Snabbstart: Samla in Event Hubs-data i Azure Storage och läs dem med hjälp av Python (azure-eventhub)
Du kan konfigurera en händelsehubb så att data som skickas till en händelsehubb samlas in i ett Azure Storage-konto eller Azure Data Lake Storage Gen 1 eller Gen 2. Den här artikeln visar hur du skriver Python-kod för att skicka händelser till en händelsehubb och läsa insamlade data från Azure Blob Storage. Mer information om den här funktionen finns i Översikt över event hubs capture-funktionen.
Den här snabbstarten använder Azure Python SDK för att demonstrera avbildningsfunktionen. Appen sender.py skickar simulerad miljötelemetri till händelsehubbar i JSON-format. Händelsehubben är konfigurerad för att använda avbildningsfunktionen för att skriva dessa data till Blob Storage i batchar. Den capturereader.py appen läser dessa blobar och skapar en tilläggsfil för varje enhet. Appen skriver sedan data till CSV-filer.
I den här snabbstarten kommer du att göra följande:
- Skapa ett Azure Blob Storage-konto och en container i Azure-portalen.
- Skapa ett Event Hubs-namnområde med hjälp av Azure-portalen.
- Skapa en händelsehubb med avbildningsfunktionen aktiverad och anslut den till ditt lagringskonto.
- Skicka data till din händelsehubb med hjälp av ett Python-skript.
- Läsa och bearbeta filer från Event Hubs Capture med hjälp av ett annat Python-skript.
Förutsättningar
Python 3.8 eller senare, med pip installerat och uppdaterat.
En Azure-prenumeration Om du inte har ett konto kan du skapa ett kostnadsfritt konto innan du börjar.
En aktiv Event Hubs-namnrymd och händelsehubb. Skapa ett Event Hubs-namnområde och en händelsehubb i namnområdet. Registrera namnet på Event Hubs-namnområdet, namnet på händelsehubben och den primära åtkomstnyckeln för namnområdet. Information om hur du hämtar åtkomstnyckeln finns i Hämta en händelsehubb anslutningssträng. Standardnyckelnamnet är RootManageSharedAccessKey. För den här snabbstarten behöver du bara primärnyckeln. Du behöver inte anslutningssträng.
Ett Azure Storage-konto, en blobcontainer i lagringskontot och en anslutningssträng till lagringskontot. Om du inte har de här objekten gör du följande:
- Skapa ett Azure Storage-konto
- Skapa en blobcontainer i lagringskontot
- Hämta anslutningssträng till lagringskontot
Se till att registrera anslutningssträng och containernamnet för senare användning i den här snabbstarten.
Aktivera avbildningsfunktionen för händelsehubben
Aktivera avbildningsfunktionen för händelsehubben. Det gör du genom att följa anvisningarna i Aktivera Event Hubs Capture med hjälp av Azure-portalen. Välj lagringskontot och blobcontainern som du skapade i föregående steg. Välj Avro som format för serialisering av utdatahändelser.
Skapa ett Python-skript för att skicka händelser till din händelsehubb
I det här avsnittet skapar du ett Python-skript som skickar 200 händelser (10 enheter * 20 händelser) till en händelsehubb. Dessa händelser är ett exempel på miljöavläsning som skickas i JSON-format.
Öppna din favoritredigerare för Python, till exempel Visual Studio Code.
Skapa ett skript med namnet sender.py.
