Självstudie: Använda Apache HBase i Azure HDInsight
Den här självstudien visar hur du skapar ett Apache HBase-kluster i Azure HDInsight, skapar HBase-tabeller och frågetabeller med hjälp av Apache Hive. Allmän HBase-information finns i HDInsight HBase-översikt.
I den här självstudien lär du dig att:
- Skapa Apache HBase-kluster
- Skapa HBase-tabeller och infoga data
- Använda Apache Hive för att fråga Apache HBase
- Använd HBase REST API:er med Curl
- Kontrollera klusterstatus
Förutsättningar
En SSH-klient. Mer information finns i Ansluta till HDInsight (Apache Hadoop) med hjälp av SSH.
Våldsamt slag. Exemplen i den här artikeln använder Bash-gränssnittet på Windows 10 för curl-kommandona. Installationssteg finns i installationsguiden för Windows-undersystem för Linux för Windows 10. Andra Unix-gränssnitt fungerar också. Curl-exemplen, med några små ändringar, kan fungera i en Windows-kommandotolk. Du kan också använda Windows PowerShell-cmdleten Invoke-RestMethod.
Skapa Apache HBase-kluster
Följande procedur använder en Azure Resource Manager-mall för att skapa ett HBase-kluster. Mallen skapar också det beroende Azure Storage-standardkontot. Mer information om de parametrar som används i proceduren och andra metoder för att skapa kluster finns i Skapa Linux-baserade Hadoop-kluster i HDInsight.
Välj följande bild för att öppna mallen i Azure Portal. Mallen finns i Azure-snabbstartsmallar.

I dialogrutan Anpassad distribution anger du följande värden:
Property Beskrivning Prenumeration Välj din Azure-prenumeration som används för att skapa klustret. Resursgrupp Skapa en Azure-resurshanteringsgrupp eller använd en befintlig. Plats Ange platsen för resursgruppen. ClusterName Ange ett namn för HBase-klustret. Inloggningsnamn och lösenord för klustret Standardinloggningsnamnet är admin.SSH-användarnamn och lösenord Standardanvändarnamnet är sshuser.Övriga parametrar är valfria.
Varje kluster är beroende av ett Azure Storage-konto. När du har tagit bort ett kluster finns data kvar i lagringskontot. Klustrets lagringskonto av standardtyp har det klusternamn som omfattar tillägget ”store”. Den är hårdkodad i avsnittet mallvariabler.
Välj Jag godkänner villkoren som anges ovan och välj sedan Köp. Det tar cirka 20 minuter att skapa ett kluster.
När ett HBase-kluster har tagits bort kan du skapa ett annat HBase-kluster med samma standardblobcontainer. Det nya klustret hämtar de HBase-tabeller som du skapade i det ursprungliga klustret. Om du vill undvika inkonsekvenser rekommenderar vi att du inaktiverar HBase-tabellerna innan du tar bort klustret.
Skapa tabeller och infoga data
Du kan använda SSH för att ansluta till HBase-kluster och sedan använda Apache HBase Shell för att skapa HBase-tabeller, infoga data och köra frågor mot data.
För de flesta visas data i tabellformat:

I HBase (en implementering av Cloud BigTable) ser samma data ut så här:

Använd HBase Shell
Använd
sshkommandot för att ansluta till ditt HBase-kluster. Redigera följande kommando genom attCLUSTERNAMEersätta med namnet på klustret och ange sedan kommandot:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netAnvänd
hbase shellkommandot för att starta det interaktiva HBase-gränssnittet. Ange följande kommando i din SSH-anslutning:hbase shellAnvänd
createkommandot för att skapa en HBase-tabell med tvåkolumnsfamiljer. Tabell- och kolumnnamnen är skiftlägeskänsliga. Ange följande kommando:create 'Contacts', 'Personal', 'Office'Använd
listkommandot för att visa en lista över alla tabeller i HBase. Ange följande kommando:listAnvänd
putkommandot för att infoga värden i en angiven kolumn på en angiven rad i en viss tabell. Ange följande kommandon:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Använd
scankommandot för att skanna och returneraContactstabelldata. Ange följande kommando:scan 'Contacts'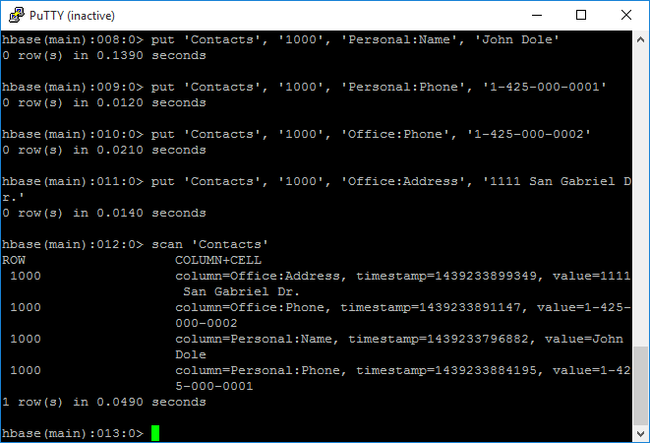
Använd
getkommandot för att hämta innehållet i en rad. Ange följande kommando:get 'Contacts', '1000'Du ser liknande resultat som att använda
scankommandot eftersom det bara finns en rad.Mer information om HBase-tabellschemat finns i Introduktion till Apache HBase-schemadesign. Fler HBase-kommandon finns i referensguiden för Apache HBase.
