Använda Spark- och Hive-verktyg för Visual Studio Code
Lär dig hur du använder Apache Spark och Hive Tools för Visual Studio Code. Använd verktygen för att skapa och skicka Apache Hive-batchjobb, interaktiva Hive-frågor och PySpark-skript för Apache Spark. Först ska vi beskriva hur du installerar Spark & Hive Tools i Visual Studio Code. Sedan går vi igenom hur du skickar jobb till Spark & Hive Tools.
Spark- och Hive-verktyg kan installeras på plattformar som stöds av Visual Studio Code. Observera följande krav för olika plattformar.
Förutsättningar
Följande objekt krävs för att slutföra stegen i den här artikeln:
- Ett Azure HDInsight-kluster. Information om hur du skapar ett kluster finns i Kom igång med HDInsight. Eller använd ett Spark- och Hive-kluster som stöder en Apache Livy-slutpunkt.
- Visual Studio Code.
- Mono. Mono krävs endast för Linux och macOS.
- En interaktiv PySpark-miljö för Visual Studio Code.
- En lokal katalog. Den här artikeln använder
C:\HD\HDexample.
Installera Spark- och Hive-verktyg
När du har uppfyllt kraven kan du installera Spark & Hive Tools för Visual Studio Code genom att följa dessa steg:
Öppna Visual Studio Code.
Gå till Visa>tillägg från menyraden.
I sökrutan anger du Spark & Hive.
Välj Spark & Hive Tools i sökresultaten och välj sedan Installera:
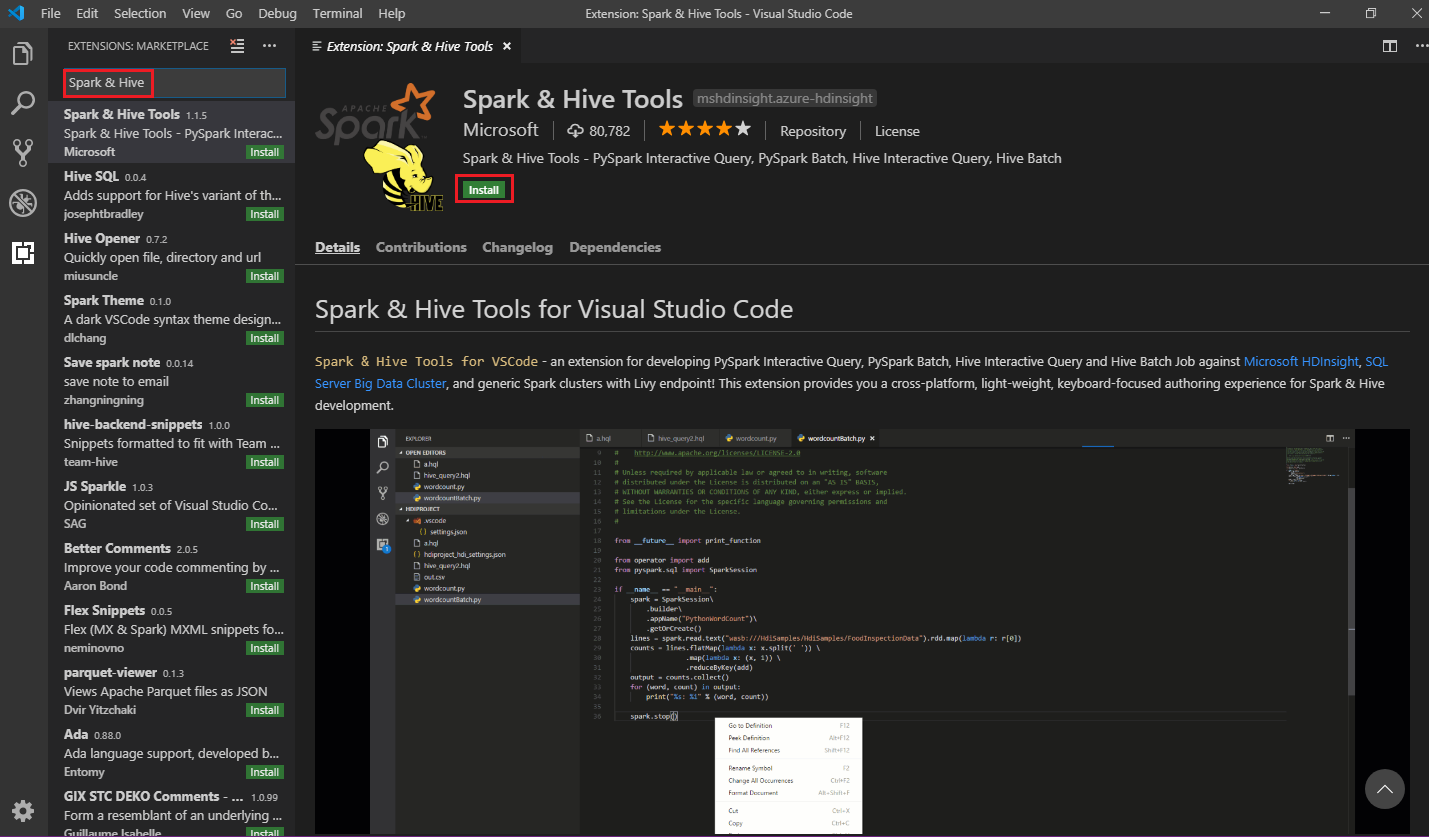
Välj Ladda om när det behövs.
Öppna en arbetsmapp
Så här öppnar du en arbetsmapp och skapar en fil i Visual Studio Code:
Gå till Öppna mapp>i menyraden och>
C:\HD\HDexamplevälj sedan knappen Välj mapp. Mappen visas i Utforskarvyn till vänster.I Utforskarvyn
HDexampleväljer du mappen och väljer sedan ikonen Ny fil bredvid arbetsmappen: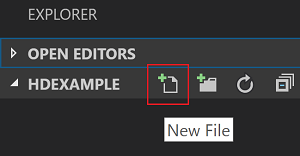
Namnge den nya filen med filtillägget
.hql(Hive-frågor) eller.py(Spark-skript). I det här exemplet används HelloWorld.hql.