Klistra in följande kod i sender.py.
import time import os import uuid import datetime import random import json from azure.eventhub import EventHubProducerClient, EventData # This script simulates the production of events for 10 devices. devices = [] for x in range(0, 10): devices.append(str(uuid.uuid4())) # Create a producer client to produce and publish events to the event hub. producer = EventHubProducerClient.from_connection_string(conn_str="EVENT HUBS NAMESAPCE CONNECTION STRING", eventhub_name="EVENT HUB NAME") for y in range(0,20): # For each device, produce 20 events. event_data_batch = producer.create_batch() # Create a batch. You will add events to the batch later. for dev in devices: # Create a dummy reading. reading = { 'id': dev, 'timestamp': str(datetime.datetime.utcnow()), 'uv': random.random(), 'temperature': random.randint(70, 100), 'humidity': random.randint(70, 100) } s = json.dumps(reading) # Convert the reading into a JSON string. event_data_batch.add(EventData(s)) # Add event data to the batch. producer.send_batch(event_data_batch) # Send the batch of events to the event hub. # Close the producer. producer.close()Ersätt följande värden i skripten:
- Ersätt
EVENT HUBS NAMESPACE CONNECTION STRINGmed anslutningssträng för Event Hubs-namnområdet. - Ersätt
EVENT HUB NAMEmed namnet på din händelsehubb.
- Ersätt
Kör skriptet för att skicka händelser till händelsehubben.
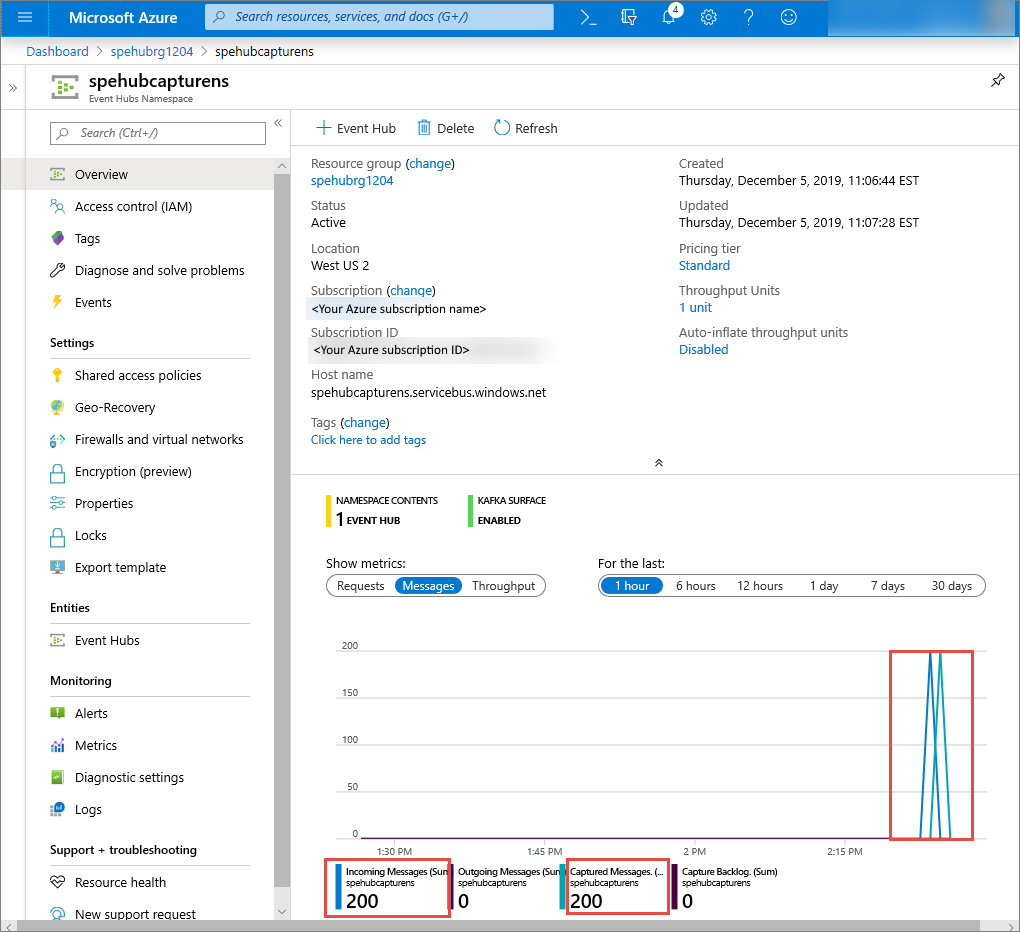
I Azure-portalen kan du kontrollera att händelsehubben har tagit emot meddelandena. Växla till vyn Meddelanden i avsnittet Mått . Uppdatera sidan för att uppdatera diagrammet. Det kan ta några sekunder för sidan att visa att meddelandena har tagits emot.

Skapa ett Python-skript för att läsa avbildningsfiler
I det här exemplet lagras insamlade data i Azure Blob Storage. Skriptet i det här avsnittet läser de insamlade datafilerna från ditt Azure Storage-konto och genererar CSV-filer som du enkelt kan öppna och visa. Du ser 10 filer i programmets aktuella arbetskatalog. Dessa filer innehåller miljöavläsningarna för de 10 enheterna.
Skapa ett skript med namnet capturereader.py i Python-redigeraren. Det här skriptet läser de insamlade filerna och skapar en fil för varje enhet för att endast skriva data för den enheten.
Klistra in följande kod i capturereader.py.
import os import string import json import uuid import avro.schema from azure.storage.blob import ContainerClient, BlobClient from avro.datafile import DataFileReader, DataFileWriter from avro.io import DatumReader, DatumWriter def processBlob2(filename): reader = DataFileReader(open(filename, 'rb'), DatumReader()) dict = {} for reading in reader: parsed_json = json.loads(reading["Body"]) if not 'id' in parsed_json: return if not parsed_json['id'] in dict: list = [] dict[parsed_json['id']] = list else: list = dict[parsed_json['id']] list.append(parsed_json) reader.close() for device in dict.keys(): filename = os.getcwd() + '\\' + str(device) + '.csv' deviceFile = open(filename, "a") for r in dict[device]: deviceFile.write(", ".join([str(r[x]) for x in r.keys()])+'\n') def startProcessing(): print('Processor started using path: ' + os.getcwd()) # Create a blob container client. container = ContainerClient.from_connection_string("AZURE STORAGE CONNECTION STRING", container_name="BLOB CONTAINER NAME") blob_list = container.list_blobs() # List all the blobs in the container. for blob in blob_list: # Content_length == 508 is an empty file, so process only content_length > 508 (skip empty files). if blob.size > 508: print('Downloaded a non empty blob: ' + blob.name) # Create a blob client for the blob. blob_client = ContainerClient.get_blob_client(container, blob=blob.name) # Construct a file name based on the blob name. cleanName = str.replace(blob.name, '/', '_') cleanName = os.getcwd() + '\\' + cleanName with open(cleanName, "wb+") as my_file: # Open the file to write. Create it if it doesn't exist. my_file.write(blob_client.download_blob().readall()) # Write blob contents into the file. processBlob2(cleanName) # Convert the file into a CSV file. os.remove(cleanName) # Remove the original downloaded file. # Delete the blob from the container after it's read. container.delete_blob(blob.name) startProcessing()Ersätt
AZURE STORAGE CONNECTION STRINGmed anslutningssträng för ditt Azure Storage-konto. Namnet på containern som du skapade i den här snabbstarten är capture. Om du använde ett annat namn för containern ersätter du avbildningen med namnet på containern i lagringskontot.
Kör skripten
Öppna en kommandotolk som har Python i sin sökväg och kör sedan dessa kommandon för att installera Python-nödvändiga paket:
pip install azure-storage-blob pip install azure-eventhub pip install avro-python3Ändra katalogen till katalogen där du sparade sender.py och capturereader.py och kör det här kommandot:
python sender.pyDet här kommandot startar en ny Python-process för att köra avsändaren.
Vänta några minuter tills avbildningen körs och ange sedan följande kommando i det ursprungliga kommandofönstret:
python capturereader.pyDen här insamlingsprocessorn använder den lokala katalogen för att ladda ned alla blobar från lagringskontot och containern. Den bearbetar filer som inte är tomma och skriver resultatet som CSV-filer till den lokala katalogen.