med Apache Hadoop för att definiera och köra ett arbetsflöde på Azure HDInsight som körs på Linux
Lär dig hur du använder Apache Oozie med Apache Hadoop i Azure HDInsight. Oozie är ett arbetsflödes- och samordningssystem som hanterar Hadoop-jobb. Oozie är integrerat med Hadoop-stacken och stöder följande jobb:
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
Du kan också använda Oozie för att schemalägga jobb som är specifika för ett system, till exempel Java-program eller shell-skript.
Kommentar
Ett annat alternativ för att definiera arbetsflöden med HDInsight är att använda Azure Data Factory. Mer information om Data Factory finns i Använda Apache Pig och Apache Hive med Data Factory. Information om hur du använder Oozie i kluster med Enterprise Security Package finns i Köra Apache Oozie i HDInsight Hadoop-kluster med Enterprise Security Package.
Förutsättningar
Ett Hadoop-kluster i HDInsight. Se Kom igång med HDInsight i Linux.
En SSH-klient. Se Ansluta till HDInsight (Apache Hadoop) med hjälp av SSH.
En Azure SQL Database. Se Skapa en databas i Azure SQL Database i Azure Portal. Den här artikeln använder en databas med namnet oozietest.
URI-schemat för dina klusters primära lagring.
wasb://för Azure Storage,abfs://för Azure Data Lake Storage Gen2 elleradl://för Azure Data Lake Storage Gen1. Om säker överföring är aktiverad för Azure Storage blirwasbs://URI:n . Se även säker överföring.
Exempelarbetsflöde
Arbetsflödet som används i det här dokumentet innehåller två åtgärder. Åtgärder är definitioner för uppgifter, till exempel att köra Hive, Sqoop, MapReduce eller andra processer:
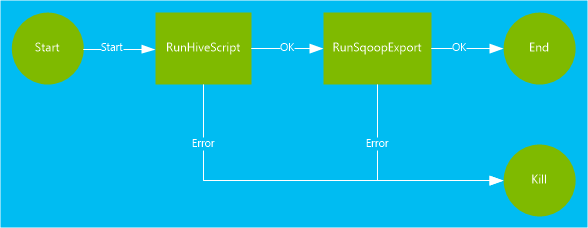
En Hive-åtgärd kör ett HiveQL-skript för att extrahera poster från som
hivesampletableingår i HDInsight. Varje rad med data beskriver ett besök från en specifik mobil enhet. Postformatet visas som följande text:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1Hive-skriptet som används i det här dokumentet räknar det totala antalet besök för varje plattform, till exempel Android eller iPhone, och lagrar antalet till en ny Hive-tabell.
Mer information om Hive finns i [Use Apache Hive with HDInsight][hdinsight-use-hive].
En Sqoop-åtgärd exporterar innehållet i den nya Hive-tabellen till en tabell som skapats i Azure SQL Database. Mer information om Sqoop finns i Använda Apache Sqoop med HDInsight.
Kommentar
Information om vilka Oozie-versioner som stöds i HDInsight-kluster finns i Nyheter i Hadoop-klusterversionerna som tillhandahålls av HDInsight.
Skapa arbetskatalogen
Oozie förväntar sig att du lagrar alla resurser som krävs för ett jobb i samma katalog. I det här exemplet används wasbs:///tutorials/useoozie. Utför följande steg för att skapa den här katalogen:
Redigera koden nedan för att ersätta
sshusermed SSH-användarnamnet för klustret och ersättCLUSTERNAMEmed namnet på klustret. Ange sedan koden för att ansluta till HDInsight-klustret med hjälp av SSH.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netAnvänd följande kommando för att skapa katalogen:
hdfs dfs -mkdir -p /tutorials/useoozie/dataKommentar
Parametern
-pgör att alla kataloger skapas i sökvägen. Katalogendataanvänds för att lagra data som används av skriptetuseooziewf.hql.Redigera koden nedan för att ersätta
sshusermed ditt SSH-användarnamn. Använd följande kommando för att se till att Oozie kan personifiera ditt användarkonto:sudo adduser sshuser usersKommentar
Du kan ignorera fel som anger att användaren redan är medlem i
usersgruppen.