Använd
exitkommandot för att stoppa det interaktiva HBase-gränssnittet. Ange följande kommando:exit
För att läsa in data i bulk i HBase-tabellen kontakter
HBase innehåller flera metoder för att läsa in data i tabeller. Mer information finns i Massinläsning.
En exempeldatafil finns i en offentlig blob-container, wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. Innehållet i datafilen är:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
Du kan även skapa en textfil och överföra filen till ditt eget lagringskonto. Anvisningarna finns i Ladda upp data för Apache Hadoop-jobb i HDInsight.
Den här proceduren använder den Contacts HBase-tabell som du skapade i den senaste proceduren.
Från den öppna SSH-anslutningen kör du följande kommando för att transformera datafilen till StoreFiles och lagra på en relativ sökväg som anges av
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtKör följande kommando för att ladda upp data från
/example/data/storeDataFileOutputtill HBase-tabellen:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsDu kan öppna HBase-gränssnittet och använda
scankommandot för att visa tabellinnehållet.
Använda Apache Hive för att fråga Apache HBase
Du kan köra frågor mot data i HBase-tabeller med hjälp av Apache Hive. I det här avsnittet skapar du en Hive-tabell som mappar till HBase-tabellen och använder den för att fråga efter data i din HBase-tabell.
Använd följande kommando från den öppna ssh-anslutningen för att starta Beeline:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminMer information om Beeline finns i Use Hive with Hadoop in HDInsight with Beeline (Använda Hive med Hadoop i HDInsight med Beeline).
Kör följande HiveQL-skript för att skapa en Hive-tabell som mappar till HBase-tabellen. Kontrollera att du har skapat exempeltabellen som refererades tidigare i den här artikeln med hjälp av HBase-gränssnittet innan du kör den här instruktionen.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Kör följande HiveQL-skript för att fråga data i HBase-tabellen:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Om du vill avsluta Beeline använder du
!exit.Om du vill avsluta ssh-anslutningen använder du
exit.
Avgränsa Hive- och Hbase-kluster
Hive-frågan för att komma åt HBase-data behöver inte köras från HBase-klustret. Alla kluster som levereras med Hive (inklusive Spark, Hadoop, HBase eller Interaktiv fråga) kan användas för att fråga HBase-data, förutsatt att följande steg har slutförts:
- Båda kluster måste vara anslutna till samma virtuella nätverk och undernät
- Kopiera
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlfrån HBase-klustrets huvudnoder till Hive-klustrets huvudnoder och arbetsnoder.
Säkra kluster
HBase-data kan också frågas från Hive med hjälp av ESP-aktiverad HBase:
- När du följer ett mönster för flera kluster måste båda klustren vara ESP-aktiverade.
- Om du vill tillåta Hive att köra frågor mot HBase-data kontrollerar du att
hiveanvändaren har behörighet att komma åt HBase-data via plugin-programmet Hbase Apache Ranger - När du använder separata, ESP-aktiverade kluster måste innehållet i
/etc/hostsfrån HBase-klustrets huvudnoder läggas till/etc/hostsi Hive-klustrets huvudnoder och arbetsnoder.
Kommentar
När du har skalat något av klusteren /etc/hosts måste du lägga till dem igen
Använda HBase REST API via Curl
HBase REST API skyddas via grundläggande autentisering. Du bör alltid göra begäranden genom att använda säker HTTP (HTTPS) för att säkerställa att dina autentiseringsuppgifter skickas på ett säkert sätt till servern.
Om du vill aktivera HBase REST API i HDInsight-klustret lägger du till följande anpassade startskript i avsnittet Skriptåtgärd . Du kan lägga till startskriptet när du skapar klustret eller när klustret har skapats. För Nodtyp väljer du Regionservrar för att se till att skriptet endast körs i HBase-regionservrar. Skriptet startar HBase REST-proxy på 8090-porten på regionservrar.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiAnge miljövariabel för enkel användning. Redigera följande kommandon genom att ersätta med lösenordet för klusterinloggning
MYPASSWORD. ErsättMYCLUSTERNAMEmed namnet på ditt HBase-kluster. Ange sedan kommandona.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEAnvänd följande kommando för att lista de befintliga HBase-tabellerna:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Använd följande kommando för att skapa en ny HBase-tabell med två kolumnserier:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vSchemat tillhandahålls i JSON-format.
