Binär fil
Databricks Runtime stöder datakällan för binära filer , som läser binära filer och konverterar varje fil till en enda post som innehåller filens råinnehåll och metadata. Datakällan för binära filer skapar en DataFrame med följande kolumner och eventuellt partitionskolumner:
-
path (StringType): Sökvägen till filen. -
modificationTime (TimestampType): Ändringstiden för filen. I vissa Hadoop FileSystem-implementeringar kan den här parametern vara otillgänglig och värdet anges till ett standardvärde. -
length (LongType): Längden på filen i byte. -
content (BinaryType): Innehållet i filen.
Om du vill läsa binära filer anger du datakällan format som binaryFile.
Bilder
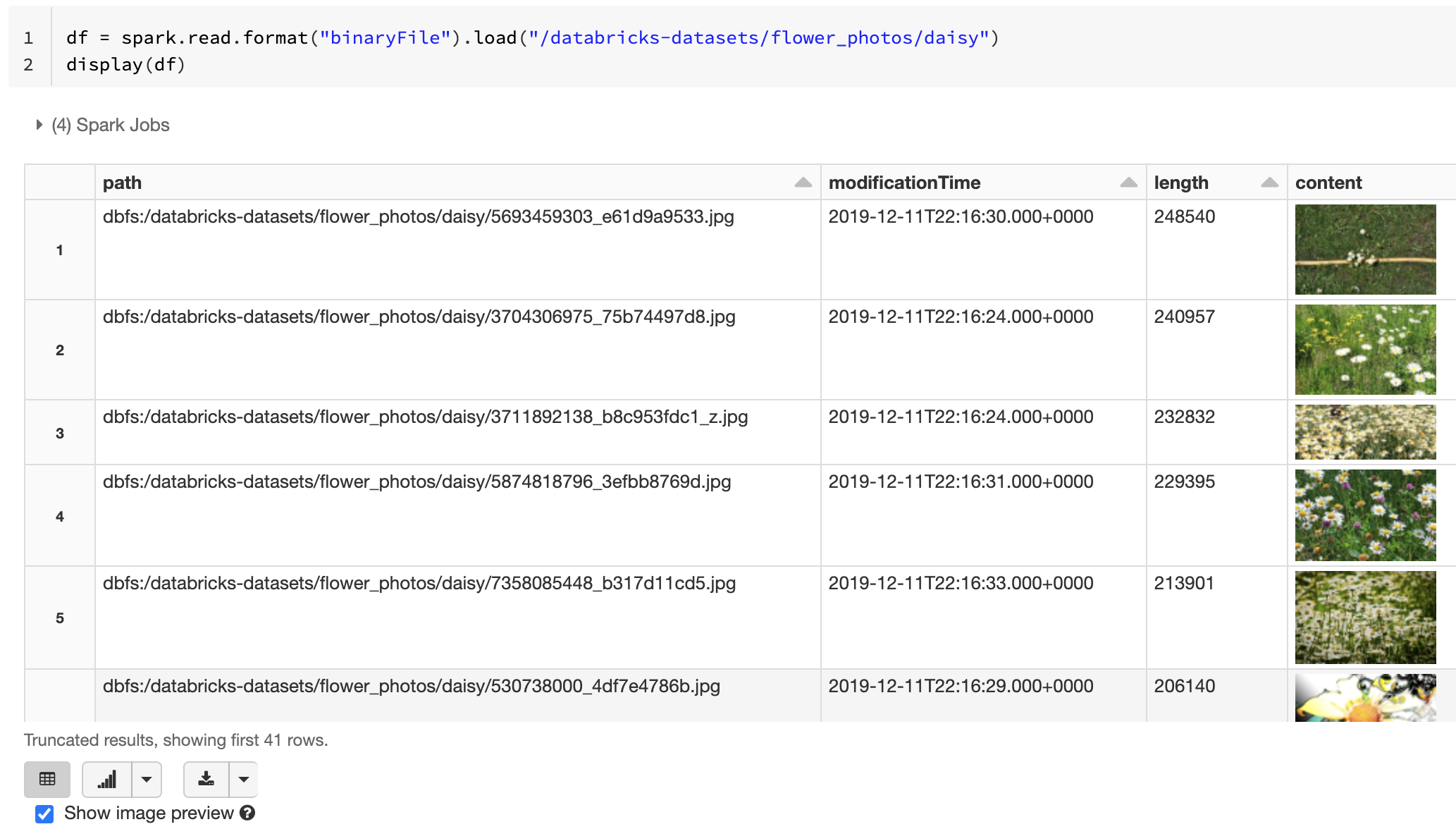
Databricks rekommenderar att du använder datakällan för binära filer för att läsa in bilddata.
Funktionen Databricks display stöder visning av bilddata som läses in med hjälp av den binära datakällan.
Om alla inlästa filer har ett filnamn med ett bildtillägg aktiveras förhandsgranskning automatiskt:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
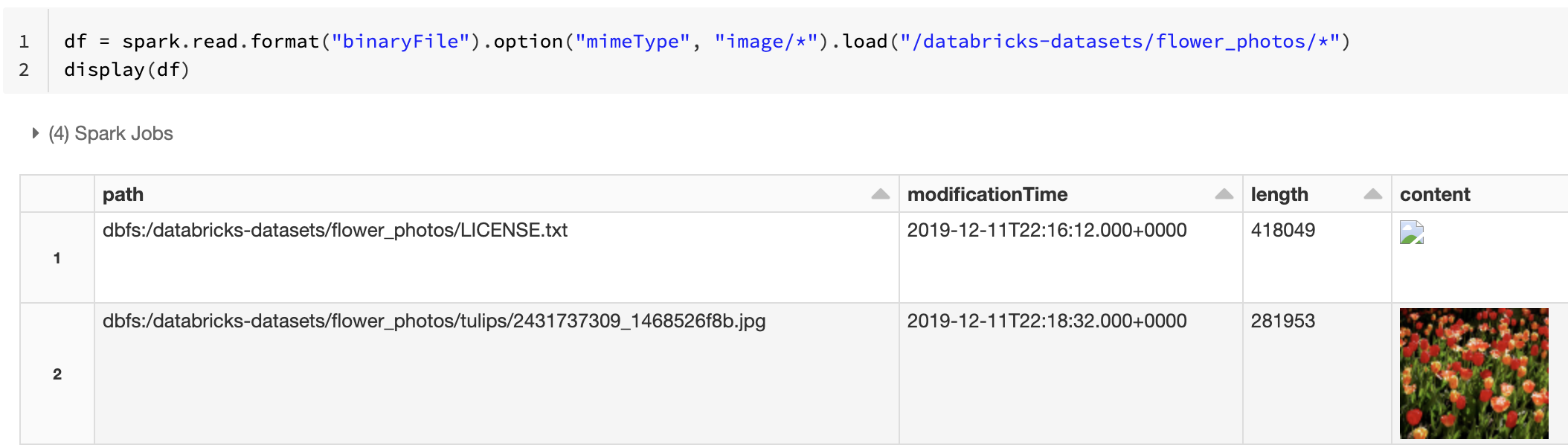
Du kan också framtvinga funktionen för förhandsgranskning av bilder med hjälp mimeType av alternativet med ett strängvärde "image/*" för att kommentera den binära kolumnen. Bilder avkodas baserat på deras formatinformation i det binära innehållet. Avbildningstyper som stöds är bmp, gif, jpegoch png. Filer som inte stöds visas som en bruten bildikon.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Se Referenslösning för bildprogram för det rekommenderade arbetsflödet för att hantera bilddata.
Alternativ
Om du vill läsa in filer med sökvägar som matchar ett angivet globmönster samtidigt som du behåller beteendet för partitionsidentifiering kan du använda alternativet pathGlobFilter . Följande kod läser alla JPG-filer från indatakatalogen med partitionsidentifiering:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Om du vill ignorera partitionsidentifiering och rekursivt söka efter filer under indatakatalogen använder du alternativet recursiveFileLookup . Det här alternativet söker igenom kapslade kataloger även om deras namn inte följer ett namngivningsschema för partitioner som date=2019-07-01.
Följande kod läser alla JPG-filer rekursivt från indatakatalogen och ignorerar partitionsidentifiering:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Liknande API:er finns för Scala, Java och R.
Kommentar
För att förbättra läsprestanda när du läser in data igen rekommenderar Azure Databricks att du sparar data som lästs in från binära filer med hjälp av Delta-tabeller:
df.write.save("<path-to-table>")