Hantera loggar för ett HDInsight-kluster
HDInsight-klustret skapar olika loggfiler. Till exempel skapar Apache Hadoop och relaterade tjänster, till exempel Apache Spark, detaljerade jobbkörningsloggar. Loggfilshantering är en del av att underhålla ett felfritt HDInsight-kluster. Det kan också finnas regelkrav för loggarkivering. På grund av antalet och storleken på loggfiler hjälper optimering av logglagring och arkivering till kostnadshantering för tjänsten.
Att hantera HDInsight-klusterloggar omfattar att behålla information om alla aspekter av klustermiljön. Den här informationen omfattar alla associerade Azure Service-loggar, klusterkonfiguration, jobbkörningsinformation, eventuella feltillstånd och andra data efter behov.
Vanliga steg i HDInsight-logghantering är:
- Steg 1: Fastställa kvarhållningsprinciper för loggar
- Steg 2: Hantera konfigurationsloggar för klustertjänstversioner
- Steg 3: Hantera loggfiler för klusterjobbkörning
- Steg 4: Prognostisera lagringsstorlekar och kostnader för loggvolymer
- Steg 5: Fastställa principer och processer för loggarkiv
Steg 1: Fastställa kvarhållningsprinciper för loggar
Det första steget i att skapa en strategi för hantering av HDInsight-klusterloggar är att samla in information om affärsscenarier och lagringskrav för jobbkörningshistorik.
Klusterinformation
Följande klusterinformation är användbar för att samla in information i din logghanteringsstrategi. Samla in den här informationen från alla HDInsight-kluster som du har skapat i ett visst Azure-konto.
- Klusternamn
- Klusterregion och Azure-tillgänglighetszon
- Klustertillstånd, inklusive information om den senaste tillståndsändringen
- Typ och antal HDInsight-instanser som angetts för huvud-, kärn- och aktivitetsnoderna
Du kan få det mesta av den här informationen på den översta nivån med hjälp av Azure Portal. Du kan också använda Azure CLI för att få information om dina HDInsight-kluster:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Du kan också använda PowerShell för att visa den här informationen. Mer information finns i Apache Hantera Hadoop-kluster i HDInsight med hjälp av Azure PowerShell.
Förstå de arbetsbelastningar som körs i dina kluster
Det är viktigt att förstå vilka arbetsbelastningstyper som körs på dina HDInsight-kluster för att utforma lämpliga loggningsstrategier för varje typ.
- Är arbetsbelastningarna experimentella (till exempel utveckling eller test) eller produktionskvalitet?
- Hur ofta körs arbetsbelastningar av produktionskvalitet normalt?
- Är någon av arbetsbelastningarna resursintensiv och/eller tidskrävande?
- Använder någon av arbetsbelastningarna en komplex uppsättning Hadoop-tjänster för vilka flera typer av loggar skapas?
- Har någon av arbetsbelastningarna tillhörande krav på regelkörningsradage?
Exempel på mönster och metoder för loggkvarhållning
Överväg att underhålla spårning av data härkomst genom att lägga till en identifierare i varje loggpost eller via andra tekniker. På så sätt kan du spåra den ursprungliga datakällan och åtgärden och följa data genom varje steg för att förstå dess konsekvens och giltighet.
Fundera på hur du kan samla in loggar från klustret eller från mer än ett kluster och sortera dem i syfte som granskning, övervakning, planering och aviseringar. Du kan använda en anpassad lösning för att komma åt och ladda ned loggfilerna regelbundet och kombinera och analysera dem för att tillhandahålla en instrumentpanelsvisning. Du kan också lägga till andra funktioner för aviseringar för säkerhets- eller felidentifiering. Du kan skapa dessa verktyg med hjälp av PowerShell, HDInsight SDK:er eller kod som har åtkomst till den klassiska Azure-distributionsmodellen.
Fundera på om en övervakningslösning eller tjänst skulle vara en användbar fördel. Microsoft System Center tillhandahåller ett HDInsight-hanteringspaket. Du kan också använda verktyg från tredje part som Apache Chukwa och Ganglia för att samla in och centralisera loggar. Många företag erbjuder tjänster för att övervaka Hadoop-baserade stordatalösningar, till exempel:
Centerity, Compuware APM, Sematext SPM och Zettaset Orchestrator.
