Så här skapar du enkla, effektiva och låg svarstid datapipelines
Dagens datadrivna företag producerar kontinuerligt data, vilket kräver tekniska datapipelines som kontinuerligt matar in och transformerar dessa data. Dessa pipelines bör kunna bearbeta och leverera data exakt en gång, ge resultat med svarstider som är mindre än 200 millisekunder och alltid försöka minimera kostnaderna.
Den här artikeln beskriver metoder för batch- och inkrementell dataströmbearbetning för tekniska datapipelines, varför inkrementell dataströmbearbetning är det bättre alternativet och nästa steg för att komma igång med Databricks inkrementella dataströmbearbetningserbjudanden, Streaming på Azure Databricks och Vad är DLT?. Med de här funktionerna kan du snabbt skriva och köra pipelines som garanterar leveranssemantik, svarstid, kostnad med mera.
Fallgroparna för upprepade batchjobb
När du konfigurerar datapipelinen kan du först skriva upprepade batchjobb för att mata in dina data. Varje timme kan du till exempel köra ett Spark-jobb som läser från källan och skriver data till en mottagare som Delta Lake. Utmaningen med den här metoden är att stegvis bearbeta din källa, eftersom Spark-jobbet som körs varje timme måste börja där det sista slutade. Du kan registrera den senaste tidsstämpeln för de data som du har bearbetat och sedan välja alla rader med tidsstämplar som är nyare än tidsstämpeln, men det finns fallgropar:
Om du vill köra en kontinuerlig datapipeline kan du försöka schemalägga ett batchjobb per timme som inkrementellt läser från källan, gör transformeringar och skriver resultatet till en mottagare, till exempel Delta Lake. Den här metoden kan ha fallgropar:
- Ett Spark-jobb som frågar efter alla nya data efter en tidsstämpel missar sena data.
- Ett Spark-jobb som misslyckas kan leda till att exakt-en-gång-garantier bryts, om de inte hanteras med omsorg.
- Ett Spark-jobb som visar innehållet på molnlagringsplatser för att hitta nya filer blir dyrt.
Sedan behöver du fortfarande transformera dessa data upprepade gånger. Du kan skriva upprepade batchjobb som sedan aggregerar dina data eller tillämpar andra åtgärder, vilket ytterligare komplicerar och minskar effektiviteten i pipelinen.
Ett batchexempel
Om du vill förstå fallgroparna för batchinmatning och transformering för din pipeline kan du titta på följande exempel.
Saknade data
Med ett Kafka-topic som innehåller användningsdata som avgör hur mycket dina kunder debiteras, och din pipeline processas i batchar, kan händelsesekvensen se ut så här:
- Din första batch har två poster kl. 08.00 och 08.30.
- Du uppdaterar den senaste tidsstämpeln till 08:30.
- Du får ett nytt rekord 08:15.
- Din andra sats begär allt efter 08:30, så du missar noteringen klockan 08:15.
Dessutom vill du inte överdebitera eller underdebitera dina användare, så du måste se till att du matar in varje post exakt en gång.
Redundant bearbetning
Anta sedan att dina data innehåller rader med användarköp och att du vill aggregera försäljningen per timme så att du vet de mest populära tiderna i din butik. Om inköp för samma timme tas emot i olika batchar har du flera batchar som producerar utdata för samma timme:
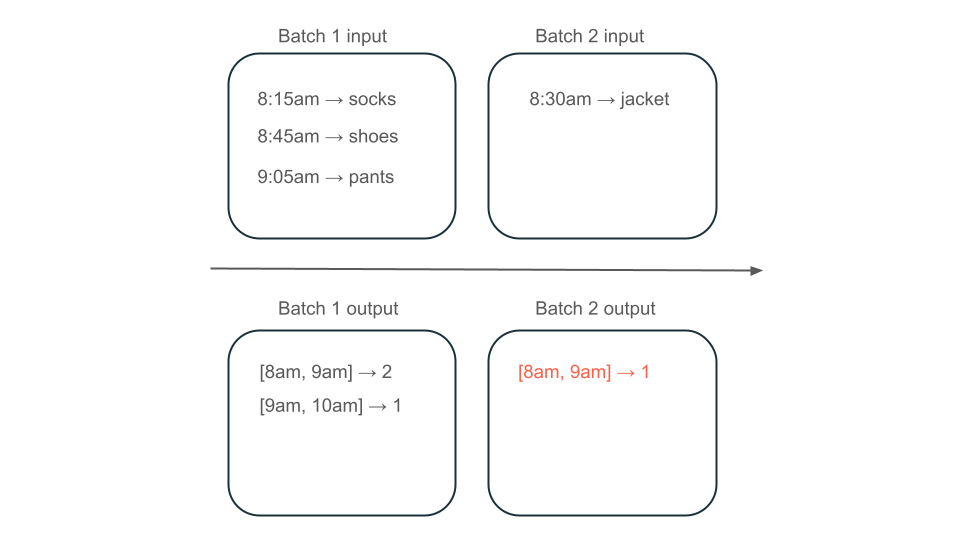
Har fönstret från 08:00 till 09:00 två element (utdata från batch 1), ett element (utdata från batch 2) eller tre (utdata från ingen av batcharna)? Den data som krävs för att producera ett givet tidsfönster visas över flera transformeringsbatcher. För att lösa detta kan du partitionera dina data per dag och bearbeta hela partitionen igen när du behöver beräkna ett resultat. Sedan kan du skriva över resultatet i din mottagare:
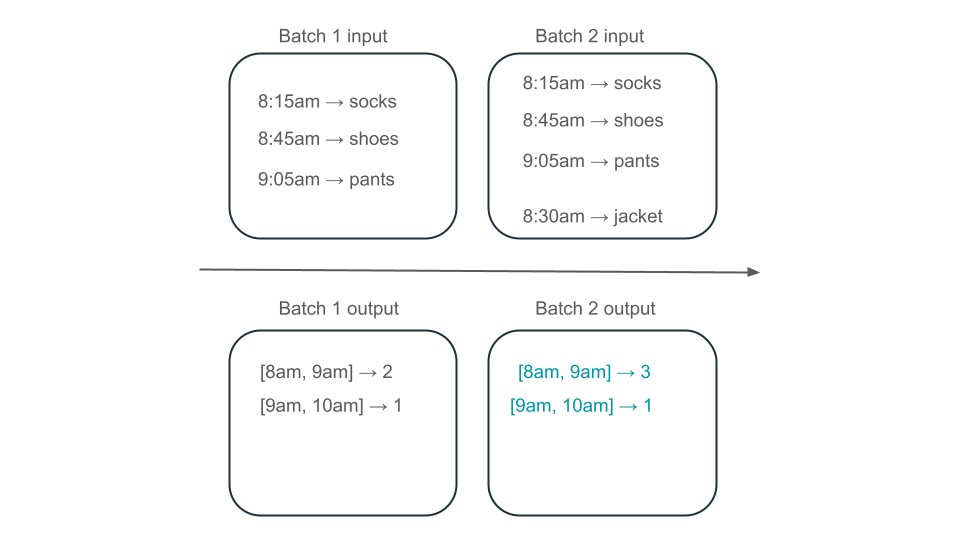
Detta sker dock på bekostnad av svarstid och kostnad, eftersom den andra batchen måste utföra det onödiga arbetet med att bearbeta data som den kanske redan har bearbetat.
Inga fallgropar med inkrementell dataströmbearbetning
Inkrementell dataströmbearbetning gör det enkelt att undvika alla fallgropar för upprepade batchjobb för att mata in och transformera data. Databricks Structured Streaming och DLT hanterar implementeringskomplexiteter för strömmande data så att du bara kan fokusera på din affärslogik. Du behöver bara ange vilken källa du ska ansluta till, vilka omvandlingar som ska göras till data och var resultatet ska skrivas.
Inkrementell inmatning
Inkrementell inmatning i Databricks drivs av Apache Spark Structured Streaming, som inkrementellt kan använda en datakälla och skriva den till en mottagare. Structured Streaming-maskinen kan läsa data exakt en gång, och maskinen kan hantera oordnad data. Motorn kan köras antingen i notebook-filer eller med hjälp av strömmande tabeller i DLT.
Structured Streaming-motorn på Databricks tillhandahåller egna strömningskällor, till exempel AutoLoader, som stegvis kan bearbeta molnfiler på ett kostnadseffektivt sätt. Databricks tillhandahåller även anslutningar för andra populära meddelandebussar som Apache Kafka, Amazon Kinesis, Apache Pulsaroch Google Pub/Sub.
Inkrementell omvandling
Med inkrementell omvandling i Databricks med Structured Streaming kan du ange transformeringar till DataFrames med samma API som en batchfråga, men den spårar data över batchar och aggregerade värden över tid så att du inte behöver göra det. Den behöver aldrig bearbeta data igen, så det är snabbare och mer kostnadseffektivt än upprepade batchjobb. Strukturerad direktuppspelning genererar en dataström som den kan lägga till i din mottagare, till exempel Delta Lake, Kafka eller någon annan anslutning som stöds.
Materialized Views i DLT drivs av enzymmotorn. Enzymet bearbetar fortfarande inkrementellt källan, men i stället för att producera en ström skapar det en materialiserad vy, som är en förberäknad tabell som lagrar resultatet av en fråga som du ger den. Enzymet kan effektivt avgöra hur nya data påverkar resultatet av din fråga, och det behåller den förberäknade tabellen up-to-date.
Materialiserade vyer skapar en vy över ditt aggregat som alltid effektivt uppdaterar sig själv så att du till exempel vet att fönstret 8:00 till 09:00 har tre element i scenariot som beskrivs ovan.
Strukturerad direktuppspelning eller DLT?
Den betydande skillnaden mellan Structured Streaming och DLT är det sätt på vilket du operationaliserar dina strömningsfrågor. I Strukturerad direktuppspelning anger du manuellt många konfigurationer och du måste manuellt sammanfoga frågor. Du måste uttryckligen starta frågor, vänta tills de avslutas, avbryta dem vid fel samt utföra andra relaterade åtgärder. I DLT ger du deklarativt DLT dina pipelines att köra, och det håller dem igång.
DLT har också funktioner som materialiserade vyer, som effektivt och stegvis förberäknar omvandlingar av dina data.
Mer information om dessa funktioner finns i Streaming on Azure Databricks and What is DLT?.
Nästa steg
- Skapa din första pipeline med DLT. Se Självstudie: Kör din första DLT-pipeline.
- Kör dina första frågor om strukturerad direktuppspelning på Databricks. Se Kör din första strukturerade strömningsuppgift.
- Använd en materialiserad vy. Se. Använd materialiserade vyer i Databricks SQL.