Ange Azure-miljön
För en nationell molnanvändare följer du de här stegen för att först ange Azure-miljön och använder sedan kommandot Azure: Sign In för att logga in på Azure:
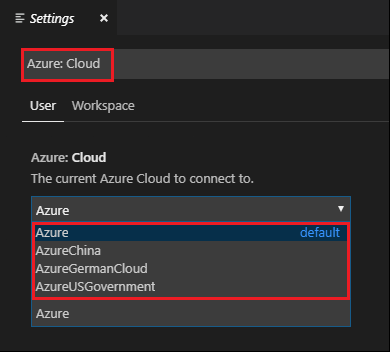
Gå till Inställningar för filinställningar>>.
Sök efter följande sträng: Azure: Cloud.
Välj det nationella molnet i listan:
Ansluta till ett Azure-konto
Innan du kan skicka skript till dina kluster från Visual Studio Code kan användaren antingen logga in på Azure-prenumerationen eller länka ett HDInsight-kluster. Använd Ambari-användarnamnet/lösenordet eller domänanslutna autentiseringsuppgifter för ESP-klustret för att ansluta till ditt HDInsight-kluster. Följ dessa steg för att ansluta till Azure:
Från menyraden går du till Visa>kommandopalett... och anger Azure: Logga in:
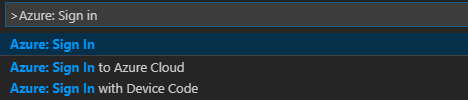
Följ inloggningsanvisningarna för att logga in på Azure. När du är ansluten visas ditt Azure-kontonamn i statusfältet längst ned i Visual Studio Code-fönstret.
Länka ett kluster
Länk: Azure HDInsight
Du kan länka ett normalt kluster med hjälp av ett Apache Ambari-hanterat användarnamn, eller så kan du länka ett Enterprise Security Pack-skyddat Hadoop-kluster med hjälp av ett domänanvändarnamn (till exempel: user1@contoso.com).
Från menyraden går du till Visa>kommandopalett... och anger Spark/Hive: Länka ett kluster.

Välj den länkade klustertypen Azure HDInsight.
Ange URL:en för HDInsight-klustret.
Ange ditt Ambari-användarnamn; standardinställningen är admin.
Ange ditt Ambari-lösenord.
Välj klustertyp.
Ange visningsnamnet för klustret (valfritt).
Granska utdatavyn för verifiering.
Kommentar
Det länkade användarnamnet och lösenordet används om klustret både loggade in på Azure-prenumerationen och länkade ett kluster.
Länk: Generisk Livy-slutpunkt
Från menyraden går du till Visa>kommandopalett... och anger Spark/Hive: Länka ett kluster.
Välj den länkade klustertypen Generisk Livy-slutpunkt.
Ange den generiska Livy-slutpunkten. Till exempel: http://10.172.41.42:18080.
Välj auktoriseringstyp Grundläggande eller Ingen. Om du väljer Grundläggande:
Ange ditt Ambari-användarnamn; standardinställningen är admin.
Ange ditt Ambari-lösenord.
Granska utdatavyn för verifiering.
Lista kluster
Från menyraden går du till Visa>kommandopalett... och anger Spark/Hive: Listkluster.
Välj den prenumeration som du vill använda.
Granska utdatavyn. Den här vyn visar ditt länkade kluster (eller kluster) och alla kluster under din Azure-prenumeration:
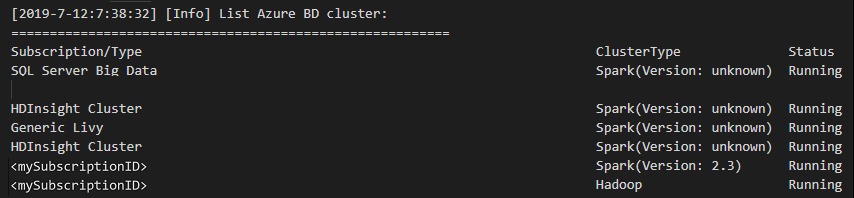
Ange standardklustret
Öppna mappen som diskuterades tidigare om den
HDexamplestängdes.Välj filen HelloWorld.hql som skapades tidigare. Den öppnas i skriptredigeraren.
Högerklicka på skriptredigeraren och välj sedan Spark/Hive: Ange standardkluster.
Anslut till ditt Azure-konto eller länka ett kluster om du inte har gjort det ännu.
Välj ett kluster som standardkluster för den aktuella skriptfilen. Verktygen uppdaterar automatiskt . VSCode\settings.json konfigurationsfil:
Skicka interaktiva Hive-frågor och Hive-batchskript
Med Spark & Hive Tools för Visual Studio Code kan du skicka interaktiva Hive-frågor och Hive-batchskript till dina kluster.
Öppna mappen som diskuterades tidigare om den
HDexamplestängdes.Välj filen HelloWorld.hql som skapades tidigare. Den öppnas i skriptredigeraren.
Kopiera och klistra in följande kod i Hive-filen och spara den sedan:
SELECT * FROM hivesampletable;Anslut till ditt Azure-konto eller länka ett kluster om du inte har gjort det ännu.
Högerklicka på skriptredigeraren och välj Hive: Interaktiv för att skicka frågan eller använd kortkommandot Ctrl+Alt+I. Välj Hive: Batch för att skicka skriptet eller använd kortkommandot Ctrl+Alt+H.
Om du inte har angett något standardkluster väljer du ett kluster. Med verktygen kan du också skicka ett kodblock i stället för hela skriptfilen med hjälp av snabbmenyn. Efter en liten stund visas frågeresultatet på en ny flik:
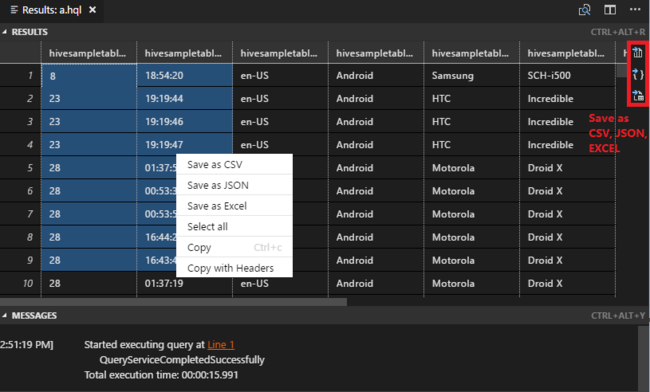
RESULTATpanel : Du kan spara hela resultatet som en CSV-, JSON- eller Excel-fil till en lokal sökväg eller bara välja flera rader.
