Utöka stora språkmodeller med hämtningsförhöjd generering eller finjustering
I en serie artiklar diskuterar vi de mekanismer för kunskapshämtning som stora språkmodeller (LLM) använder för att generera svar. Som standard har en LLM endast åtkomst till sina träningsdata. Men du kan utöka modellen till att omfatta realtidsdata eller privata data.
Den första mekanismen är hämtningförstärkt generering (RAG). RAG är en form av förbearbetning som kombinerar semantisk sökning med kontextuell priming. Kontextuell priming beskrivs i detalj i Viktiga begrepp och överväganden för att skapa generativa AI-lösningar.
Den andra mekanismen är finjustering . Vid finjustering tränas en LLM ytterligare på en specifik datamängd efter den inledande breda utbildningen. Målet är att anpassa LLM för att prestera bättre på uppgifter eller förstå begrepp som är relaterade till datamängden. Den här processen hjälper modellen att specialisera sig eller förbättra dess noggrannhet och effektivitet vid hantering av specifika typer av indata eller domäner.
I följande avsnitt beskrivs dessa två mekanismer mer detaljerat.
Förstå RAG
RAG används ofta för att aktivera scenariot "chatta över mina data". I det här scenariot har en organisation en potentiellt stor mängd textinnehåll, till exempel dokument, dokumentation och andra upphovsrättsskyddade data. Den använder denna corpus som grund för svar på användarfrågor.
På hög nivå skapar du en databaspost för varje dokument eller för en del av ett dokument som kallas segment. Segmentet indexeras baserat på dess inbäddning, dvs. en vektor (matris) med tal som representerar aspekter av dokumentet. När en användare skickar en fråga söker du i databasen efter liknande dokument och skickar sedan frågan och dokumenten till LLM för att skapa ett svar.
Kommentar
Vi använder termen retrieval-augmented generation (RAG) på ett anpassningsbart sätt. Processen med att implementera ett RAG-baserat chattsystem enligt beskrivningen i den här artikeln kan tillämpas oavsett om du vill använda externa data i en stödjande kapacitet (RAG) eller som mittpunkt i svaret (RCG). Den nyanserade skillnaden behandlas inte i de flesta läsningar relaterade till RAG.
Skapa ett index över vektoriserade dokument
Det första steget för att skapa ett RAG-baserat chattsystem är att skapa ett vektordatalager som innehåller vektorinbäddningen av dokumentet eller segmentet. Tänk på följande diagram som beskriver de grundläggande stegen för att skapa ett vektoriserat index av dokument.

Diagrammet representerar ett dataflöde. Pipelinen ansvarar för inmatning, bearbetning och hantering av data som systemet använder. Pipelinen innehåller förbearbetning av data som ska lagras i vektordatabasen och säkerställer att de data som matas in i LLM är i rätt format.
Hela processen drivs av begreppet inbäddning, vilket är en numerisk representation av data (vanligtvis ord, fraser, meningar eller till och med hela dokument) som fångar in indatas semantiska egenskaper på ett sätt som kan bearbetas av maskininlärningsmodeller.
Om du vill skapa en inbäddning skickar du innehållssegmentet (meningar, stycken eller hela dokument) till AZURE OpenAI Embeddings API. API:et returnerar en vektor. Varje värde i vektorn representerar en egenskap (dimension) av innehållet. Dimensioner kan omfatta ämnesämne, semantisk betydelse, syntax och grammatik, ord- och frasanvändning, kontextuella relationer, stil eller ton. Tillsammans representerar alla värden i vektorn innehållets dimensionella utrymme. Om du tänker på en 3D-representation av en vektor som har tre värden finns en specifik vektor i ett specifikt område i XYZ-planets plan. Vad händer om du har 1 000 värden eller ännu fler? Även om det inte är möjligt för människor att rita ett diagram med 1 000 dimensioner på ett pappersark för att göra det mer förståeligt, har datorer inga problem med att förstå den graden av dimensionsutrymme.
Nästa steg i diagrammet visar lagring av vektorn och innehållet (eller en pekare till innehållets plats) och andra metadata i en vektordatabas. En vektordatabas är som vilken typ av databas som helst, men med två skillnader:
- Vektordatabaser använder en vektor som ett index för att söka efter data.
- Vektordatabaser implementerar en algoritm som kallas cosinuslikhetssökning, också kallad närmaste granne. Algoritmen använder vektorer som bäst matchar sökvillkoren.
Med corpus av dokument som lagras i en vektordatabas kan utvecklare skapa en retrieverkomponent för att hämta dokument som matchar användarens fråga. Data används för att förse LLM med det den behöver för att besvara användarens fråga.
Besvara frågor med hjälp av dina dokument
Ett RAG-system använder först semantisk sökning för att hitta artiklar som kan vara till hjälp för LLM när det skapar ett svar. Nästa steg är att skicka matchande artiklar med användarens ursprungliga uppmaning till LLM för att skriva ett svar.
Tänk på följande diagram som en enkel RAG-implementering (kallas ibland naiv RAG-):
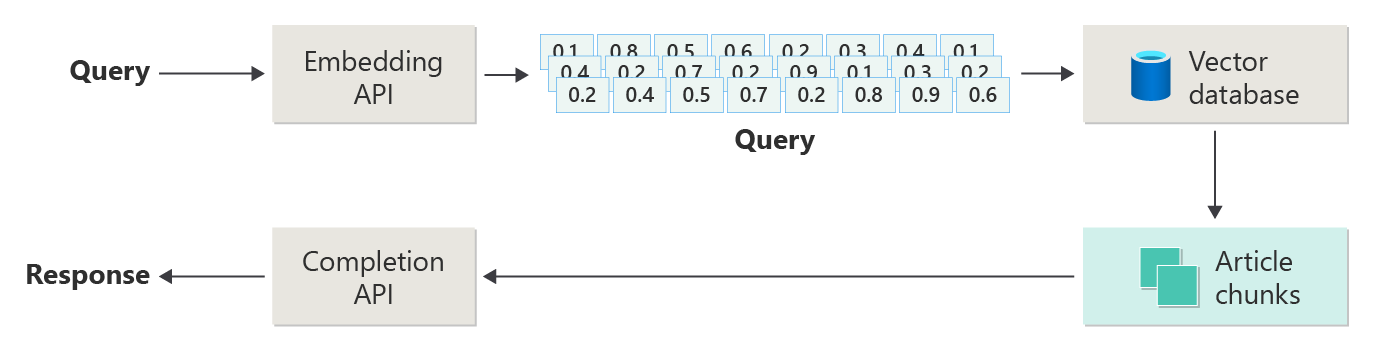
I diagrammet skickar en användare en fråga. Det första steget är att skapa en inbäddning för användarens uppmaning att returnera en vektor. Nästa steg är att söka i vektordatabasen efter de dokument (eller delar av dokument) som är en närmaste grannmatchning.
Cosinin likhet är ett mått som hjälper till att avgöra hur lika två vektorer är. I huvudsak bedömer måttet cosinus för vinkeln mellan dem. En cosininlikitet som är nära 1 indikerar en hög grad av likhet (en liten vinkel). En likhet nära -1 indikerar olikhet (en vinkel på nästan 180 grader). Det här måttet är avgörande för uppgifter som dokumentlikhet, där målet är att hitta dokument som har liknande innehåll eller betydelse.
Närmaste grannalgoritmer fungera genom att hitta närmaste vektorer (grannar) för en punkt i vektorutrymmet. I algoritmen k-nearest neighbors (KNN)refererar k till antalet närmaste grannar att tänka på. Den här metoden används ofta i klassificering och regression, där algoritmen förutsäger etiketten för en ny datapunkt baserat på majoritetsetiketten för dess k närmaste grannar i träningsuppsättningen. KNN- och cosininelikhet används ofta tillsammans i system som rekommendationsmotorer, där målet är att hitta objekt som mest liknar en användares inställningar, som representeras som vektorer i inbäddningsutrymmet.
Du tar det bästa resultatet från sökningen och skickar det matchande innehållet tillsammans med användarens uppmaning för att generera ett svar som (förhoppningsvis) är informerat av matchande innehåll.
Utmaningar och överväganden
Ett RAG-system har en uppsättning implementeringsutmaningar. Datasekretess är av största vikt. Systemet måste hantera användardata på ett ansvarsfullt sätt, särskilt när det hämtar och bearbetar information från externa källor. Beräkningskrav kan också vara betydande. Både hämtningsprocessen och de generativa processerna är resursintensiva. Att säkerställa noggrannhet och relevans för svar vid hantering av fördomar i data eller modell är en annan viktig faktor. Utvecklare måste navigera i dessa utmaningar noggrant för att skapa effektiva, etiska och värdefulla RAG-system.
Skapa avancerade hämtningsförhöjda generationssystem ger dig mer information om hur du skapar data- och slutsatsdragningspipelines för att aktivera ett produktionsklart RAG-system.
Om du vill börja experimentera med att skapa en generativ AI-lösning omedelbart rekommenderar vi att du tar en titt på Kom igång med chatten med ditt eget dataexempel för Python. Självstudien är också tillgänglig för .NET, Javaoch JavaScript.
Finjustera en modell
I samband med en LLM är finjustering processen att justera modellens parametrar genom att träna den på en domänspecifik datauppsättning efter att LLM ursprungligen tränades på en stor, varierad datauppsättning.
LLM:er tränas (förtränade) på en bred datauppsättning, greppar språkstruktur, kontext och en mängd olika kunskaper. I det här steget ingår att lära sig allmänna språkmönster. Finjustering lägger till mer träning till den förtränad modellen baserat på en mindre, specifik datauppsättning. Den här sekundära utbildningsfasen syftar till att anpassa modellen för att prestera bättre på vissa uppgifter eller förstå specifika domäner, vilket förbättrar dess noggrannhet och relevans för dessa specialiserade program. Vid finjustering justeras modellens vikter för att bättre förutsäga eller förstå nyanserna i den här mindre datamängden.
Några saker att tänka på:
- Specialisering: Finjustering skräddarsyr modellen efter specifika uppgifter, till exempel juridisk dokumentanalys, medicinsk texttolkning eller kundtjänstinteraktioner. Den här specialiseringen gör modellen mer effektiv inom dessa områden.
- Effektivitet: Det är mer effektivt att finjustera en förtränad modell för en specifik uppgift än att träna en modell från grunden. Finjustering kräver mindre data och färre beräkningsresurser.
- Anpassningsbarhet: Finjustering möjliggör anpassning till nya uppgifter eller domäner som inte ingick i de ursprungliga träningsdata. Anpassningsbarheten hos LLM:er gör dem till mångsidiga verktyg för olika program.
- Förbättrad prestanda: För uppgifter som skiljer sig från de data som modellen ursprungligen tränades på kan finjustering leda till bättre prestanda. Finjustering justerar modellen för att förstå ett specifikt språk, stil eller terminologi som används i nya domänen.
- Anpassning: I vissa program kan finjustering hjälpa till att anpassa modellens svar eller förutsägelser så att de passar specifika behov eller inställningar för en användare eller organisation. Finjustering har dock specifika nackdelar och begränsningar. Att förstå dessa faktorer kan hjälpa dig att bestämma när du ska välja finjustering jämfört med alternativ som RAG.
- Datakrav: Finjustering kräver en tillräckligt stor och högkvalitativ datauppsättning som är specifik för måluppgiften eller domänen. Att samla in och kurera den här datamängden kan vara utmanande och resurskrävande.
- Risk för överanpassning: Överanpassning är en risk, särskilt med en liten datamängd. Överanpassning gör att modellen fungerar bra på träningsdata men dåligt på nya, osynliga data. Generaliserbarheten minskar när överanpassning sker.
- Kostnad och resurser: Även om det är mindre resurskrävande än träning från grunden kräver finjustering fortfarande beräkningsresurser, särskilt för stora modeller och datauppsättningar. Kostnaden kan vara oöverkomlig för vissa användare eller projekt.
- Underhåll och uppdatering av: Finjusterade modeller kan behöva regelbundna uppdateringar för att förbli effektiva när domänspecifik information ändras över tid. Det här pågående underhållet kräver extra resurser och data.
- ModellavdriftEftersom modellen är finjusterad för specifika uppgifter kan den förlora en del av sin allmänna språkförståelse och mångsidighet. Det här fenomenet kallas modellavdrift.
Anpassa en modell genom finjustering förklarar hur du finjusterar en modell. På hög nivå tillhandahåller du en JSON-datauppsättning med potentiella frågor och önskade svar. Dokumentationen tyder på att det finns märkbara förbättringar genom att tillhandahålla 50 till 100 par med frågor och svar, men rätt antal varierar kraftigt i användningsfallet.
Finjustering jämfört med RAG
På ytan kan det verka som om det finns en hel del överlappning mellan finjustering och RAG. Valet mellan finjustering och hämtningsförhöjd generation beror på de specifika kraven för din uppgift, inklusive prestandaförväntningar, resurstillgänglighet och behovet av domänspecifikhet kontra generaliserbarhet.
När du ska använda finjustering i stället för RAG:
- Aktivitetsspecifik prestanda: Finjustering är att föredra när höga prestanda för en viss uppgift är kritisk och det finns tillräckligt med domänspecifika data för att träna modellen effektivt utan betydande överanpassningsrisker.
- Kontroll över data: Om du har proprietära eller högspecialiserade data som skiljer sig avsevärt från de data som basmodellen har tränats på kan du med finjustering införliva den här unika kunskapen i modellen.
- Begränsat behov av realtidsuppdateringar: Om aktiviteten inte kräver att modellen uppdateras kontinuerligt med den senaste informationen kan finjustering vara effektivare eftersom RAG-modeller vanligtvis behöver åtkomst till up-to-date externa databaser eller Internet för att hämta nya data.
När du ska föredra RAG framför finjustering:
- Dynamiskt innehåll eller innehåll som utvecklas: RAG är mer lämpligt för uppgifter där det är viktigt att ha den senaste informationen. Eftersom RAG-modeller kan hämta data från externa källor i realtid passar de bättre för program som nyhetsgenerering eller svar på frågor om de senaste händelserna.
- Generalisering över specialisering: Om målet är att upprätthålla starka prestanda i en mängd olika ämnen i stället för att utmärka sig i en smal domän kan RAG vara att föredra. Den använder externa kunskapsbas, vilket gör att den kan generera svar över olika domäner utan risk för överanpassning till en specifik datauppsättning.
- Resursbegränsningar: För organisationer med begränsade resurser för datainsamling och modellträning kan användning av en RAG-metod vara ett kostnadseffektivt alternativ till finjustering, särskilt om basmodellen redan presterar ganska bra på önskade uppgifter.
Slutliga överväganden för programdesign
Här är en kort lista över saker att tänka på och andra lärdomar från den här artikeln som kan påverka dina beslut om programdesign:
- Bestäm mellan finjustering och RAG baserat på programmets specifika behov. Finjustering kan ge bättre prestanda för specialiserade uppgifter, medan RAG kan ge flexibilitet och up-to-date-innehåll för dynamiska program.