Lägga till en databasdrivrutin
Det här arbetsflödet använder Sqoop för att exportera data till SQL-databasen. Därför måste du ange en kopia av JDBC-drivrutinen som används för att interagera med SQL-databasen. Om du vill kopiera JDBC-drivrutinen till arbetskatalogen använder du följande kommando från SSH-sessionen:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Viktigt!
Kontrollera den faktiska JDBC-drivrutinen som finns på /usr/share/java/.
Om arbetsflödet använde andra resurser, till exempel en jar som innehåller ett MapReduce-program, måste du även lägga till dessa resurser.
Definiera Hive-frågan
Använd följande steg för att skapa ett Hive-frågespråk (HiveQL) som definierar en fråga. Du använder frågan i ett Oozie-arbetsflöde senare i det här dokumentet.
Från SSH-anslutningen använder du följande kommando för att skapa en fil med namnet
useooziewf.hql:nano useooziewf.hqlNär GNU Nano-redigeraren har öppnats använder du följande fråga som innehållet i filen:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;Det finns två variabler som används i skriptet:
${hiveTableName}: Innehåller namnet på tabellen som ska skapas.${hiveDataFolder}: Innehåller platsen där du kan lagra datafilerna för tabellen.Arbetsflödesdefinitionsfilen, workflow.xml i den här artikeln, skickar dessa värden till det här HiveQL-skriptet vid körning.
Spara filen genom att välja Ctrl+X, ange Y och sedan Retur.
Använd följande kommando för att kopiera
useooziewf.hqltillwasbs:///tutorials/useoozie/useooziewf.hql:hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlDet här kommandot lagrar
useooziewf.hqlfilen i den HDFS-kompatibla lagringen för klustret.
Definiera arbetsflödet
Oozie-arbetsflödesdefinitioner skrivs i Hadoop Process Definition Language (hPDL), som är ett XML-processdefinitionsspråk. Använd följande steg för att definiera arbetsflödet:
Använd följande instruktion för att skapa och redigera en ny fil:
nano workflow.xmlNär nanoredigeraren har öppnats anger du följande XML som filinnehåll:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>Det finns två åtgärder som definierats i arbetsflödet:
RunHiveScript: Den här åtgärden är startåtgärden och köruseooziewf.hqlHive-skriptet.RunSqoopExport: Den här åtgärden exporterar data som skapats från Hive-skriptet till en SQL-databas med hjälp av Sqoop. Den här åtgärden körs bara om åtgärdenRunHiveScriptlyckas.Arbetsflödet har flera poster, till exempel
${jobTracker}. Du ersätter dessa poster med de värden som du använder i jobbdefinitionen. Du skapar jobbdefinitionen senare i det här dokumentet.Observera
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>även posten i avsnittet Sqoop. Den här posten instruerar Oozie att göra det här arkivet tillgängligt för Sqoop när den här åtgärden körs.
Spara filen genom att välja Ctrl+X, ange Y och sedan Retur.
Använd följande kommando för att kopiera
workflow.xmlfilen till/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Skapa en tabell
Kommentar
Det finns många sätt att ansluta till SQL Database för att skapa en tabell. Följande steg använder FreeTDS från HDInsight-klustret.
Använd följande kommando för att installera FreeTDS i HDInsight-klustret:
sudo apt-get --assume-yes install freetds-dev freetds-binRedigera koden nedan för att ersätta
<serverName>med ditt logiska SQL Server-namn och<sqlLogin>med serverinloggningen. Ange kommandot för att ansluta till den nödvändiga SQL-databasen. Ange lösenordet i prompten.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestDu får utdata som följande text:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>Vid uppmaningen
1>anger du följande rader:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GONär instruktionen
GOhar angivits värderas de föregående instruktionerna. Dessa instruktioner skapar en tabell med namnetmobiledata, som används av arbetsflödet.Kontrollera att tabellen har skapats genom att använda följande kommandon:
SELECT * FROM information_schema.tables GODu ser utdata som följande text:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLEAvsluta tsql-verktyget genom att ange
exiti kommandotolken1>.