PANELEN MEDDELANDEN : När du väljer ett radnummer går det till den första raden i skriptet som körs.
Skicka interaktiva PySpark-frågor
Krav för interaktiv Pyspark
Observera här att Jupyter-tilläggsversionen (ms-jupyter): v2022.1.1001614873 och Python-tilläggsversionen (ms-python): v2021.12.1559732655, Python 3.6.x och 3.7.x krävs för interaktiva HDInsight PySpark-frågor.
Användare kan utföra PySpark interaktivt på följande sätt.
Använda det interaktiva PySpark-kommandot i PY-filen
Följ dessa steg med hjälp av det interaktiva PySpark-kommandot för att skicka frågorna:
Öppna mappen som diskuterades tidigare om den
HDexamplestängdes.Skapa en ny HelloWorld.py fil genom att följa de tidigare stegen.
Kopiera och klistra in följande kod i skriptfilen:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])Uppmaningen att installera PySpark/Synapse Pyspark-kerneln visas i fönstrets nedre högra hörn. Du kan klicka på knappen Installera för att fortsätta med PySpark/Synapse Pyspark-installationerna eller klicka på knappen Hoppa över för att hoppa över det här steget.
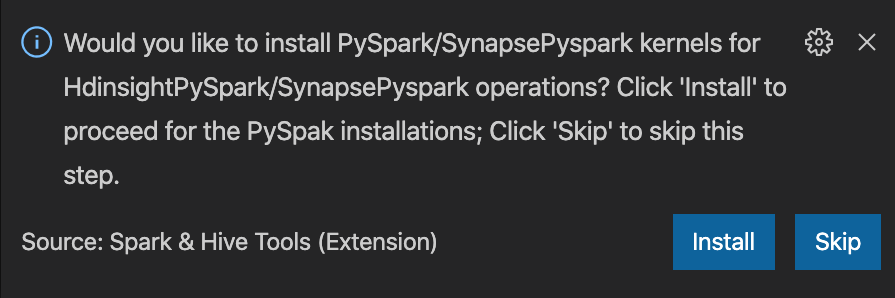
Om du behöver installera det senare kan du gå till Inställningar för filinställningar>>och avmarkera HDInsight: Aktivera Hoppa över Pyspark-installation i inställningarna.
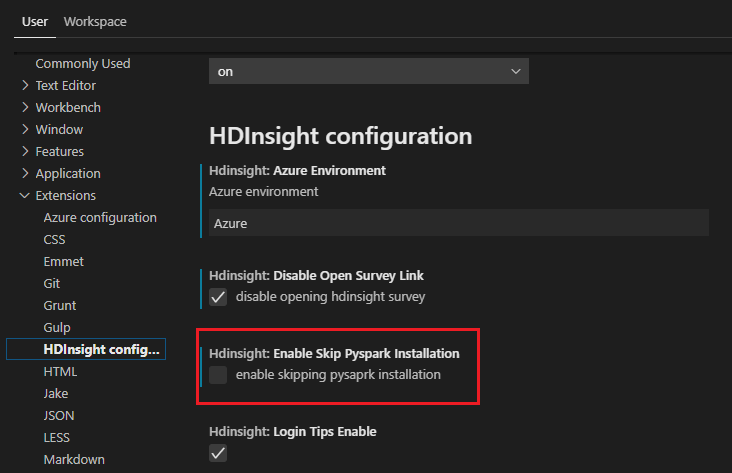
Om installationen lyckas i steg 4 visas meddelanderutan "PySpark har installerats" i det nedre högra hörnet av fönstret. Klicka på knappen Läs in igen för att läsa in fönstret igen.
I menyraden går du till Visa>kommandopalett... eller använder kortkommandot Skift + Ctrl + P och anger Python: Välj tolk för att starta Jupyter Server.

Välj Python-alternativet nedan.

Från menyraden går du till Visa>kommandopalett... eller använder kortkommandot Skift + Ctrl + P och anger Developer: Reload Window (Utvecklare: Läs in fönstret igen).

Anslut till ditt Azure-konto eller länka ett kluster om du inte har gjort det ännu.
