Använda Azure Machine Learning Notebook på Spark
Kommentar
Vi drar tillbaka Azure HDInsight på AKS den 31 januari 2025. Före den 31 januari 2025 måste du migrera dina arbetsbelastningar till Microsoft Fabric eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar. Återstående kluster i din prenumeration stoppas och tas bort från värden.
Endast grundläggande stöd kommer att vara tillgängligt fram till datumet för pensionering.
Viktigt!
Den här funktionen finns i förhandsgranskning. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. Om du vill ha frågor eller funktionsförslag skickar du en begäran på AskHDInsight med informationen och följer oss för fler uppdateringar i Azure HDInsight Community.
Maskininlärning är en växande teknik som gör det möjligt för datorer att lära sig automatiskt från tidigare data. Maskininlärning använder olika algoritmer för att skapa matematiska modeller och göra förutsägelser med historiska data eller information. Vi har en modell som har definierats upp till vissa parametrar, och inlärning är körningen av ett datorprogram för att optimera modellens parametrar med hjälp av träningsdata eller erfarenhet. Modellen kan vara förutsägande för att göra förutsägelser i framtiden eller beskrivande för att få kunskap från data.
Följande notebook-fil för självstudier visar ett exempel på hur du tränar maskininlärningsmodeller på tabelldata. Du kan importera den här notebook-filen och köra den själv.
Ladda upp CSV:en till lagringen
Hitta ditt lagrings- och containernamn i JSON-portalvyn
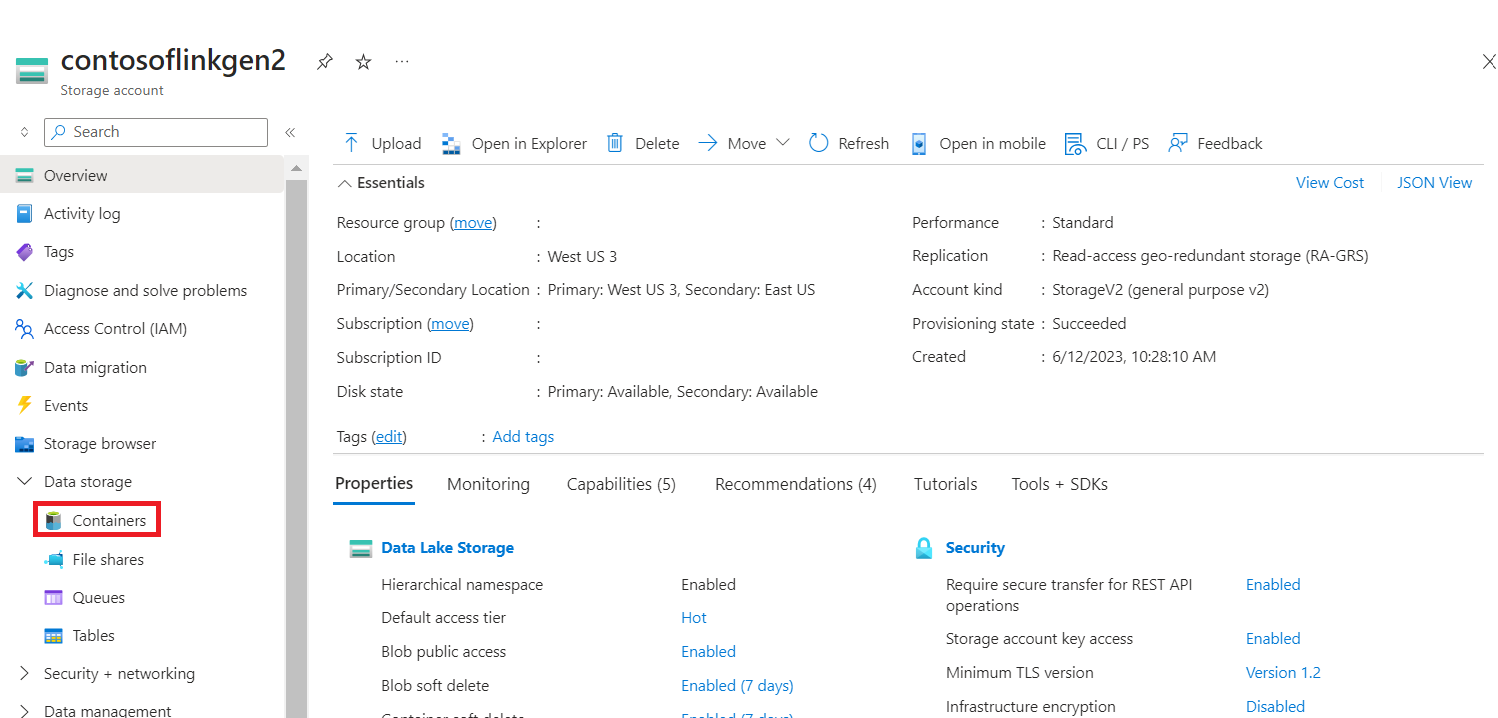
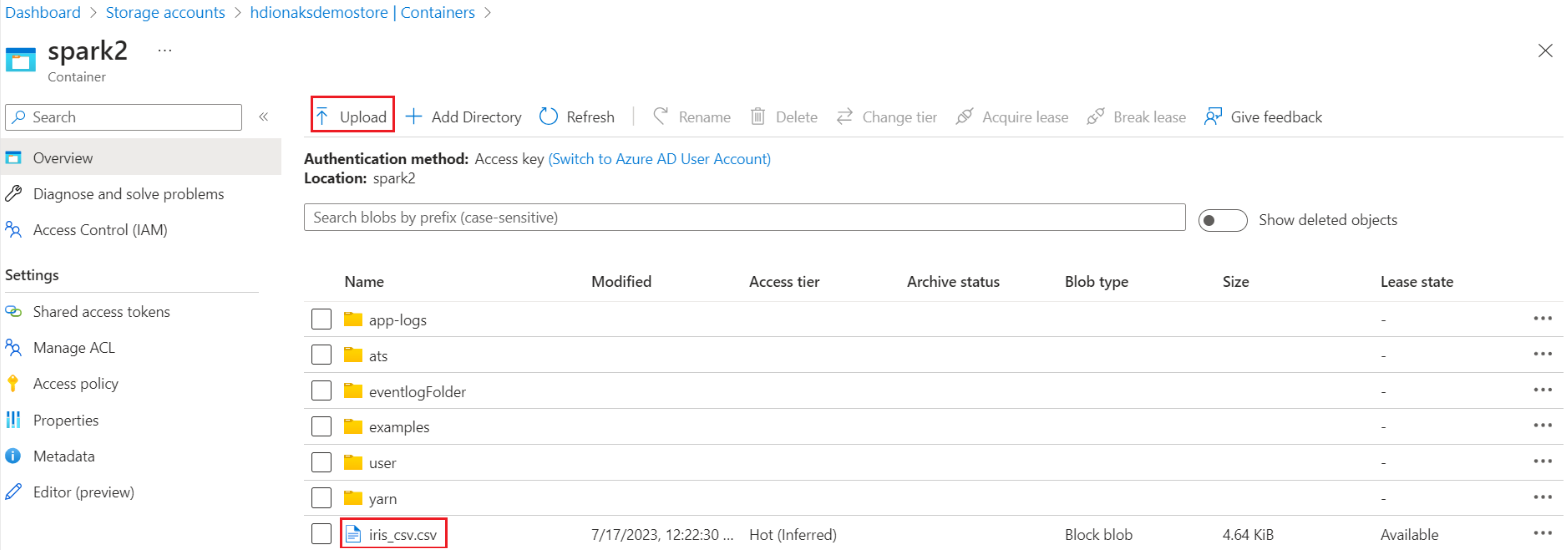
Navigera till din primära HDI-lagringscontainerbasmapp>>> och ladda upp CSV:en
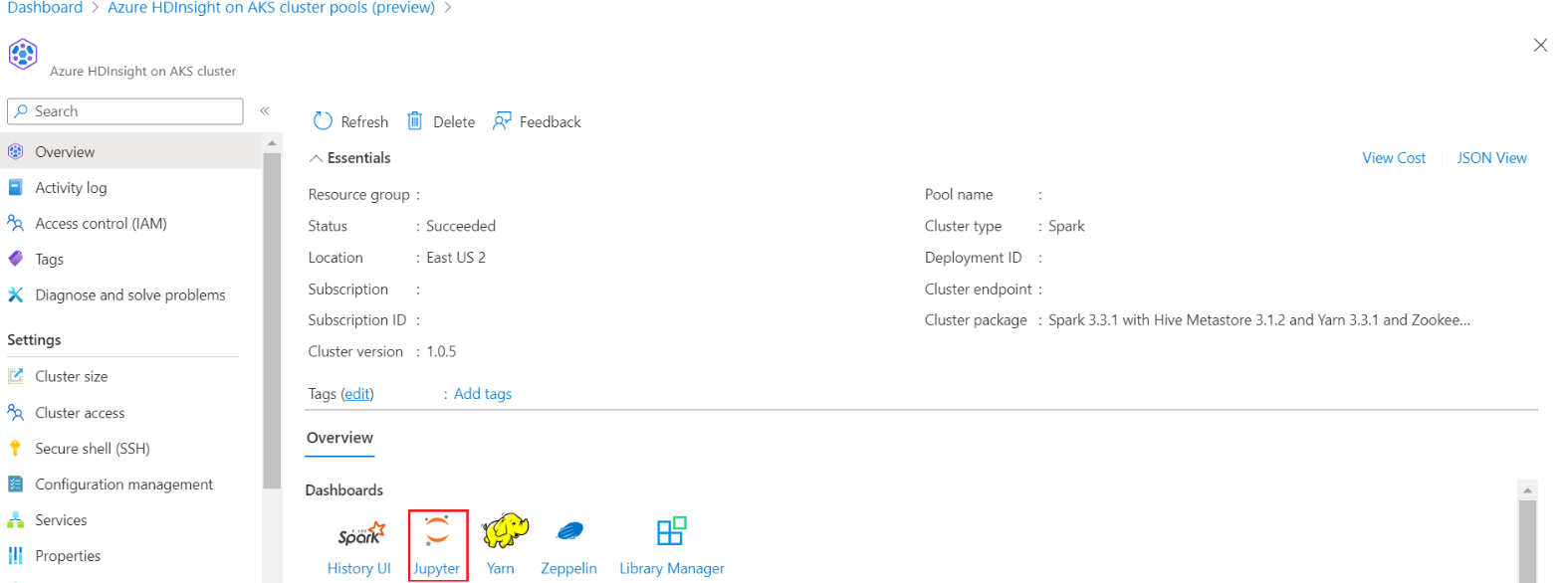
Logga in på klustret och öppna Jupyter Notebook
Importera Spark MLlib-bibliotek för att skapa pipelinen
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Läsa CSV:en i en Spark-dataram
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)Dela upp data för träning och testning
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)Skapa pipelinen och träna modellen
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
Utvärdera modellens noggrannhet
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))



