Vad är Apache Spark™ i HDInsight på AKS? (Förhandsversion)
Viktig
Azure HDInsight på AKS drogs tillbaka den 31 januari 2025. Läs mer om genom den här tillkännagivelsen.
Du måste migrera dina arbetsbelastningar till Microsoft Fabric- eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar.
Viktig
Den här funktionen är för närvarande i förhandsversion. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller som ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. För frågor eller funktionsförslag, skicka en begäran på AskHDInsight med information och följ oss för fler uppdateringar om Azure HDInsight Community.
Apache Spark™ är ett ramverk för parallell bearbetning som stöder minnesintern bearbetning för att öka prestandan för analysprogram med stordata.
Apache Spark™ tillhandahåller primitiver för minnesintern klusterberäkning. Ett Spark-jobb kan läsa in och cachelagera data i minnet och köra frågor mot dem upprepade gånger. Minnesintern databehandling är snabbare än diskbaserade program, till exempel Hadoop, som delar data via Hadoop-distribuerat filsystem (HDFS). Med Apache Spark kan du integrera med programmeringsspråken Scala och Python så att du kan ändra distribuerade datauppsättningar som lokala samlingar. Du behöver inte strukturera allt som kartera- och reduce-operationer.
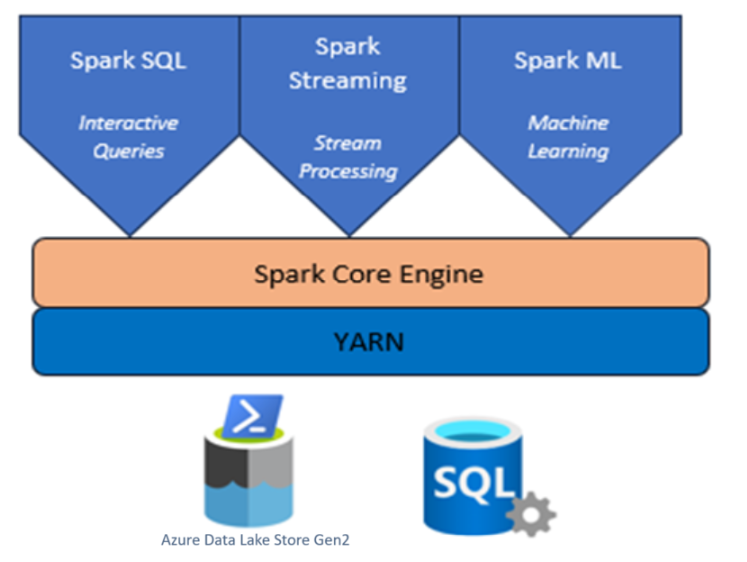
Apache Spark-kluster med HDInsight på AKS
Azure HDInsight är en hanterad analystjänst med fullständigt spektrum med öppen källkod för företag.
Apache Spark™ i Azure HDInsight på AKS är den hanterade Spark-tjänsten i Microsoft Azure. Med Apache Spark i Azure HDInsight på AKS kan du lagra och bearbeta dina data i Azure. Spark-kluster i HDInsight är kompatibla med eller Azure Data Lake Storage Gen2, så att du kan använda Spark-bearbetning på dina befintliga datalager.
Apache Spark-ramverket för HDInsight på AKS möjliggör snabb dataanalys och klusterberäkning med hjälp av minnesintern bearbetning. Med Jupyter Notebook kan du interagera med dina data, kombinera kod med markdown-text och göra enkla visualiseringar.
Apache Spark på AKS i HDInsight består av flera komponenter som poddar.
Klusterkontrollanter
Klusterstyrenheter ansvarar för att installera och hantera respektive tjänst. Olika styrenheter installeras och hanteras i ett Spark-kluster.
Apache Spark-tjänstkomponenter
Zookeeper-tjänsten: Ett Zookeeper-kluster med tre noder fungerar som distribuerad koordinator eller lagring med hög tillgänglighet för andra tjänster.
Yarn-tjänst: I Hadoop Yarn-klustret schemaläggs Spark-jobb som Yarn-applikationer.
-klientgränssnitt: Apache Spark-kluster i HDInsight på AKS tillhandahåller olika klientgränssnitt. Livy Server, Jupyter Notebook, Spark History Server, tillhandahåller Spark-tjänster till HDInsight på AKS-användare.
Hänvisning
- Apache, Apache Spark, Spark och associerade projekt med öppen källkod är varumärken som tillhör Apache Software Foundation (ASF).