Steg 2: Hantera klustertjänstversioner och visa loggar
Ett typiskt HDInsight-kluster använder flera tjänster och programvarupaket med öppen källkod (till exempel Apache HBase, Apache Spark och så vidare). För vissa arbetsbelastningar, till exempel bioinformatik, kan du behöva behålla logghistoriken för tjänstkonfiguration utöver jobbkörningsloggar.
Visa konfigurationsinställningar för kluster med Ambari-användargränssnittet
Apache Ambari förenklar hantering, konfiguration och övervakning av ett HDInsight-kluster genom att tillhandahålla ett webbgränssnitt och ett REST-API. Ambari ingår i Linux-baserade HDInsight-kluster. Välj fönstret Klusterinstrumentpanel på sidan Azure Portal HDInsight för att öppna länksidan För klusterinstrumentpaneler. Välj sedan instrumentpanelen för HDInsight-klustret för att öppna Ambari-användargränssnittet. Du uppmanas att ange dina inloggningsuppgifter för klustret.
Om du vill öppna en lista över tjänstvyer väljer du fönstret Ambari-vyer på sidan Azure Portal för HDInsight. Den här listan varierar beroende på vilka bibliotek du har installerat. Du kan till exempel se YARN Queue Manager, Hive View och Tez View. Välj valfri tjänstlänk för att se konfigurations- och tjänstinformation. Sidan Ambari UI Stack och Version innehåller information om klustertjänsternas konfigurations- och tjänstversionshistorik. Om du vill navigera till det här avsnittet i Ambari-användargränssnittet väljer du menyn Admin och sedan Stacks and Versions (Staplar och versioner). Välj fliken Versioner för att se information om tjänstversion.
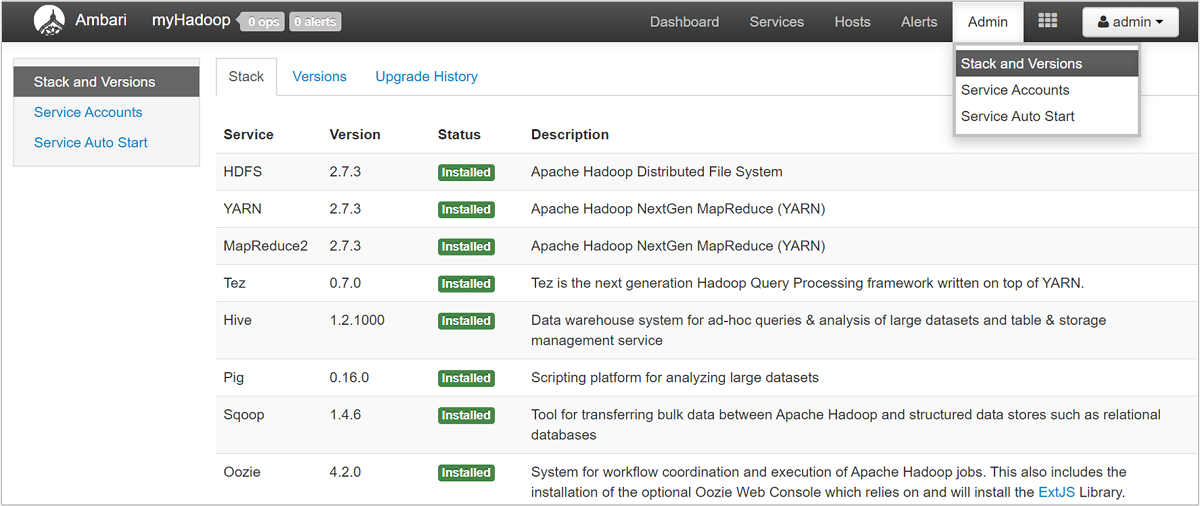
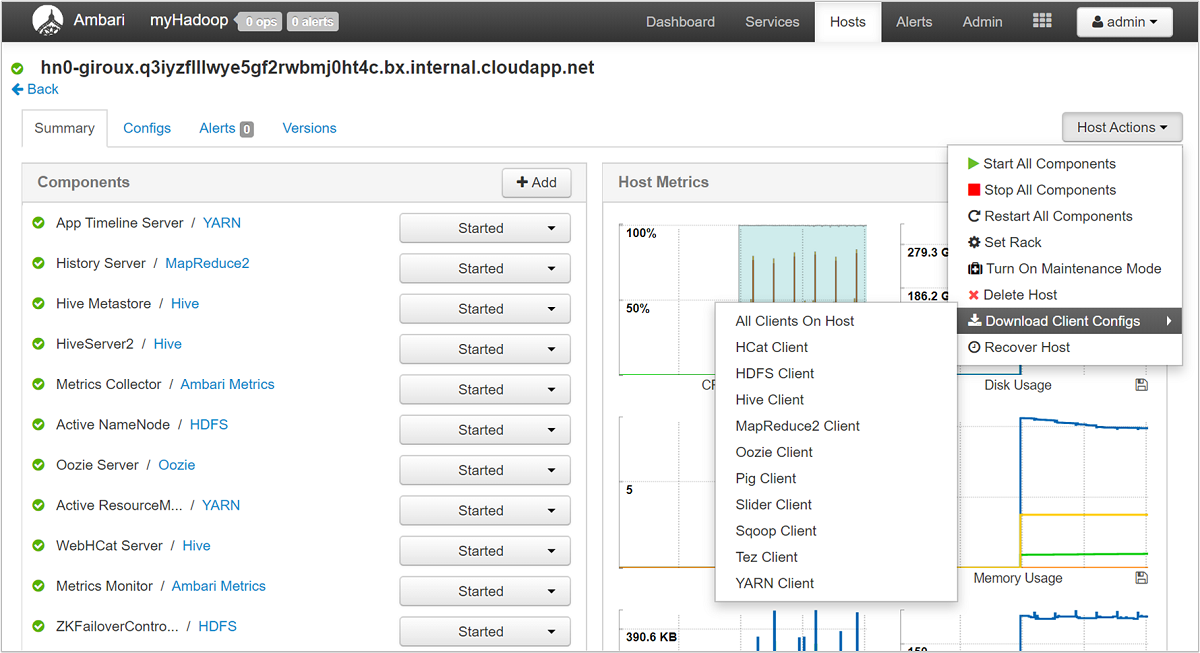
