Vad är Apache Flink® i Azure HDInsight på AKS? (Förhandsversion)
Viktig
Azure HDInsight på AKS drogs tillbaka den 31 januari 2025. Läs mer i det här meddelandet.
Du måste migrera dina arbetsbelastningar till Microsoft Fabric- eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar.
Viktig
Den här funktionen är för närvarande i förhandsversion. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för funktioner i Azure som är i beta, förhandsversion eller på annat sätt ännu inte tillgängliga i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS förhandsversionsinformation. För frågor eller funktionsförslag, vänligen skicka en begäran på AskHDInsight med informationen och följ oss för fler uppdateringar i Azure HDInsight Community.
Apache Flink- är ett ramverk och en distribuerad bearbetningsmotor för tillståndskänsliga beräkningar över obundna och begränsade dataströmmar. Flink har utformats för att köras i alla vanliga klustermiljöer, utföra beräkningar och tillståndskänsliga strömningsprogram i minnesintern hastighet och i valfri skala. Program parallelliseras till eventuellt tusentals uppgifter som distribueras och körs samtidigt i ett kluster. Därför kan ett program använda obegränsade mängder vCPU:er, huvudminne, disk och nätverks-I/O. Dessutom hanterar Flink enkelt ett stort programtillstånd. Dessas asynkrona och inkrementella kontrollpunktsalgoritm garanterar minimal påverkan på bearbetningslatenser samtidigt som den garanterar exakt en gångs tillståndskonsistens.
Apache Flink är en massivt skalbar analysmotor för dataströmbearbetning.
Några av de viktigaste funktionerna som Flink erbjuder är:
- Åtgärder på begränsade och obundna strömmar
- Minnesprestanda
- Möjlighet för både strömnings- och batchberäkningar
- Operationer med låg svarstid, högt dataflöde
- Exakt en gångs bearbetning
- Hög tillgänglighet
- Tillstånds- och feltolerans
- Fullständigt kompatibelt med Hadoop-ekosystemet
- Enhetliga SQL-API:er för både dataström och batch
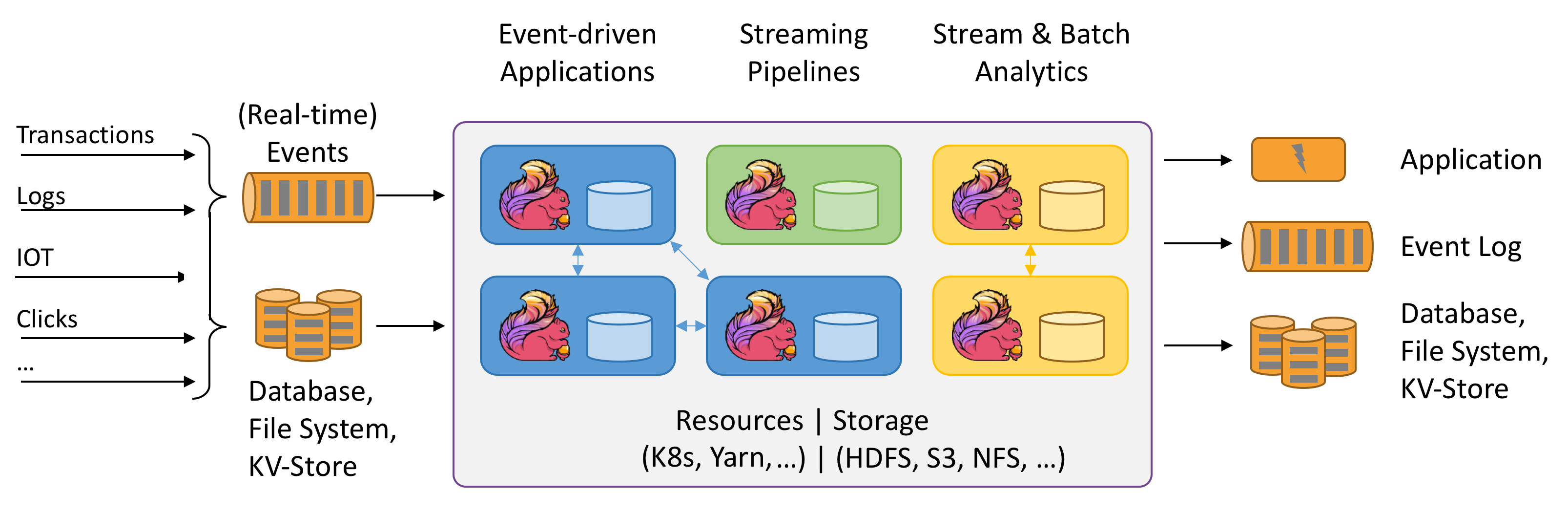
Varför Apache Flink?