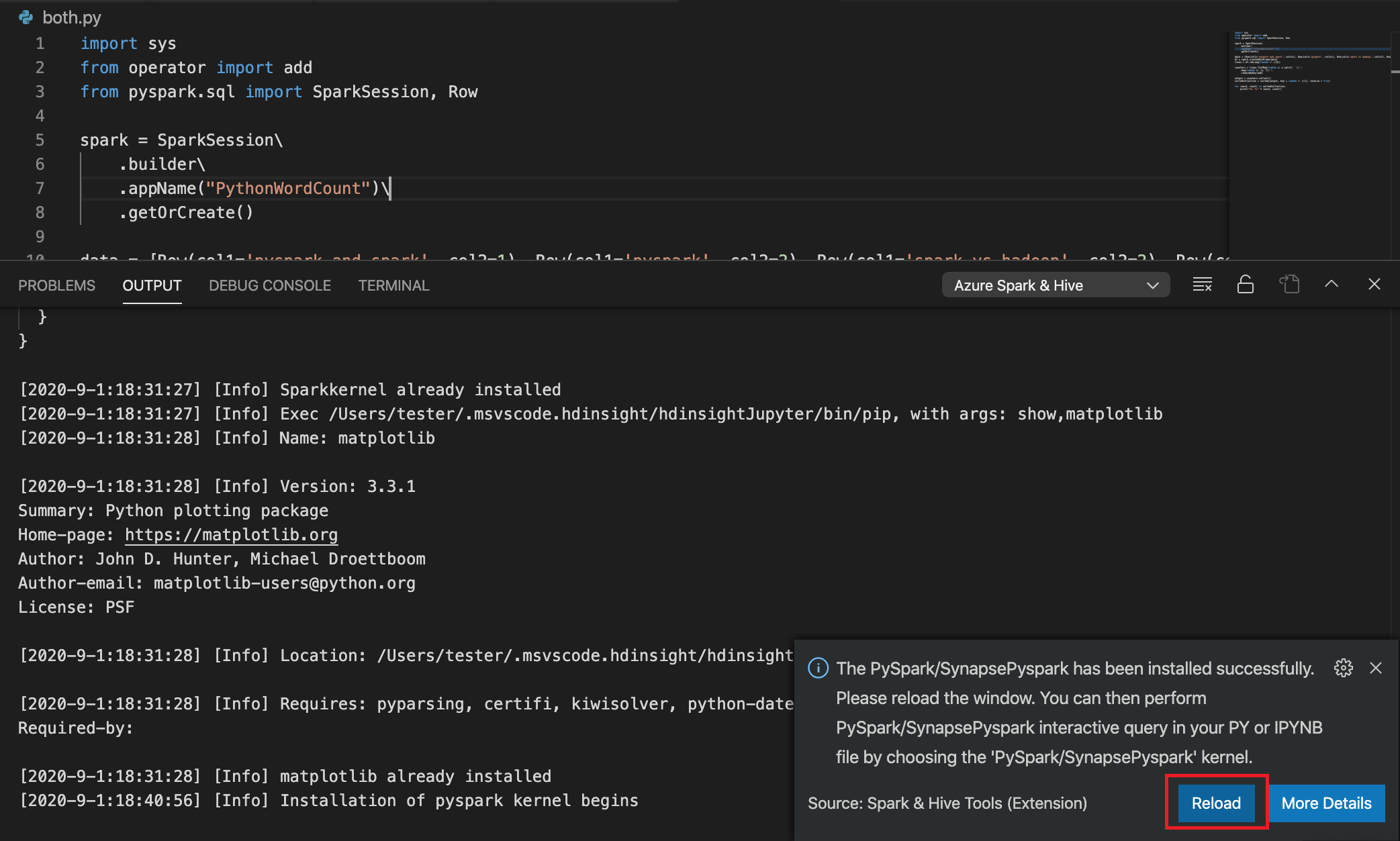
Markera all kod, högerklicka på skriptredigeraren och välj Spark: PySpark Interactive/Synapse: Pyspark Interactive för att skicka frågan.
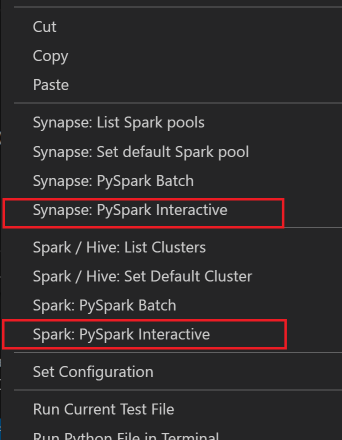
Välj klustret om du inte har angett något standardkluster. Efter en liten stund visas de interaktiva Python-resultaten på en ny flik. Klicka på PySpark om du vill växla kerneln till PySpark/Synapse Pyspark så körs koden. Om du vill växla till Synapse Pyspark-kerneln rekommenderar vi att du inaktiverar automatiska inställningar i Azure Portal. Annars kan det ta lång tid att aktivera klustret och ställa in synapse-kerneln för första gången. Om Verktygen också låter dig skicka ett kodblock i stället för hela skriptfilen med hjälp av snabbmenyn:
Ange %%info och tryck sedan på Skift+Retur för att visa jobbinformationen (valfritt):
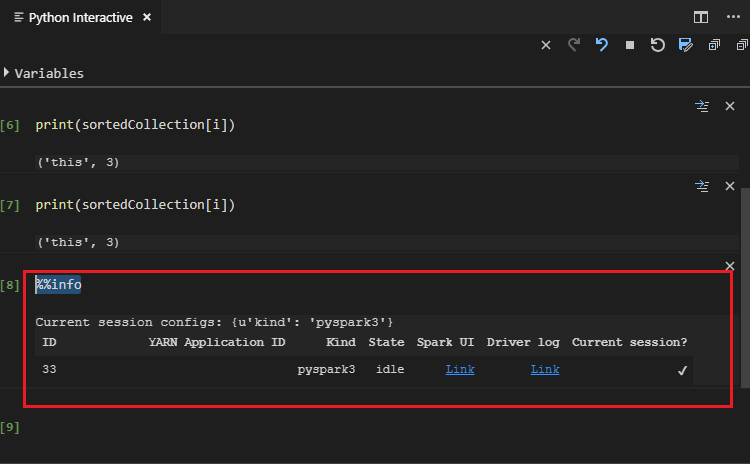
Verktyget stöder även Spark SQL-frågan:
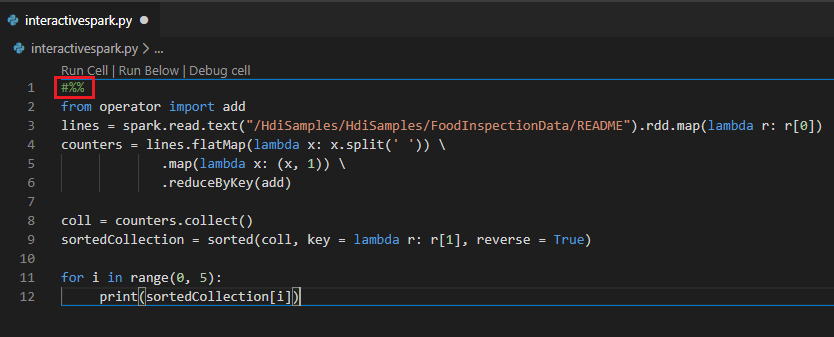
Utföra en interaktiv fråga i PY-filen med hjälp av en #%%-kommentar
Lägg till #%% före Py-koden för att hämta notebook-upplevelsen.
Klicka på Kör cell. Efter en liten stund visas de interaktiva Python-resultaten på en ny flik. Klicka på PySpark för att växla kerneln till PySpark/Synapse PySpark och klicka sedan på Kör cell igen så körs koden.