Med Ambari-användargränssnittet kan du ladda ned konfigurationen för alla (eller alla) tjänster som körs på en viss värd (eller nod) i klustret. Välj menyn Värdar och sedan länken för värden av intresse. På den värdens sida väljer du knappen Värdåtgärder och sedan Ladda ned klientkonfigurationer.
Visa skriptåtgärdsloggarna
HDInsight-skriptåtgärder kör skript i ett kluster, antingen manuellt eller när de anges. Skriptåtgärder kan till exempel användas för att installera annan programvara i klustret eller för att ändra konfigurationsinställningarna från standardvärdena. Skriptåtgärdsloggar kan ge insikter om fel som inträffade under konfigurationen av klustret och även ändringar i konfigurationsinställningarna som kan påverka klusterprestanda och tillgänglighet. Om du vill se status för en skriptåtgärd väljer du knappen ops i ditt Ambari-användargränssnitt eller öppnar statusloggarna i standardlagringskontot . Lagringsloggarna är tillgängliga på /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Visa statusloggar för Ambari-aviseringar
Apache Ambari skriver aviseringsstatusändringar till ambari-alerts.log. Den fullständiga sökvägen är /var/log/ambari-server/ambari-alerts.log. Om du vill aktivera felsökning för loggen ändrar du en egenskap i /etc/ambari-server/conf/log4j.properties. Ändra och anger sedan under # Log alert state changes från:
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Steg 3: Hantera loggfilerna för klusterjobbkörning
Nästa steg är att granska loggfilerna för jobbkörning för de olika tjänsterna. Tjänsterna kan omfatta Apache HBase, Apache Spark och många andra. Ett Hadoop-kluster skapar ett stort antal utförliga loggar, så det kan vara tidskrävande att avgöra vilka loggar som är användbara (och vilka som inte är det). Det är viktigt att förstå loggningssystemet för riktad hantering av loggfiler. Följande bild är en exempelloggfil.
Få åtkomst till Hadoop-loggfilerna
HDInsight lagrar sina loggfiler både i klusterfilsystemet och i Azure Storage. Du kan undersöka loggfiler i klustret genom att öppna en SSH-anslutning till klustret och bläddra i filsystemet, eller genom att använda Hadoop YARN-statusportalen på fjärrhuvudnodservern. Du kan undersöka loggfilerna i Azure Storage med något av de verktyg som kan komma åt och ladda ned data från Azure Storage. Exempel är AzCopy, CloudXplorer och Visual Studio Server Explorer. Du kan också använda PowerShell och Azure Storage-klientbiblioteken eller Azure .NET SDK:er för att komma åt data i Azure Blob Storage.
Hadoop kör jobbens arbete som uppgiftsförsök på olika noder i klustret. HDInsight kan initiera spekulativa uppgiftsförsök och avsluta andra uppgiftsförsök som inte slutförs först. Detta genererar betydande aktivitet som loggas till kontrollanten, stderr- och syslog-loggfilerna direkt. Dessutom körs flera aktivitetsförsök samtidigt, men en loggfil kan bara visa resultat linjärt.
HDInsight-loggar som skrivits till Azure Blob Storage
HDInsight-kluster är konfigurerade för att skriva aktivitetsloggar till ett Azure Blob Storage-konto för alla jobb som skickas med hjälp av Azure PowerShell-cmdletar eller .NET-jobböverförings-API:er. Om du skickar jobb via SSH till klustret lagras informationen om körningsloggning i Azure-tabellerna enligt beskrivningen i föregående avsnitt.
Förutom de kärnloggfiler som genereras av HDInsight genererar installerade tjänster som YARN även loggfiler för jobbkörning. Antalet och typen av loggfiler beror på vilka tjänster som är installerade. Vanliga tjänster är Apache HBase, Apache Spark och så vidare. Undersök jobbloggens körningsfiler för varje tjänst för att förstå de övergripande loggningsfilerna som är tillgängliga i klustret. Varje tjänst har sina egna unika metoder för loggning och platser för lagring av loggfiler. Som ett exempel beskrivs information för att komma åt de vanligaste tjänstloggfilerna (från YARN) i följande avsnitt.
HDInsight-loggar som genereras av YARN
YARN aggregerar loggar över alla containrar på en arbetsnod och lagrar loggarna som en aggregerad loggfil per arbetsnod. Loggen lagras i standardfilsystemet när ett program har slutförts. Ditt program kan använda hundratals eller tusentals containrar, men loggar för alla containrar som körs på en enda arbetsnod aggregeras alltid till en enda fil. Det finns bara en logg per arbetsnod som används av ditt program. Loggaggregering är aktiverat som standard för HDInsight-kluster version 3.0 och senare. Aggregerade loggar finns på standardlagringsplatsen för klustret.
/app-logs/<user>/logs/<applicationId>
De aggregerade loggarna kan inte läsas direkt eftersom de skrivs i ett TFile binärt format som indexeras av containern. Använd YARN-loggarna ResourceManager eller CLI-verktygen för att visa loggarna som oformaterad text för program eller containrar av intresse.
YARN CLI-verktyg
Om du vill använda YARN CLI-verktygen måste du först ansluta till HDInsight-klustret med hjälp av SSH. <applicationId>Ange informationen , <user-who-started-the-application>, <containerId>och <worker-node-address> när du kör dessa kommandon. Du kan visa loggarna som oformaterad text med något av följande kommandon:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
YARN Resource Manager-användargränssnitt
YARN Resource Manager-användargränssnittet körs på klusterhuvudnoden och nås via Ambari-webbgränssnittet. Använd följande steg för att visa YARN-loggarna:
- I en webbläsare navigerar du till
https://CLUSTERNAME.azurehdinsight.net. Ersätt KLUSTERNAMN med namnet på ditt HDInsight-kluster. - Välj YARN i listan över tjänster till vänster.
- I listrutan Snabblänkar väljer du en av klusterhuvudnoderna och väljer sedan Resource Manager-loggar. Du visas med en lista med länkar till YARN-loggar.
Steg 4: Prognostisera lagringsstorlekar och kostnader för loggvolymer
När du har slutfört föregående steg har du en förståelse för vilka typer och volymer av loggfiler som dina HDInsight-kluster producerar.