Apache Flink är ett utmärkt val för att utveckla och köra många olika typer av program på grund av dess omfattande funktioner. Flinks funktioner omfattar stöd för dataströms- och batchbearbetning, avancerad tillståndshantering, bearbetning av händelsetidens semantik och exakt en gångs konsistensgarantier för tillstånd. Flink har inte en enda felpunkt. Flink har visat sig skala till tusentals kärnor och terabyte programtillstånd, ger högt dataflöde och låg svarstid och driver några av världens mest krävande dataströmbearbetningsprogram.
- Bedrägeriidentifiering: Flink kan användas för att identifiera bedrägliga transaktioner eller aktiviteter i realtid genom att tillämpa komplexa regler och maskininlärningsmodeller på strömmande data.
- Avvikelseidentifiering: Flink kan användas för att identifiera extremvärden eller onormala mönster i strömmande data, till exempel sensoravläsningar, nätverkstrafik eller användarbeteende.
- Regelbaserad avisering: Flink kan användas för att utlösa aviseringar eller meddelanden baserat på fördefinierade villkor eller tröskelvärden för strömmande data, till exempel temperatur, tryck eller aktiekurser.
- Affärsprocessövervakning: Flink kan användas för att spåra och analysera status och prestanda för affärsprocesser eller arbetsflöden i realtid, till exempel orderuppfyllelse, leverans eller kundtjänst.
- webbprogram (sociala nätverk): Flink kan användas för att driva webbprogram som kräver realtidsbearbetning av användargenererade data, till exempel meddelanden, gilla-markeringar, kommentarer eller rekommendationer.
Läs mer om vanliga användningsfall som beskrivs i Apache Flink-användningsfall
Apache Flink-kluster i HDInsight på AKS är en fullständigt hanterad tjänst. Här visas fördelarna med att skapa ett Flink-kluster i HDInsight på AKS.
| Funktion | Beskrivning |
|---|---|
| Enkelt att skapa | Du kan skapa ett nytt Flink-kluster i HDInsight på några minuter med hjälp av Azure-portalen, Azure PowerShell eller SDK:n. Se Komma igång med Apache Flink-kluster i HDInsight på AKS. |
| Användarvänlighet | Flink-kluster i HDInsight på AKS omfattar portalbaserad konfigurationshantering och skalning. Utöver detta med jobbhanterings-API använder du REST-API:et eller Azure-portalen för jobbhantering. |
| REST-API:er | Flink-kluster i HDInsight på AKS omfattar API för jobbhantering, en REST API-baserad Flink-jobböverföringsmetod för att skicka och övervaka jobb på Azure-portalen via fjärranslutning. |
| Distributionstyp | Flink kan köra program i sessionsläge eller programläge. För närvarande stöder HDInsight på AKS endast sessionskluster. Du kan köra flera Flink-jobb i ett sessionskluster. Appläget finns med i utvecklingsplanen för HDInsight på AKS-kluster |
| Stöd för Metastore | Flink-kluster i HDInsight på AKS kan stödja kataloger med Hive Metastore i olika öppna filformat med fjärrkontrollpunkter till Azure Data Lake Storage Gen2. |
| Stöd för Azure Storage | Flink-kluster i HDInsight kan använda Azure Data Lake Storage Gen2 som lagringsmål. Mer information om Data Lake Storage Gen2 finns i Azure Data Lake Storage Gen2. |
| Integrering med Azure-tjänster | Flink-kluster i HDInsight på AKS kommer med integration till Kafka tillsammans med Azure Event Hubs och Azure HDInsight. Du kan skapa strömmande program med hjälp av Event Hubs eller HDInsight. |
| Anpassningsförmåga | MED HDInsight på AKS kan du skala Flink-klusternoderna baserat på schema med funktionen Autoskalning. Se Skala Azure HDInsight automatiskt på AKS-kluster. |
| Backend för tillståndshantering | HDInsight på AKS använder RocksDB- som standard StateBackend. RocksDB är ett beständigt nyckelvärdesarkiv som kan bäddas in för snabb lagring. |
| Kontrollpunkter | Kontrollpunkter är aktiverat i HDInsight i AKS-kluster som standard. Standardinställningarna för HDInsight på AKS upprätthåller de senaste fem kontrollpunkterna i beständiga lagring. Om jobbet misslyckas kan jobbet startas om från den senaste kontrollpunkten. |
| Inkrementella kontrollpunkter | RocksDB stöder inkrementella kontrollpunkter. Vi rekommenderar att du använder inkrementella kontrollpunkter för stor status. Den här funktionen måste aktiveras manuellt. Om du anger ett standardvärde i din flink-conf.yaml: state.backend.incremental: true aktiveras inkrementella kontrollpunkter, såvida inte programmet åsidosätter den här inställningen i koden. Det här påståendet är sant som standardinställning. Du kan också konfigurera det här värdet direkt i koden (åsidosätter konfigurationsstandarden) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); . Som standard bevarar vi de fem sista kontrollpunkterna i den konfigurerade kontrollpunktsdir. Det här värdet kan ändras genom att ändra konfigurationen i avsnittet konfigurationshantering state.checkpoints.num-retained: 5 |
Apache Flink-kluster i HDInsight på AKS innehåller följande komponenter, de är tillgängliga i klustren som standard.
Se färdplan för vad som kommer snart!
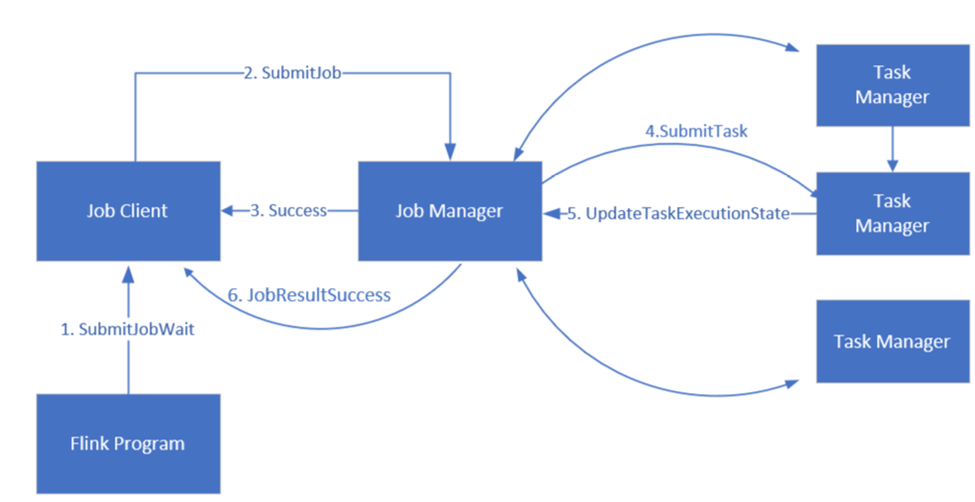
Jobbhantering för Apache Flink
Flink schemalägger jobb med hjälp av tre distribuerade komponenter, Jobbhanterare, Aktivitetshanterare och Jobbklient, som anges i ett Leader-Follower mönster.
Flink Job: Ett Flink-jobb eller -program består av flera aktiviteter. Uppgifter är den grundläggande körningsenheten i Flink. Varje Flink-uppgift har flera instanser beroende på graden av parallellitet och varje instans körs på en TaskManager.
Job manager: Jobbhanteraren fungerar som schemaläggare och schemalägger uppgifter för uppgiftshanterare.
Uppgiftshanteraren: Uppgiftshanterare har en eller flera platser för att köra uppgifter parallellt.
Jobbklient: Jobbklienten kommunicerar med jobbhanteraren för att skicka Flink-jobb
webbgränssnittet för Flink: Flink har ett webbgränssnitt för att inspektera, övervaka och felsöka program som körs.
Hänvisning
- Apache Flink webbplats
- Apache, Apache Kafka, Kafka, Apache Flink, Flink och associerade projektnamn med öppen källkod är varumärken för Apache Software Foundation (ASF).