Apache Phoenix i Azure HDInsight
Apache Phoenix är ett öppen källkod, massivt parallellt relationsdatabaslager som bygger på Apache HBase. Med Phoenix kan du använda SQL-liknande frågor via HBase. Phoenix använder JDBC-drivrutiner under för att göra det möjligt för användare att skapa, ta bort, ändra SQL-tabeller, index, vyer och sekvenser samt öka rader individuellt och i bulk. Phoenix använder noSQL-intern kompilering i stället för att använda MapReduce för att kompilera frågor, vilket gör det möjligt att skapa program med låg latens ovanpå HBase. Phoenix lägger till medprocessorer för att stödja körning av kod som tillhandahålls av klienten i serverns adressutrymme och kör koden som samlokaliserats med data. Den här metoden minimerar överföring av klient-/serverdata.
Apache Phoenix öppnar stordatafrågor för icke-utvecklare som kan använda en SQL-liknande syntax i stället för programmering. Phoenix är mycket optimerat för HBase, till skillnad från andra verktyg som Apache Hive och Apache Spark SQL. Fördelen för utvecklare är att skriva mycket högpresterande frågor med mycket mindre kod.
När du skickar en SQL-fråga kompilerar Phoenix frågan till HBase-interna anrop och kör genomsökningen (eller planen) parallellt för optimering. Det här abstraktionsskiktet befriar utvecklaren från att skriva MapReduce-jobb, för att i stället fokusera på affärslogik och arbetsflödet för deras program runt Phoenix stordatalagring.
Frågeprestandaoptimering och andra funktioner
Apache Phoenix lägger till flera prestandaförbättringar och funktioner i HBase-frågor.
Sekundära index
HBase har ett enda index som är lexicographically sorterat på den primära radnyckeln. Dessa poster kan bara nås via radnyckeln. Åtkomst till poster via en annan kolumn än radnyckeln kräver genomsökning av alla data när det nödvändiga filtret används. I ett sekundärt index tillåter kolumner eller uttryck som indexeras från en alternativ radnyckel sökningar och intervallgenomsökningar i indexet.
Skapa ett sekundärt index med CREATE INDEX kommandot :
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Den här metoden kan ge en betydande prestandaökning jämfört med körning av enindexerade frågor. Den här typen av sekundärt index är ett täckande index som innehåller alla kolumner som ingår i frågan. Därför krävs inte tabellsökningen och indexet uppfyller hela frågan.
Vyer
Phoenix-vyer är ett sätt att övervinna en HBase-begränsning, där prestanda börjar försämras när du skapar mer än cirka 100 fysiska tabeller. Med Phoenix-vyer kan flera virtuella tabeller dela en underliggande fysisk HBase-tabell.
Att skapa en Phoenix-vy liknar att använda sql-standardsyntax. En skillnad är att du kan definiera kolumner för vyn, förutom de kolumner som ärvs från dess bastabell. Du kan också lägga till nya KeyValue kolumner.
Här är till exempel en fysisk tabell med namnet product_metrics med följande definition:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Definiera en vy över den här tabellen med fler kolumner:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
Om du vill lägga till fler kolumner senare använder du -instruktionen ALTER VIEW .
Hoppa över genomsökning
Hoppa över genomsökning använder en eller flera kolumner i ett sammansatt index för att hitta distinkta värden. Till skillnad från en intervallgenomsökning implementerar skip scan intra-row scanning, vilket ger bättre prestanda. När du söker igenom hoppas det första matchade värdet över tillsammans med indexet tills nästa värde hittas.
Vid en skip-genomsökning används SEEK_NEXT_USING_HINT uppräkning av HBase-filtret. Med hjälp SEEK_NEXT_USING_HINTav håller skip-genomsökningen reda på vilken uppsättning nycklar, eller nyckelintervall, som söks efter i varje kolumn. Hoppa över genomsökningen tar sedan en nyckel som skickades till den under filterutvärderingen och avgör om det är en av kombinationerna. Annars utvärderar skip-genomsökningen den näst högsta nyckeln att hoppa till.
Transaktioner
Medan HBase tillhandahåller transaktioner på radnivå integreras Phoenix med Tephra för att lägga till transaktionsstöd mellan rader och korstabeller med fullständig ACID-semantik .
Precis som med traditionella SQL-transaktioner kan transaktioner som tillhandahålls via Phoenix-transaktionshanteraren se till att en atomisk dataenhet har uppdaterats och återställa transaktionen om den uppdaterade åtgärden misslyckas i en transaktionsaktiverad tabell.
Information om hur du aktiverar Phoenix-transaktioner finns i dokumentationen om Apache Phoenix-transaktioner.
Om du vill skapa en ny tabell med transaktioner aktiverade anger du TRANSACTIONAL egenskapen till true i en CREATE instruktion:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
Om du vill ändra en befintlig tabell så att den är transaktionell använder du samma egenskap i en ALTER -instruktion:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Kommentar
Du kan inte växla tillbaka en transaktionstabell till att vara icke-transaktionell.
Saltade tabeller
Regionserver hotspotting kan inträffa när du skriver poster med sekventiella nycklar till HBase. Även om du kan ha flera regionservrar i klustret sker alla skrivningar på bara en. Den här koncentrationen skapar hotspotting-problemet där, i stället för att din skrivarbetsbelastning distribueras över alla tillgängliga regionservrar, bara en hanterar belastningen. Eftersom varje region har en fördefinierad maximal storlek delas den upp i två små regioner när en region når den storleksgränsen. När det händer tar en av dessa nya regioner alla nya poster och blir den nya hotspoten.
För att minimera det här problemet och uppnå bättre prestanda, delas tabeller i förväg så att alla regionservrar används på samma sätt. Phoenix tillhandahåller saltade tabeller och lägger transparent till saltningsbytet till radnyckeln för en viss tabell. Tabellen är i förväg uppdelad på saltbytegränserna för att säkerställa lika belastningsfördelning mellan regionservrar under den inledande fasen av tabellen. Den här metoden distribuerar skrivarbetsbelastningen över alla tillgängliga regionservrar, vilket förbättrar skriv- och läsprestanda. Om du vill salta en tabell anger du SALT_BUCKETS tabellegenskapen när tabellen skapas:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Aktivera och finjustera Phoenix med Apache Ambari
Ett HDInsight HBase-kluster innehåller Ambari-användargränssnittet för att göra konfigurationsändringar.
Om du vill aktivera eller inaktivera Phoenix och kontrollera Phoenix timeout-inställningar för frågor loggar du in på Ambari Web UI (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) med dina Hadoop-användarautentiseringsuppgifter.Välj HBase i listan över tjänster på den vänstra menyn och välj sedan fliken Konfigurationer .
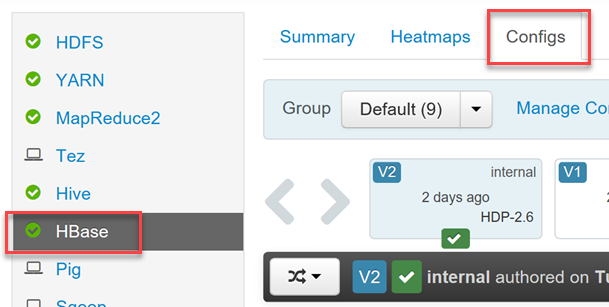
Leta upp avsnittet Phoenix SQL-konfiguration för att aktivera eller inaktivera Phoenix och ange tidsgränsen för frågan.