Använd följande kommando för att infoga vissa data:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vBase64 kodar de värden som anges i växeln -d. I exemplet:
MTAwMA ==: 1000
UGVyc29uYWw6TmFtZQ==: Personligt: Namn
Sm9obiBEb2xl: John Dole
false-row-key gör att du kan infoga flera (gruppbaserade) värden.
Använd följande kommando för att få en rad:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Kommentar
Genomsökning via klusterslutpunkten stöds inte ännu.
Mer information om HBase Rest finns i Referensguiden för Apache HBase.
Kommentar
Thrift stöds inte av HBase i HDInsight.
När du använder Curl eller någon annan REST-kommunikation med WebHCat måste du autentisera begäranden genom att ange användarnamnet och lösenordet för HDInsight-klusteradministratören. Du måste också använda klustrets namn som en del av den URI (Uniform Resource Identifier) som används för att skicka begäranden till servern.
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Du bör få ett svar som liknar följande svar:
{"status":"ok","version":"v1"}
Kontrollera klusterstatus
HBase i HDInsight levereras med ett webbgränssnitt för övervakning av kluster. Du kan använda webbgränssnittet för att begära statistik eller information om regioner.
Så här får du åtkomst till HBase Master UI
Logga in på Ambari-webbgränssnittet där
CLUSTERNAMEär namnet påhttps://CLUSTERNAME.azurehdinsight.netditt HBase-kluster.Välj HBase på den vänstra menyn.
Välj Snabblänkar överst på sidan, peka på den aktiva Zookeeper-nodlänken och välj sedan HBase Master UI. Gränssnittet har öppnats i en annan webbläsarflik:
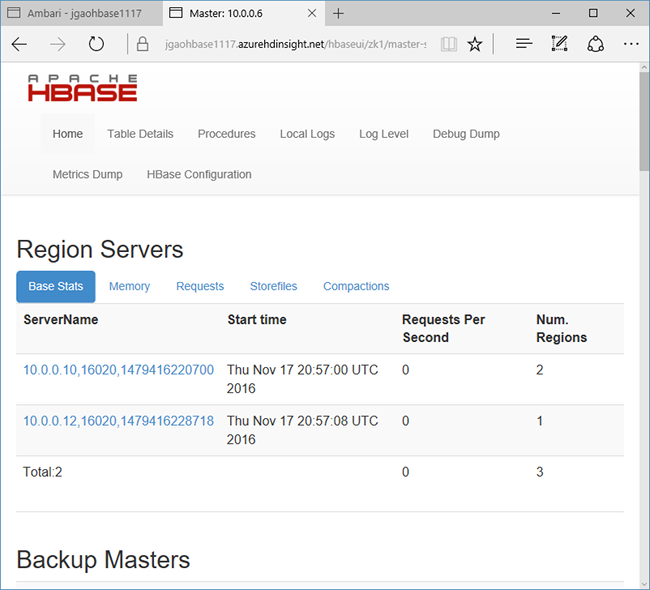
HBase Master UI innehåller följande avsnitt:
- regionservrar
- huvudservrar för säkerhetskopiering
- tabeller
- uppgifter
- attribut för programvara
Klustrets rekreation
När ett HBase-kluster har tagits bort kan du skapa ett annat HBase-kluster med samma standardblobcontainer. Det nya klustret hämtar de HBase-tabeller som du skapade i det ursprungliga klustret. För att undvika inkonsekvenser rekommenderar vi dock att du inaktiverar HBase-tabellerna innan du tar bort klustret.
Du kan använda HBase-kommandot disable 'Contacts'.
Rensa resurser
Om du inte planerar att fortsätta använda det här programmet tar du bort det HBase-kluster som du skapade med följande steg:
- Logga in på Azure-portalen.
- I rutan Sök längst upp skriver du HDInsight.
- Välj HDInsight-kluster under Tjänster.
- I listan över HDInsight-kluster som visas klickar du på ... intill det kluster som du skapade för den här självstudien.
- Klicka på Ta bort. Klicka på Ja.
Nästa steg
I den här självstudien har du lärt dig hur du skapar ett Apache HBase-kluster. Och hur du skapar tabeller och visar data i dessa tabeller från HBase-gränssnittet. Du har också lärt dig hur du använder en Hive-fråga för data i HBase-tabeller. Och hur du använder REST-API:et för HBase C# för att skapa en HBase-tabell och hämta data från tabellen. Mer information finns i: