Använda C# med MapReduce-strömning på Apache Hadoop i HDInsight
Lär dig hur du använder C# för att skapa en MapReduce-lösning i HDInsight.
Med Apache Hadoop-strömning kan du köra MapReduce-jobb med hjälp av ett skript eller en körbar fil. Här används .NET för att implementera mapparen och reducern för en ordräkningslösning.
.NET på HDInsight
HDInsight-kluster använder Mono (https://mono-project.com) för att köra .NET-program. Mono version 4.2.1 ingår i HDInsight version 3.6. Mer information om versionen av Mono som ingår i HDInsight finns i Apache Hadoop-komponenter som är tillgängliga med HDInsight-versioner.
Mer information om monokompatibilitet med .NET Framework-versioner finns i Monokompatibilitet.
Så här fungerar Hadoop-strömning
Den grundläggande process som används för direktuppspelning i det här dokumentet är följande:
- Hadoop skickar data till mapparen (mapper.exe i det här exemplet) på STDIN.
- Mapparen bearbetar data och genererar flikavgränsade nyckel-/värdepar till STDOUT.
- Utdata läss av Hadoop och skickas sedan till reducern (reducer.exe i det här exemplet) på STDIN.
- Reducern läser de flikavgränsade nyckel-/värdeparen, bearbetar data och genererar sedan resultatet som tab-avgränsade nyckel/värde-par på STDOUT.
- Utdata läss av Hadoop och skrivs till utdatakatalogen.
Mer information om strömning finns i Hadoop Streaming.
Förutsättningar
Visual Studio.
Kunskaper om att skriva och skapa C#-kod som riktar sig till .NET Framework 4.5.
Ett sätt att ladda upp .exe filer till klustret. Stegen i det här dokumentet använder Data Lake Tools för Visual Studio för att ladda upp filerna till den primära lagringen för klustret.
Om du använder PowerShell behöver du Az-modulen.
Ett Apache Hadoop-kluster i HDInsight. Se Kom igång med HDInsight i Linux.
URI-schemat för dina klusters primära lagring. Det här schemat skulle vara
wasb://för Azure Storage,abfs://För Azure Data Lake Storage Gen2 elleradl://För Azure Data Lake Storage Gen1. Om säker överföring är aktiverad för Azure Storage eller Data Lake Storage Gen2 blirwasbs://URI:n respektiveabfss://.
Skapa mappningsverktyget
Skapa ett nytt .NET Framework-konsolprogram med namnet mapper i Visual Studio. Använd följande kod för programmet:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
När du har skapat programmet skapar du det för att skapa /bin/Debug/mapper.exe filen i projektkatalogen.
Skapa reducern
I Visual Studio skapar du ett nytt .NET Framework-konsolprogram med namnet reducer. Använd följande kod för programmet:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
När du har skapat programmet skapar du det för att skapa /bin/Debug/reducer.exe filen i projektkatalogen.
Ladda upp till lagring
Därefter måste du ladda upp mappnings- och reducerprogrammen till HDInsight Storage.
I Visual Studio väljer du Visa>serverutforskaren.
Högerklicka på Azure, välj Anslut till Microsoft Azure-prenumeration... och slutför inloggningsprocessen.
Expandera det HDInsight-kluster som du vill distribuera det här programmet till. En post med texten (standardlagringskonto) visas.
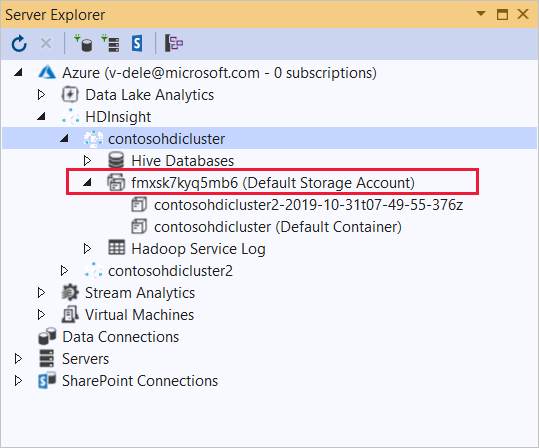
Om posten (standardlagringskonto) kan utökas använder du ett Azure Storage-konto som standardlagring för klustret. Om du vill visa filerna på standardlagringen för klustret expanderar du posten och dubbelklickar sedan på (standardcontainer).
Om posten (standardlagringskonto) inte kan expanderas använder du Azure Data Lake Storage som standardlagring för klustret. Om du vill visa filerna på standardlagringen för klustret dubbelklickar du på posten (standardlagringskonto).
Om du vill ladda upp .exe filer använder du någon av följande metoder:
Om du använder ett Azure Storage-konto väljer du ikonen Ladda upp blob.

I dialogrutan Ladda upp ny fil går du till Filnamn och väljer Bläddra. I dialogrutan Ladda upp blob går du till mappen bin\debug för mappningsprojektet och väljer sedan filen mapper.exe. Välj slutligen Öppna och sedan OK för att slutföra uppladdningen.
För Azure Data Lake Storage högerklickar du på ett tomt område i fillistan och väljer sedan Ladda upp. Välj slutligen filen mapper.exe och välj sedan Öppna.
När mapper.exe uppladdningen är klar upprepar du uppladdningsprocessen för reducer.exe-filen.
Kör ett jobb: Använda en SSH-session
Följande procedur beskriver hur du kör ett MapReduce-jobb med en SSH-session:
Använd ssh-kommandot för att ansluta till klustret. Redigera kommandot nedan genom att ersätta CLUSTERNAME med namnet på klustret och ange sedan kommandot:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netAnvänd något av följande kommandon för att starta MapReduce-jobbet:
Om standardlagringen är Azure Storage:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutOm standardlagringen är Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutOm standardlagringen är Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
I följande lista beskrivs vad varje parameter och alternativ representerar:
Parameter Description hadoop-streaming.jar Anger jar-filen som innehåller den strömmande MapReduce-funktionen. -filer Anger mapper.exe- och reducer.exe-filerna för det här jobbet. Protokolldeklarationen wasbs:///,adl:///ellerabfs:///före varje fil är sökvägen till roten för standardlagring för klustret.-Mapper Anger den fil som implementerar mapparen. -Reducering Anger filen som implementerar reducern. -inmatning Anger indata. -utdata Anger utdatakatalogen. När MapReduce-jobbet har slutförts använder du följande kommando för att visa resultatet:
hdfs dfs -text /example/wordcountout/part-00000Följande text är ett exempel på de data som returneras av det här kommandot:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Kör ett jobb: Använda PowerShell
Använd följande PowerShell-skript för att köra ett MapReduce-jobb och ladda ned resultatet.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Det här skriptet uppmanar dig att ange namn och lösenord för klusterinloggningskontot tillsammans med HDInsight-klusternamnet. När jobbet är klart laddas utdata ned till en fil med namnet output.txt. Följande text är ett exempel på data i output.txt filen:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17