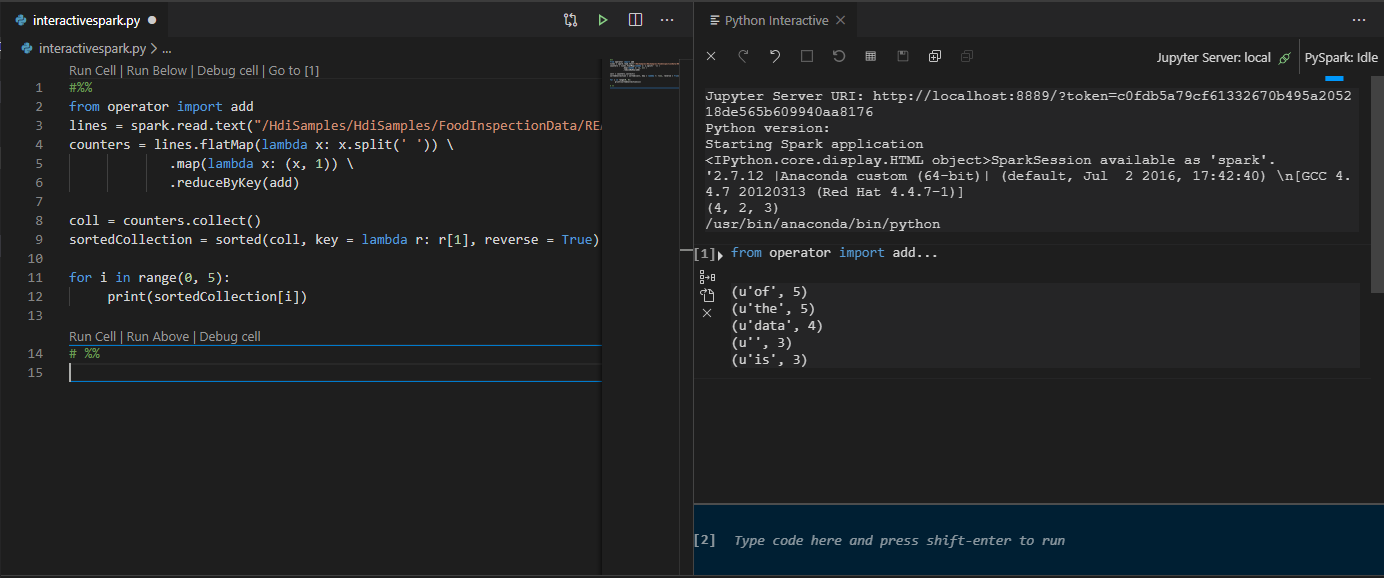
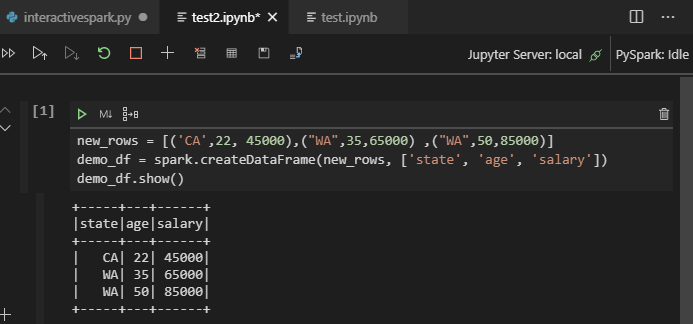
Utnyttja IPYNB-stöd från Python-tillägget
Du kan skapa en Jupyter Notebook med kommando från kommandopaletten eller genom att skapa en ny
.ipynbfil på arbetsytan. Mer information finns i Arbeta med Jupyter Notebooks i Visual Studio CodeKlicka på knappen Kör cell , följ anvisningarna för att ange standard spark-poolen (vi föreslår att du anger standardkluster/pool varje gång innan du öppnar en notebook-fil) och sedan läs in fönstret Igen.
Klicka på PySpark för att växla kernel till PySpark/Synapse Pyspark och klicka sedan på Kör cell. Efter ett tag visas resultatet.
Kommentar
För synapse PySpark-installationsfel, eftersom dess beroende inte kommer att underhållas längre av andra team, kommer detta inte att underhållas längre. Om du försöker använda Synapse Pyspark interaktivt växlar du till att använda Azure Synapse Analytics i stället. Och det är en långsiktig förändring.
Skicka batchjobb för PySpark
Öppna mappen som du diskuterade tidigare, om den
HDexampleär stängd.Skapa en ny BatchFile.py fil genom att följa de tidigare stegen.
Kopiera och klistra in följande kod i skriptfilen:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Anslut till ditt Azure-konto eller länka ett kluster om du inte har gjort det ännu.
Högerklicka på skriptredigeraren och välj sedan Spark: PySpark Batch eller Synapse: PySpark Batch*.
Välj ett kluster/en spark-pool för att skicka pysparkjobbet till:
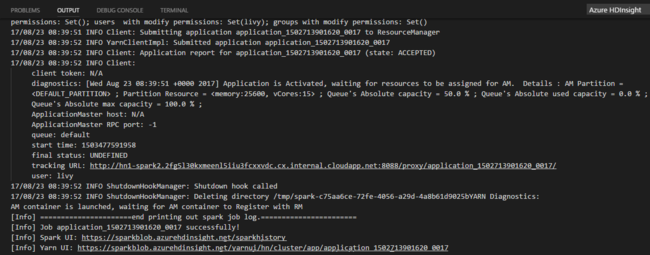
När du har skickat ett Python-jobb visas sändningsloggar i utdatafönstret i Visual Studio Code. Url:en för Spark-användargränssnittet och Yarn-användargränssnittet visas också. Om du skickar batchjobbet till en Apache Spark-pool visas även URL:en för Användargränssnittet för Spark-historik och URL:en för Spark-jobbprogrammets användargränssnitt. Du kan öppna URL:en i en webbläsare för att spåra jobbstatusen.
Integrera med HDInsight Identity Broker (HIB)
Ansluta till ditt HDInsight ESP-kluster med ID Broker (HIB)
Du kan följa de vanliga stegen för att logga in på Azure-prenumerationen för att ansluta till ditt HDInsight ESP-kluster med ID Broker (HIB). Efter inloggningen visas klusterlistan i Azure Explorer. Mer information finns i Ansluta till ditt HDInsight-kluster.
Kör ett Hive/PySpark-jobb i ett HDInsight ESP-kluster med ID Broker (HIB)
För att köra ett hive-jobb kan du följa de normala stegen för att skicka jobbet till HDInsight ESP-kluster med ID Broker (HIB). Mer information finns i Skicka interaktiva Hive-frågor och Hive-batchskript.
För att köra ett interaktivt PySpark-jobb kan du följa de normala stegen för att skicka jobbet till HDInsight ESP-kluster med ID Broker (HIB). Se Skicka interaktiva PySpark-frågor.
För att köra ett PySpark-batchjobb kan du följa de normala stegen för att skicka jobbet till HDInsight ESP-kluster med ID Broker (HIB). Mer information finns i Skicka Batch-jobb i PySpark.
Apache Livy-konfiguration
Apache Livy-konfiguration stöds. Du kan konfigurera den i . VSCode\settings.json fil i arbetsytemappen. Livy-konfigurationen stöder för närvarande endast Python-skript. Mer information finns i Livy README.
Så här utlöser du Livy-konfiguration
Metod 1
- Från menyraden går du till Inställningar för filinställningar>>.
- I rutan Sökinställningar anger du HDInsight Job Submission: Livy Conf.
- Välj Redigera i settings.json för relevant sökresultat.
Metod 2
Skicka en fil och observera att .vscode mappen läggs till automatiskt i arbetsmappen. Du kan se Livy-konfigurationen genom att välja .vscode\settings.json.
Projektinställningarna:
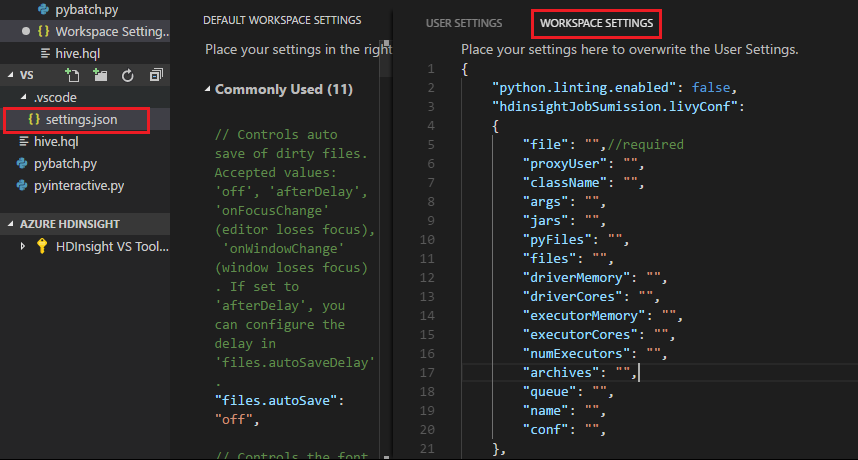
Kommentar
För inställningarna driverMemory och executorMemory anger du värdet och enheten. Till exempel: 1g eller 1024m.
Livy-konfigurationer som stöds:
POST/batchar
Begärandetext
name description type fil Fil som innehåller programmet som ska köras Sökväg (krävs) proxyAnvändare Användare att personifiera när jobbet körs String className Java-/Spark-huvudklass för program String args Kommandoradsargument för programmet Lista över strängar burkar Jars som ska användas i den här sessionen Lista över strängar pyFiles Python-filer som ska användas i den här sessionen Lista över strängar filer Filer som ska användas i den här sessionen Lista över strängar driverMemory Mängden minne som ska användas för drivrutinsprocessen String driverCores Antal kärnor som ska användas för drivrutinsprocessen Int executorMemory Mängden minne som ska användas per körprocess String executorCores Antal kärnor som ska användas för varje köre Int numExecutors Antal utförare som ska startas för den här sessionen Int arkiv Arkiv som ska användas i den här sessionen Lista över strängar kö Namnet på YARN-kön som ska skickas till String name Namnet på den här sessionen String Conf Egenskaper för Spark-konfiguration Karta över key=val Svarstext Det skapade Batch-objektet.
name description type ID Sessions-ID Int appId Program-ID för den här sessionen String appInfo Detaljerad programinformation Karta över key=val logga Loggrader Lista över strängar tillstånd Batch-tillstånd String Kommentar
Den tilldelade Livy-konfigurationen visas i utdatafönstret när du skickar skriptet.
Integrera med Azure HDInsight från Explorer
Du kan förhandsgranska Hive-tabellen i dina kluster direkt via Azure HDInsight-utforskaren:
Anslut till ditt Azure-konto om du inte har gjort det ännu.
Välj Azure-ikonen i kolumnen längst till vänster.
I den vänstra rutan expanderar du AZURE: HDINSIGHT. Tillgängliga prenumerationer och kluster visas.
Expandera klustret för att visa Hive-metadatadatabasen och tabellschemat.
Högerklicka på Hive-tabellen. Till exempel: hivesampletable. Välj Förhandsversion.