Skapa jobbdefinitionen
Jobbdefinitionen beskriver var du hittar workflow.xml. Den beskriver också var du hittar andra filer som används av arbetsflödet, till exempel useooziewf.hql. Dessutom definierar den värdena för egenskaper som används i arbetsflödet och de associerade filerna.
Använd följande kommando för att hämta den fullständiga adressen för standardlagringen. Den här adressen används i konfigurationsfilen som du skapar i nästa steg.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlDet här kommandot returnerar information som följande XML:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Kommentar
Om HDInsight-klustret använder Azure Storage som standardlagring börjar elementinnehållet
<value>medwasbs://. Om Azure Data Lake Storage Gen1 används i stället börjar det medadl://. Om Azure Data Lake Storage Gen2 används börjar det medabfs://.Spara innehållet i elementet
<value>eftersom det används i nästa steg.Redigera xml nedan enligt följande:
Platshållarvärde Ersatt värde wasbs://mycontainer@mystorageaccount.blob.core.windows.net Värde som tagits emot från steg 1. administratör Ditt inloggningsnamn för HDInsight-klustret om det inte är administratör. serverName Azure SQL Database-servernamn. sqlLogin Azure SQL Database-serverinloggning. sqlPassword Inloggningslösenord för Azure SQL Database-server. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>Merparten av informationen i den här filen används för att fylla i de värden som används i filerna workflow.xml eller ooziewf.hql, till exempel
${nameNode}. Om sökvägen är enwasbssökväg måste du använda den fullständiga sökvägen. Förkorta det inte till barawasbs:///. Postenoozie.wf.application.pathdefinierar var filen workflow.xml ska hittas. Den här filen innehåller arbetsflödet som kördes av det här jobbet.Använd följande kommando för att skapa Oozie-jobbdefinitionskonfigurationen:
nano job.xmlNär nanoredigeraren har öppnats klistrar du in den redigerade XML:en som innehållet i filen.
Spara filen genom att välja Ctrl+X, ange Y och sedan Retur.
Skicka och hantera jobbet
Följande steg använder Oozie-kommandot för att skicka och hantera Oozie-arbetsflöden i klustret. Oozie-kommandot är ett användarvänligt gränssnitt över Oozie REST API.
Viktigt!
När du använder Oozie-kommandot måste du använda FQDN för HDInsight-huvudnoden. Det här fullständiga domännamnet är endast tillgängligt från klustret, eller om klustret finns i ett virtuellt Azure-nätverk, från andra datorer i samma nätverk.
Använd följande kommando för att hämta URL:en till Oozie-tjänsten:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlDetta returnerar information som följande XML:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>Delen
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozieär den URL som ska användas med Oozie-kommandot.Redigera koden för att ersätta URL:en med den som du fick tidigare. Om du vill skapa en miljövariabel för URL:en använder du följande så att du inte behöver ange den för varje kommando:
export OOZIE_URL=http://HOSTNAMEt:11000/oozieOm du vill skicka jobbet använder du följande kod:
oozie job -config job.xml -submitDet här kommandot läser in jobbinformationen från
job.xmloch skickar den till Oozie, men kör den inte.När kommandot är klart ska det returnera ID:t för jobbet, till exempel
0000005-150622124850154-oozie-oozi-W. Det här ID:t används för att hantera jobbet.Redigera koden nedan för att ersätta
<JOBID>med det ID som returnerades i föregående steg. Om du vill visa jobbets status använder du följande kommando:oozie job -info <JOBID>Detta returnerar information som följande text:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------Det här jobbet har statusen
PREP. Den här statusen anger att jobbet skapades, men inte startades.Redigera koden nedan för att ersätta
<JOBID>med det ID som returnerades tidigare. Använd följande kommando för att starta jobbet:oozie job -start <JOBID>Om du kontrollerar statusen efter det här kommandot är den i ett körningstillstånd och information returneras för åtgärderna i jobbet. Det tar några minuter att slutföra jobbet.