Analysera sedan mängden loggdata på lagringsplatser för nyckelloggar under en viss tidsperiod. Du kan till exempel analysera volym och tillväxt under 30–60–90 dagar. Registrera den här informationen i ett kalkylblad eller använd andra verktyg som Visual Studio, Azure Storage Explorer eller Power Query för Excel. ```
Nu har du tillräckligt med information för att skapa en logghanteringsstrategi för nyckelloggarna. Använd ditt kalkylblad (eller valfritt verktyg) för att prognostisera både loggstorlekstillväxt och logglagring av Azure-tjänstkostnader framöver. Överväg även eventuella krav på loggkvarhållning för den uppsättning loggar som du undersöker. Nu kan du återställa framtida logglagringskostnader efter att du har fastställt vilka loggfiler som kan tas bort (om några) och vilka loggar som ska behållas och arkiveras till billigare Azure Storage.
Steg 5: Fastställa principer och processer för loggarkiv
När du har fastställt vilka loggfiler som kan tas bort kan du justera loggningsparametrarna på många Hadoop-tjänster för att automatiskt ta bort loggfiler efter en angiven tidsperiod.
För vissa loggfiler kan du använda en metod för arkivering av loggfiler med lägre priser. För Azure Resource Manager-aktivitetsloggar kan du utforska den här metoden med hjälp av Azure Portal. Konfigurera arkivering av Resource Manager-loggarna genom att välja länken Aktivitetslogg i Azure Portal för DIN HDInsight-instans. Längst upp på söksidan för aktivitetsloggen väljer du menyalternativet Exportera för att öppna fönstret Exportera aktivitetslogg . Fyll i prenumerationen, regionen, om du vill exportera till ett lagringskonto och hur många dagar loggarna ska behållas. I samma fönster kan du också ange om du vill exportera till en händelsehubb.
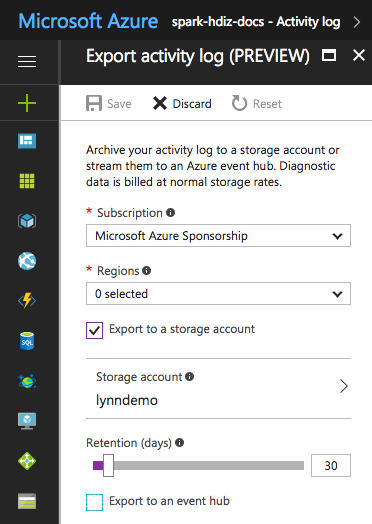
Du kan också skriva loggarkivering med PowerShell.
Åtkomst till Azure Storage-mått
Azure Storage kan konfigureras för att logga lagringsåtgärder och åtkomst. Du kan använda dessa detaljerade loggar för kapacitetsövervakning och planering samt för granskning av begäranden till lagring. Den loggade informationen innehåller svarstidsinformation så att du kan övervaka och finjustera prestanda för dina lösningar. Du kan använda .NET SDK för Hadoop för att undersöka loggfilerna som genererats för Azure Storage som innehåller data för ett HDInsight-kluster.
Kontrollera storleken och antalet säkerhetskopieringsindex för gamla loggfiler
Om du vill styra storleken och antalet kvarhållna loggfiler anger du följande egenskaper för RollingFileAppender:
maxFileSizeär den kritiska storleken på filen, som filen har rullats. Standardvärdet är 10 MB.maxBackupIndexanger antalet säkerhetskopierade filer som ska skapas, standard 1.
Andra logghanteringstekniker
För att undvika att diskutrymmet tar slut kan du använda vissa os-verktyg som logrotate för att hantera för att hantera loggfiler. Du kan konfigurera logrotate att köras dagligen, komprimera loggfiler och ta bort gamla. Din metod beror på dina krav, till exempel hur länge loggfilerna ska behållas på lokala noder.
Du kan också kontrollera om felsökningsloggning är aktiverat för en eller flera tjänster, vilket avsevärt ökar utdataloggens storlek.
Om du vill samla in loggarna från alla noder till en central plats kan du skapa ett dataflöde, till exempel att mata in alla loggposter i Solr.