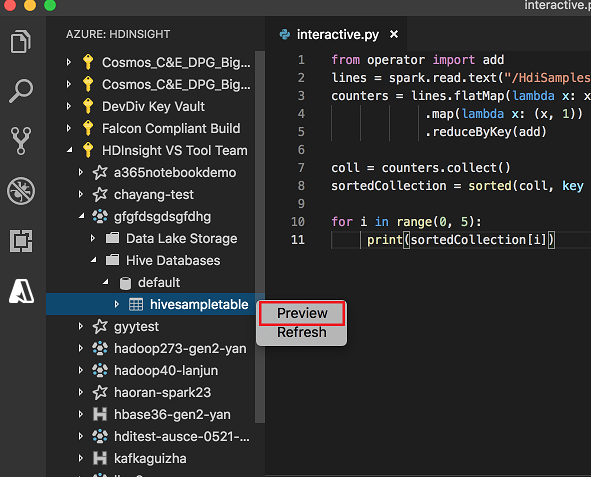
Fönstret Förhandsgranskningsresultat öppnas:
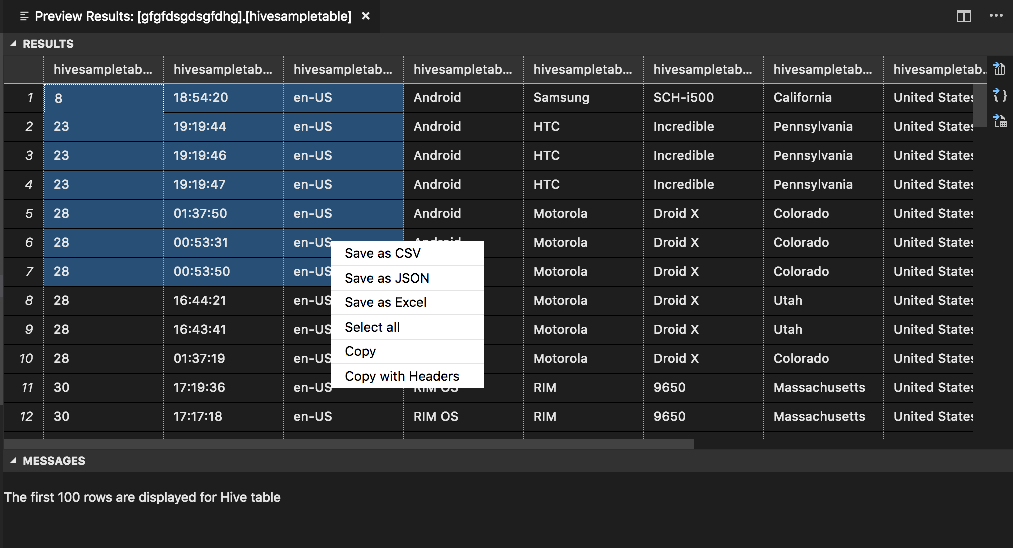
RESULTAT-panelen
Du kan spara hela resultatet som en CSV-, JSON- eller Excel-fil till en lokal sökväg eller bara välja flera rader.
PANELEN MEDDELANDEN
När antalet rader i tabellen är större än 100 visas följande meddelande: "De första 100 raderna visas för Hive-tabellen."
När antalet rader i tabellen är mindre än eller lika med 100 visas följande meddelande: "60 rader visas för Hive-tabellen."
När det inte finns något innehåll i tabellen visas följande meddelande: "
0 rows are displayed for Hive table."Kommentar
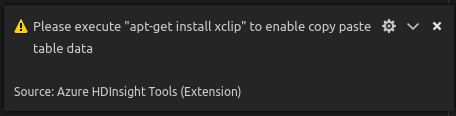
Installera xclip i Linux för att aktivera copy-table-data.
Ytterligare funktioner
Spark & Hive för Visual Studio Code har också stöd för följande funktioner:
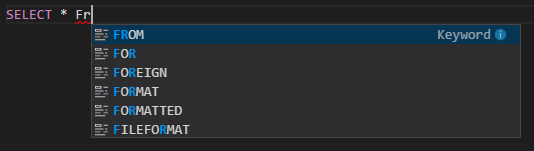
IntelliSense komplettera automatiskt. Förslag visas för nyckelord, metoder, variabler och andra programmeringselement. Olika ikoner representerar olika typer av objekt:
IntelliSense-felmarkör. Språktjänsten understryker redigeringsfel i Hive-skriptet.
Syntaxhöjdpunkter. Språktjänsten använder olika färger för att särskilja variabler, nyckelord, datatyp, funktioner och andra programmeringselement:
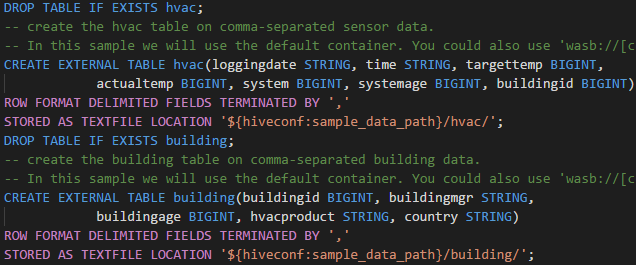
Rollen endast läsare
Användare som har tilldelats rollen endast läsare för klustret kan inte skicka jobb till HDInsight-klustret eller visa Hive-databasen. Kontakta klusteradministratören för att uppgradera din roll till HDInsight-klusteroperatorn i Azure Portal. Om du har giltiga Ambari-autentiseringsuppgifter kan du länka klustret manuellt med hjälp av följande vägledning.
Bläddra i HDInsight-klustret
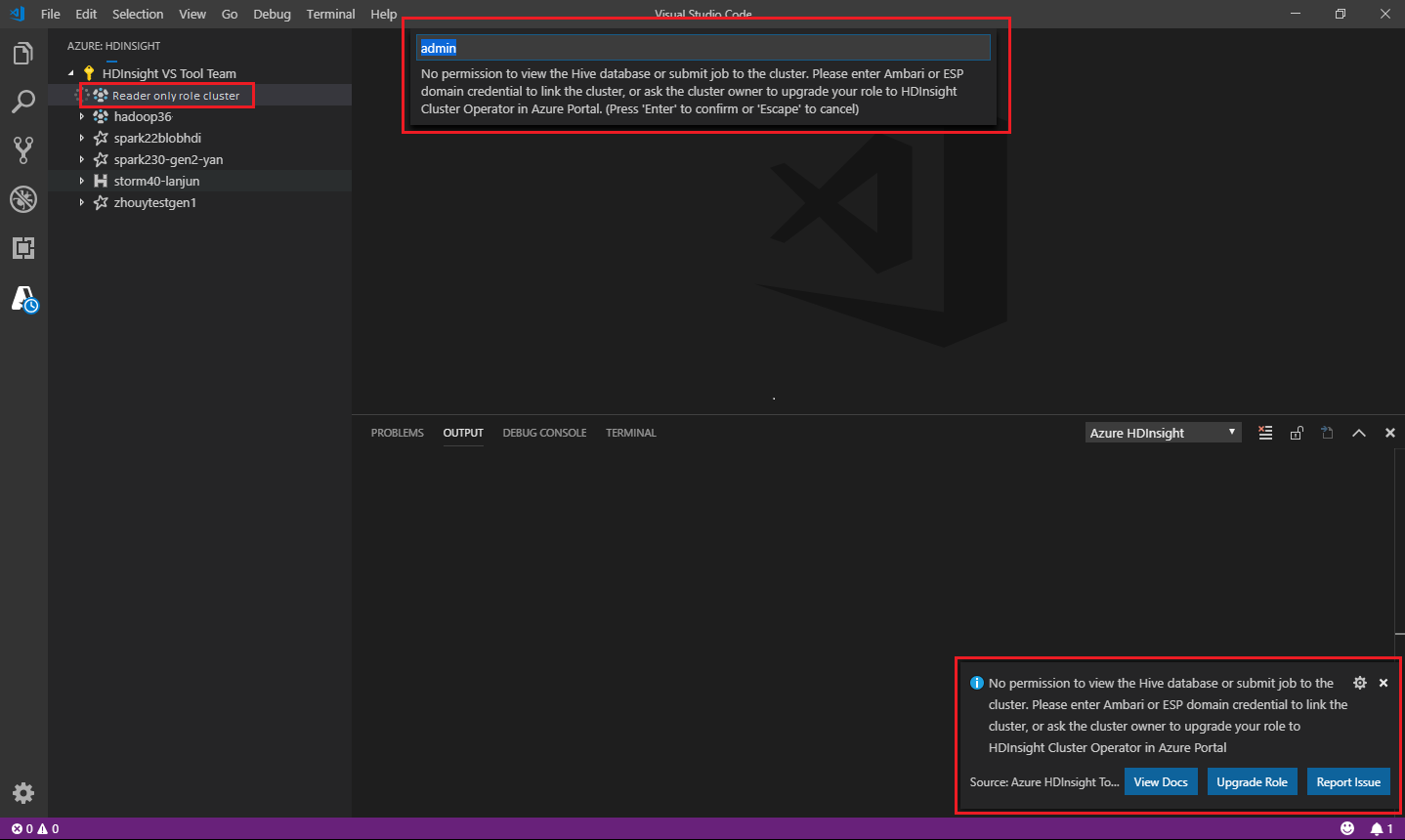
När du väljer Azure HDInsight-utforskaren för att expandera ett HDInsight-kluster uppmanas du att länka klustret om du har rollen som endast läsare för klustret. Använd följande metod för att länka till klustret med dina Ambari-autentiseringsuppgifter.
Skicka jobbet till HDInsight-klustret
När du skickar jobbet till ett HDInsight-kluster uppmanas du att länka klustret om du har rollen som endast läsare för klustret. Använd följande steg för att länka till klustret med Ambari-autentiseringsuppgifter.
Länka till klustret
Ange ett giltigt Ambari-användarnamn.
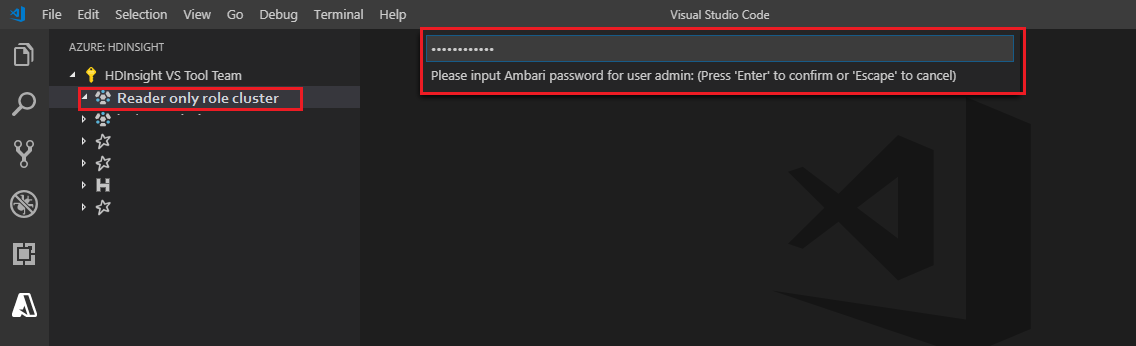
Ange ett giltigt lösenord.
Kommentar
Du kan använda
Spark / Hive: List Clusterför att kontrollera det länkade klustret:
Azure Data Lake Storage Gen2
Bläddra bland ett Data Lake Storage Gen2-konto
Välj Azure HDInsight-utforskaren för att expandera ett Data Lake Storage Gen2-konto. Du uppmanas att ange lagringsåtkomstnyckeln om ditt Azure-konto inte har någon åtkomst till Gen2-lagring. När åtkomstnyckeln har verifierats expanderas Data Lake Storage Gen2-kontot automatiskt.
Skicka jobb till ett HDInsight-kluster med Data Lake Storage Gen2
Skicka ett jobb till ett HDInsight-kluster med Data Lake Storage Gen2. Du uppmanas att ange lagringsåtkomstnyckeln om ditt Azure-konto inte har någon skrivåtkomst till Gen2-lagring. När åtkomstnyckeln har verifierats skickas jobbet.

Kommentar
Du kan hämta åtkomstnyckeln för lagringskontot från Azure Portal. Mer information finns i Hantera åtkomstnycklar för lagringskonto.
Ta bort länk till kluster
Från menyraden går du till Visa>kommandopalett och anger sedan Spark/Hive: Ta bort länk till ett kluster.
Välj ett kluster som ska kopplas från.
Se utdatavyn för verifiering.
Logga ut
Från menyraden går du till Visa>kommandopalett och anger sedan Azure: Logga ut.
Kända problem
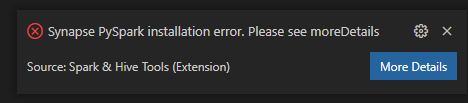
Installationsfel för Synapse PySpark.
För synapse PySpark-installationsfel, eftersom dess beroende inte längre underhålls av andra team, kommer det inte att underhållas längre. Om du försöker använda Synapse Pyspark interaktivt använder du Azure Synapse Analytics i stället. Och det är en långsiktig förändring.
Nästa steg
En video som visar hur du använder Spark & Hive för Visual Studio Code finns i Spark & Hive för Visual Studio Code.