Redigera koden nedan för att ersätta
<serverName>med servernamnet och<sqlLogin>med serverinloggningen. När uppgiften har slutförts kan du kontrollera att data har genererats och exporterats till SQL-databastabellen med hjälp av följande kommando. Ange lösenordet i prompten.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestI prompten
1>anger du följande fråga:SELECT * FROM mobiledata GOInformationen som returneras liknar följande text:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Mer information om Oozie-kommandot finns i kommandoradsverktyget Apache Oozie.
Oozie REST API
Med Oozie REST API kan du skapa egna verktyg som fungerar med Oozie. Följande HDInsight-specifik information om användningen av Oozie REST API:
URI: Du kan komma åt REST-API:et utanför klustret på
https://CLUSTERNAME.azurehdinsight.net/oozie.Autentisering: Använd API:et för klustrets HTTP-konto (administratör) och lösenord för att autentisera. Till exempel:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Mer information om hur du använder Oozie REST API finns i Apache Oozie Web Services API.
Oozie-webbgränssnitt
Oozie-webbgränssnittet ger en webbaserad vy över statusen för Oozie-jobb i klustret. Med webbgränssnittet kan du visa följande information:
- Jobbstatus
- Jobbdefinition
- Konfiguration
- Ett diagram över åtgärderna i jobbet
- Loggar för jobbet
Du kan också visa information om åtgärderna i ett jobb.
Utför följande steg för att komma åt Oozie-webbgränssnittet:
Skapa en SSH-tunnel till HDInsight-klustret. Mer information finns i Använda SSH-tunnlar med HDInsight.
När du har skapat en tunnel öppnar du webbgränssnittet för Ambari i webbläsaren med hjälp av URI
http://headnodehost:8080.Välj Oozie>Quick Links>Oozie Web UI till vänster på sidan.
Oozie-webbgränssnittet visar som standard de arbetsflödesjobb som körs. Om du vill se alla arbetsflödesjobb väljer du Alla jobb.
Om du vill visa mer information om ett jobb väljer du jobbet.
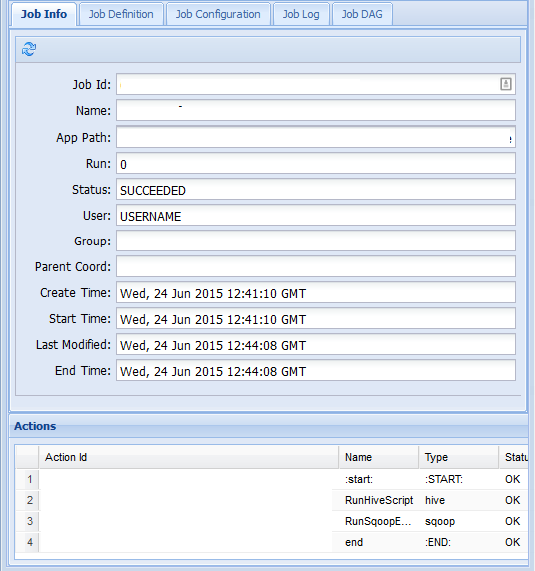
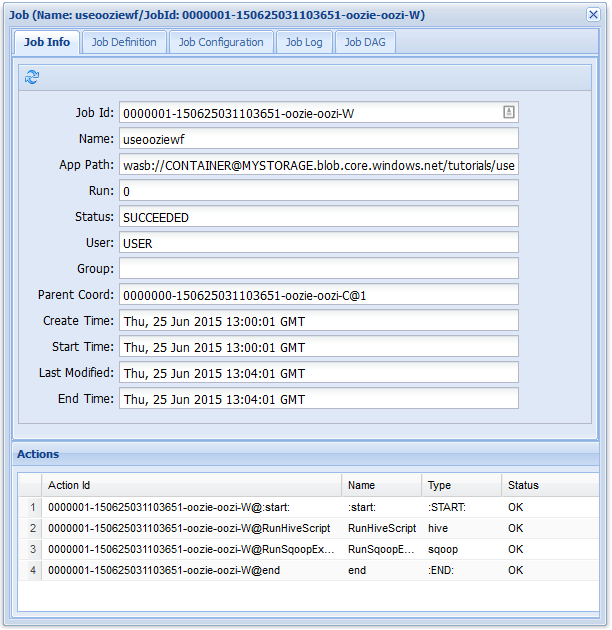
På fliken Jobbinformation kan du se grundläggande jobbinformation och enskilda åtgärder i jobbet. Du kan använda flikarna längst upp för att visa jobbdefinitionen, jobbkonfigurationen, komma åt jobbloggen eller visa ett riktat acykliskt diagram (DAG) för jobbet under Jobb DAG.
Jobblogg: Välj knappen Hämta loggar för att hämta alla loggar för jobbet eller använd fältet
Enter Search Filterför att filtrera loggarna.
Jobb DAG: DAG är en grafisk översikt över de datavägar som tas genom arbetsflödet.
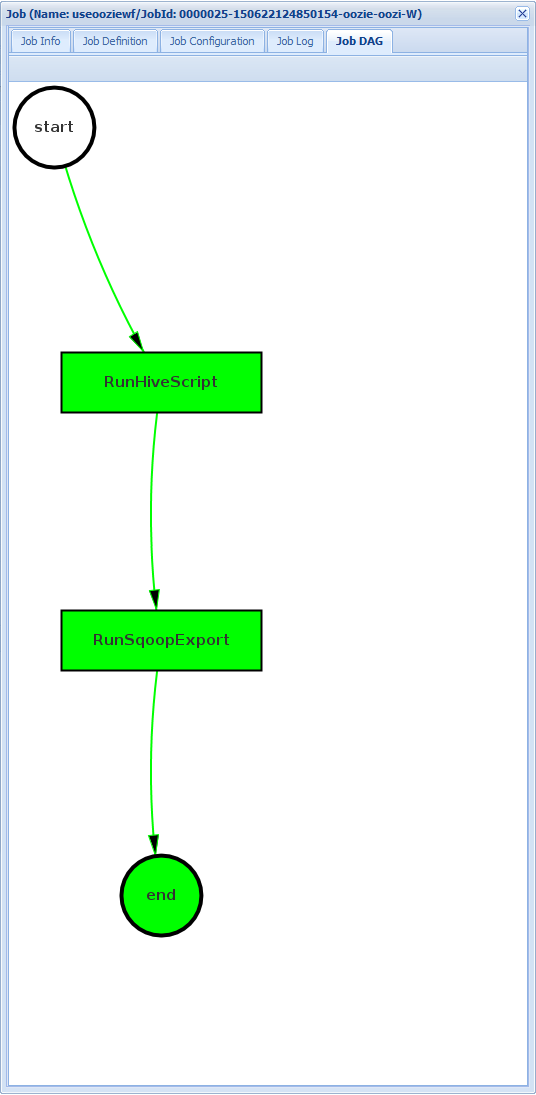
Om du väljer någon av åtgärderna på fliken Jobbinformation visas information om åtgärden. Välj till exempel åtgärden RunSqoopExport .
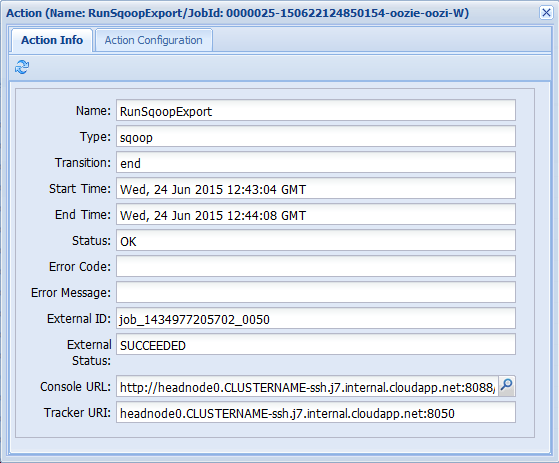
Du kan se information om åtgärden, till exempel en länk till konsolens URL. Använd den här länken om du vill visa jobbspårarinformation för jobbet.
Schemalägga jobb
Du kan använda koordinatorn för att ange start, slut och förekomstfrekvens för jobb. Utför följande steg för att definiera ett schema för arbetsflödet:
Använd följande kommando för att skapa en fil med namnet coordinator.xml:
nano coordinator.xmlAnvänd följande XML som innehåll i filen:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Kommentar
Variablerna
${...}ersätts med värden i jobbdefinitionen vid körning. Variablerna är:${coordFrequency}: Tiden mellan att köra instanser av jobbet.${coordStart}: Starttiden för jobbet.${coordEnd}: Jobbets sluttid.${coordTimezone}: Koordinatorjobben finns i en fast tidszon utan sommartid, vilket vanligtvis representeras av UTC. Den här tidszonen kallas tidszonen för Oozie-bearbetning.${wfPath}: Sökvägen till workflow.xml.
Spara filen genom att välja Ctrl+X, ange Y och sedan Retur.
Om du vill kopiera filen till arbetskatalogen för det här jobbet använder du följande kommando:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlOm du vill ändra
job.xmlfilen som du skapade tidigare använder du följande kommando:nano job.xmlGör följande ändringar:
Om du vill instruera Oozie att köra koordinatorfilen i stället för arbetsflödet ändrar du
<name>oozie.wf.application.path</name>till<name>oozie.coord.application.path</name>.Om du vill ange variabeln
workflowPathsom används av koordinatorn lägger du till följande XML:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>wasbs://mycontainer@mystorageaccount.blob.core.windowsErsätt texten med värdet som används i de andra posterna i job.xml-filen.Om du vill definiera koordinatorns start-, slut- och frekvens lägger du till följande XML:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Dessa värden anger starttiden till 12:00 den 10 maj 2018 och sluttiden till 12 maj 2018. Intervallet för att köra det här jobbet är inställt på dagligen. Frekvensen är i minuter, så 24 timmar x 60 minuter = 1440 minuter. Slutligen är tidszonen inställd på UTC.
Spara filen genom att välja Ctrl+X, ange Y och sedan Retur.
Om du vill skicka och starta jobbet använder du följande kommando:
oozie job -config job.xml -runOm du går till Oozie-webbgränssnittet och väljer fliken Koordinatorjobb visas information som i följande bild:

Posten Nästa materialisering innehåller nästa gång jobbet körs.
Precis som det tidigare arbetsflödesjobbet visar den information om jobbet om du väljer jobbposten i webbgränssnittet:
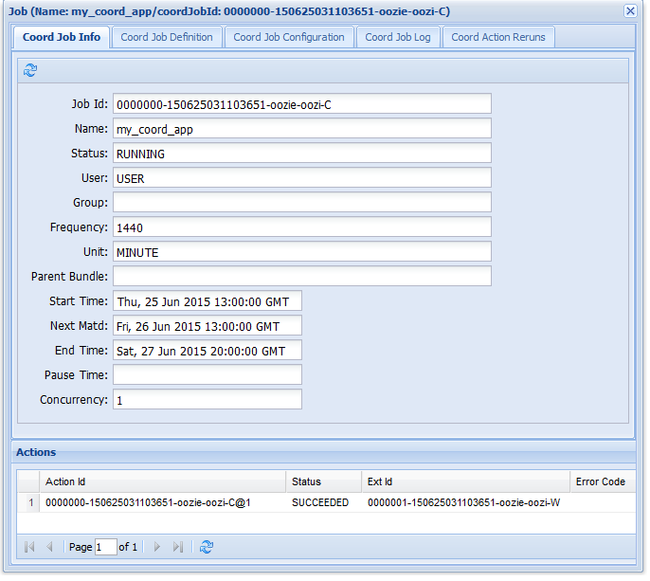
Kommentar
Den här bilden visar bara lyckade körningar av jobbet, inte enskilda åtgärder i det schemalagda arbetsflödet. Om du vill se de enskilda åtgärderna väljer du en av åtgärdsposterna.
Nästa steg
I den här artikeln har du lärt dig hur du definierar ett Oozie-arbetsflöde och hur du kör ett Oozie-jobb. Mer information om hur du arbetar med HDInsight finns i följande artiklar: