Adaptiv frågekörning
Adaptiv frågekörning (AQE) är en omoptimering av frågor som sker under frågekörningen.
Motivationen för omoptimering av körning är att Azure Databricks har den mest aktuella korrekta statistiken i slutet av ett shuffle- och broadcast-utbyte (kallas för ett frågesteg i AQE). Därför kan Azure Databricks välja en bättre fysisk strategi, välja en optimal partitionsstorlek och nummer efter shuffle eller göra optimeringar som tidigare krävde tips, till exempel skev kopplingshantering.
Detta kan vara mycket användbart när statistikinsamlingen inte är aktiverad eller när statistiken är inaktuell. Det är också användbart på platser där statiskt härledd statistik är felaktig, till exempel mitt i en komplicerad fråga eller efter förekomsten av datasnedvridning.
Funktioner
AQE är aktiverat som standard. Den har 4 huvudfunktioner:
- Ändrar sorteringskoppling dynamiskt till sändningshashkoppling.
- Sammanfogar partitioner dynamiskt (kombinera små partitioner i partitioner med rimlig storlek) efter shuffle-utbyte. Mycket små uppgifter har sämre I/O-dataflöde och tenderar att drabbas mer av schemaläggning av omkostnader och omkostnader för aktivitetskonfiguration. Genom att kombinera små uppgifter sparas resurser och klustrets dataflöde förbättras.
- Hanterar dynamiskt skevhet i sorteringskoppling och shuffle-hashkoppling genom att dela upp (och replikera vid behov) skeva uppgifter i ungefär lika stora uppgifter.
- Identifierar och sprider tomma relationer dynamiskt.
App
AQE gäller för alla frågor som är:
- Icke-direktuppspelning
- Innehåller minst ett utbyte (vanligtvis när det finns en koppling, aggregering eller ett fönster), en underfråga eller båda.
Alla AQE-tillämpade frågor är inte nödvändigtvis omoptimerade. Omoptimeringen kanske eller kanske inte kommer med en annan frågeplan än den statiskt kompilerade. Information om huruvida en frågas plan har ändrats av AQE finns i följande avsnitt, Frågeplaner.
Frågeplaner
I det här avsnittet beskrivs hur du kan undersöka frågeplaner på olika sätt.
I detta avsnitt:
Spark-användargränssnitt
AdaptiveSparkPlan nod
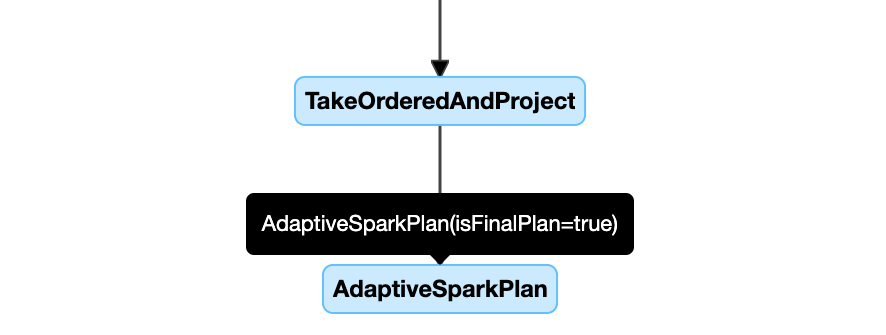
AQE-tillämpade frågor innehåller en eller flera AdaptiveSparkPlan noder, vanligtvis som rotnod för varje huvudfråga eller underfråga.
Innan frågan körs eller när den körs isFinalPlan visas flaggan för motsvarande AdaptiveSparkPlan nod som false. När frågekörningen isFinalPlan har slutförts ändras flaggan till true.
Utvecklande plan
Frågeplansdiagrammet utvecklas när körningen fortskrider och återspeglar den senaste planen som körs. Noder som redan har körts (där mått är tillgängliga) ändras inte, men de som inte har ändrats över tid till följd av omoptimeringar.
Följande är ett exempel på ett frågeplansdiagram:
DataFrame.explain()
AdaptiveSparkPlan nod
AQE-tillämpade frågor innehåller en eller flera AdaptiveSparkPlan noder, vanligtvis som rotnod för varje huvudfråga eller underfråga. Innan frågan körs eller när den isFinalPlan körs visas flaggan för motsvarande AdaptiveSparkPlan nod som false. När frågekörningen isFinalPlan är klar ändras flaggan till true.
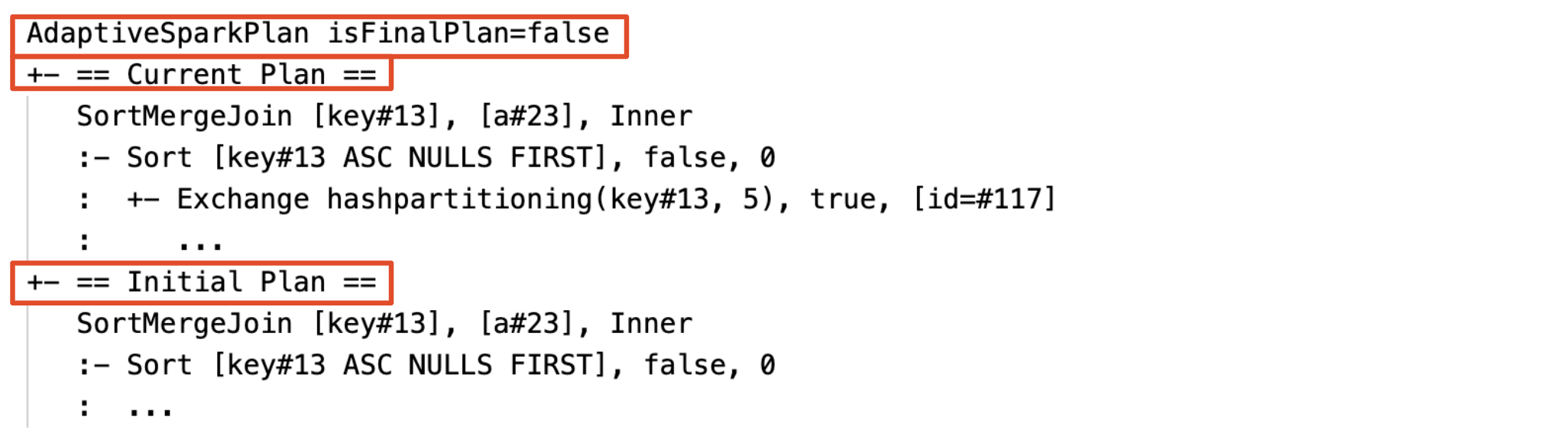
Aktuell och inledande plan
Under varje AdaptiveSparkPlan nod finns både den ursprungliga planen (planen innan du tillämpar AQE-optimeringar) och den aktuella eller den slutliga planen, beroende på om körningen har slutförts. Den aktuella planen utvecklas när körningen fortskrider.
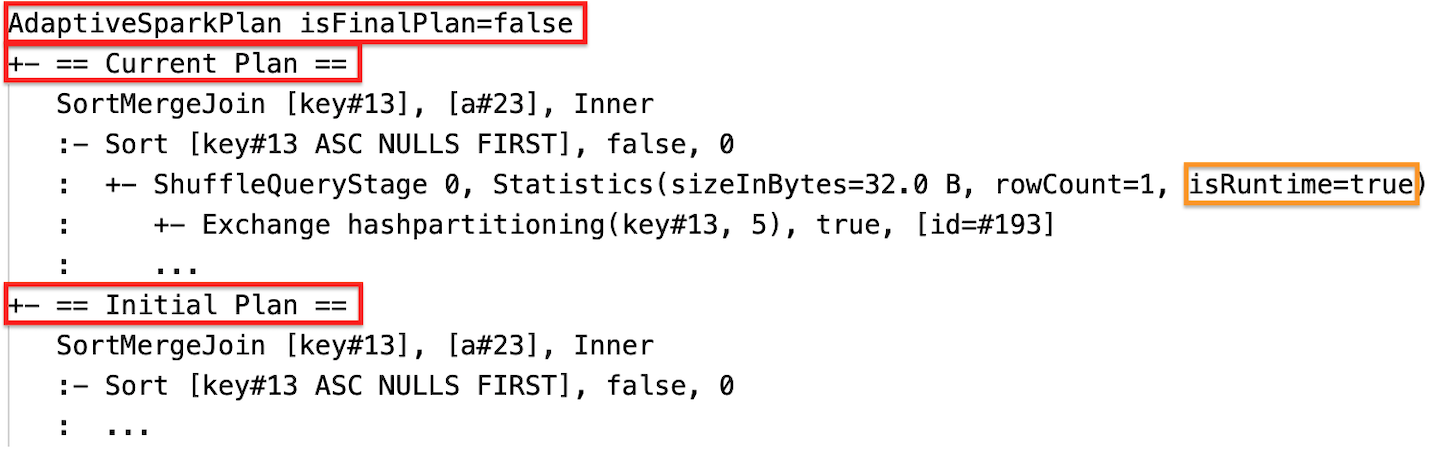
Körningsstatistik
Varje blandnings- och sändningssteg innehåller datastatistik.
Innan fasen körs eller när fasen körs kompileras statistikens tidsuppskattningar och flaggan isRuntime är false, till exempel: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
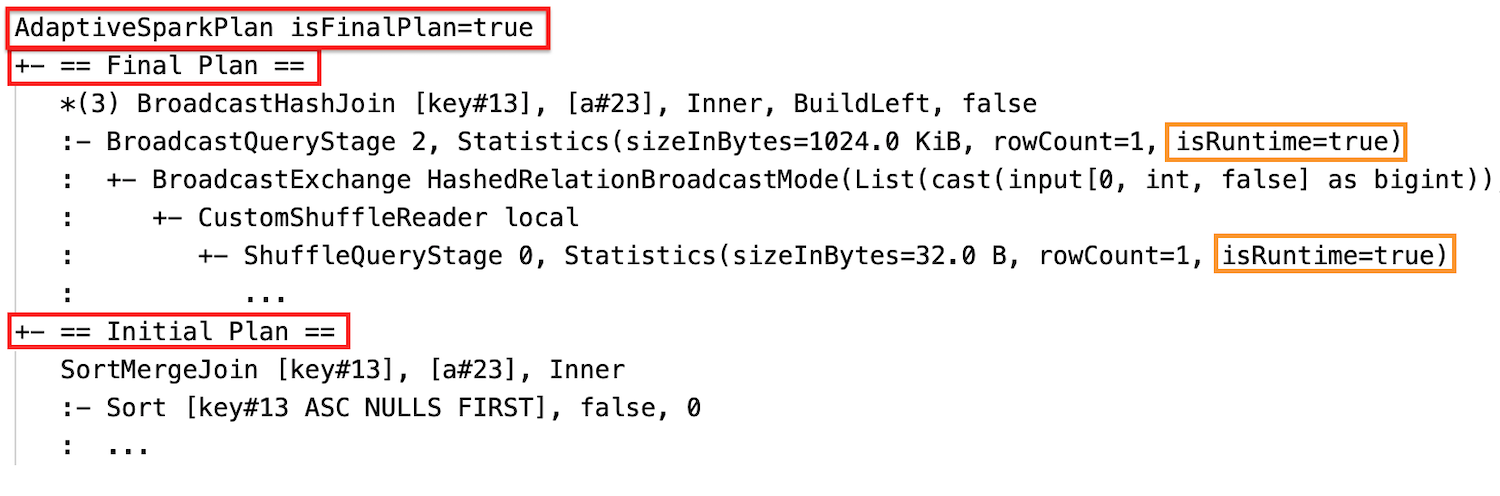
När faskörningen är klar är statistiken de som samlas in vid körning och flaggan isRuntime blir true, till exempel: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Följande är ett DataFrame.explain exempel:
Före körningen
Under körningen
Efter körningen
SQL EXPLAIN
AdaptiveSparkPlan nod
AQE-tillämpade frågor innehåller en eller flera AdaptiveSparkPlan-noder, vanligtvis som rotnod för varje huvudfråga eller underfråga.
Ingen aktuell plan
Eftersom SQL EXPLAIN frågan inte körs är den aktuella planen alltid densamma som den ursprungliga planen och återspeglar inte vad som så småningom skulle köras av AQE.
Följande är ett SQL-förklaringsexempel:

Effektivitet
Frågeplanen ändras om en eller flera AQE-optimeringar börjar gälla. Effekten av dessa AQE-optimeringar visas av skillnaden mellan de aktuella och slutliga planerna och den ursprungliga planen och specifika plannoder i de aktuella och slutliga planerna.
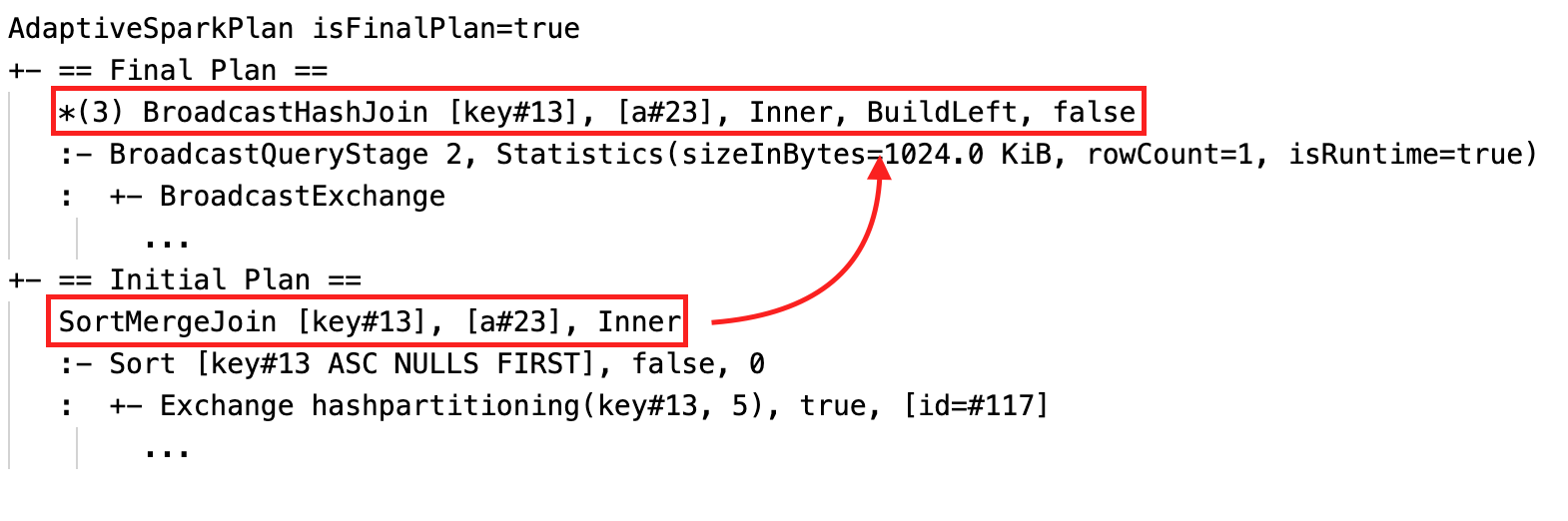
Ändra sorteringskoppling dynamiskt till sändningshashkoppling: olika fysiska kopplingsnoder mellan den aktuella/slutliga planen och den ursprungliga planen
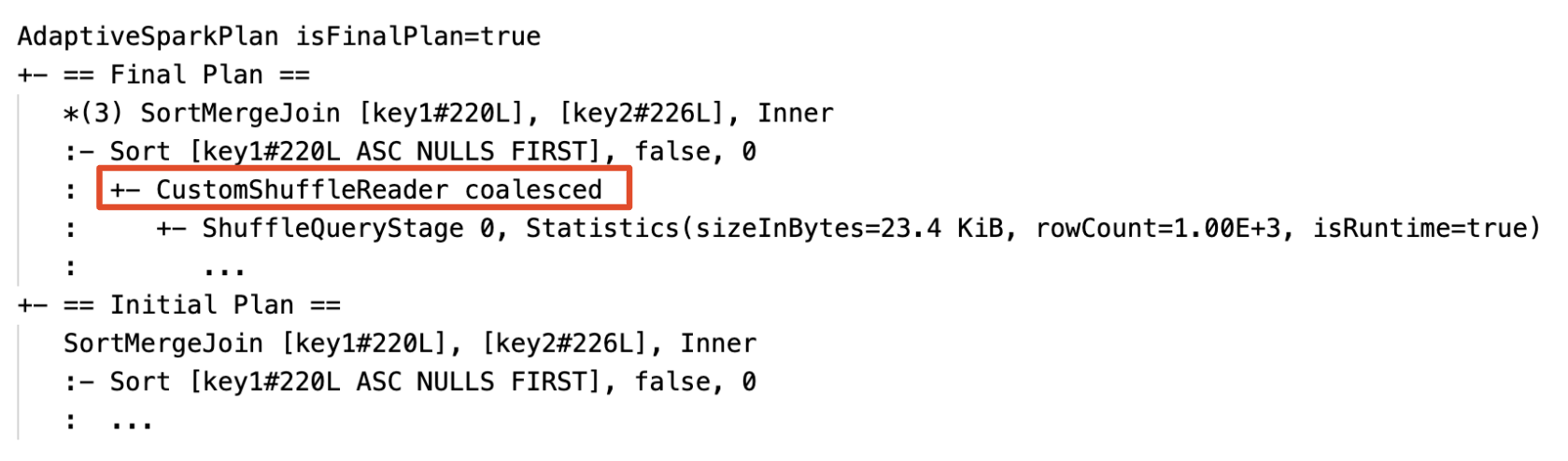
Sammansejsa partitioner dynamiskt: nod
CustomShuffleReadermed egenskapCoalesced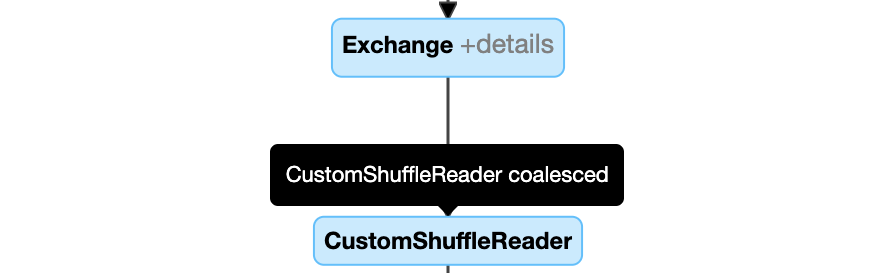
Hantera skev koppling dynamiskt: nod
SortMergeJoinmed fältetisSkewsom sant.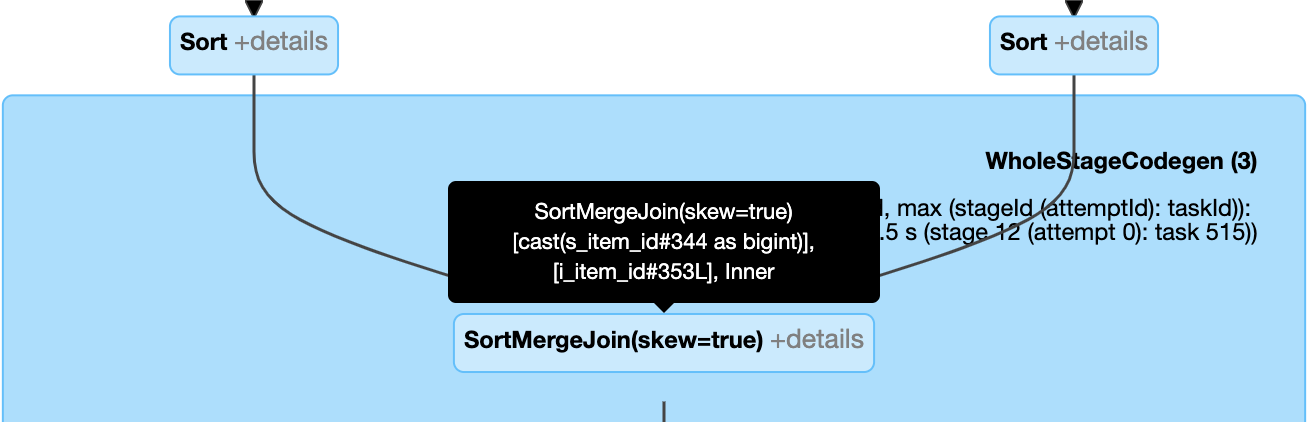
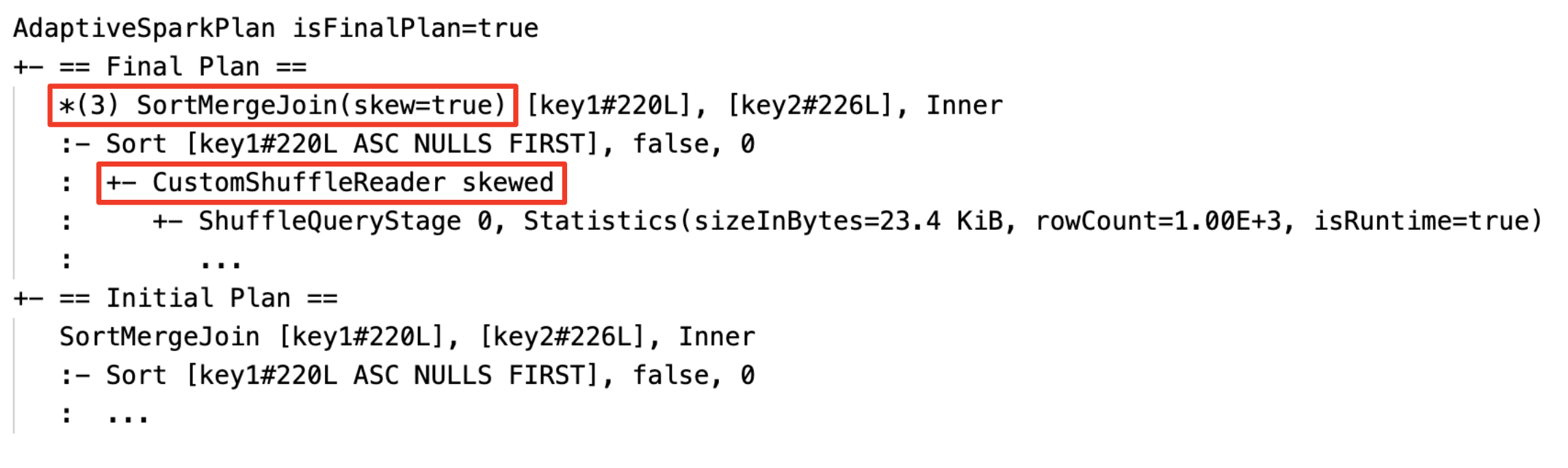
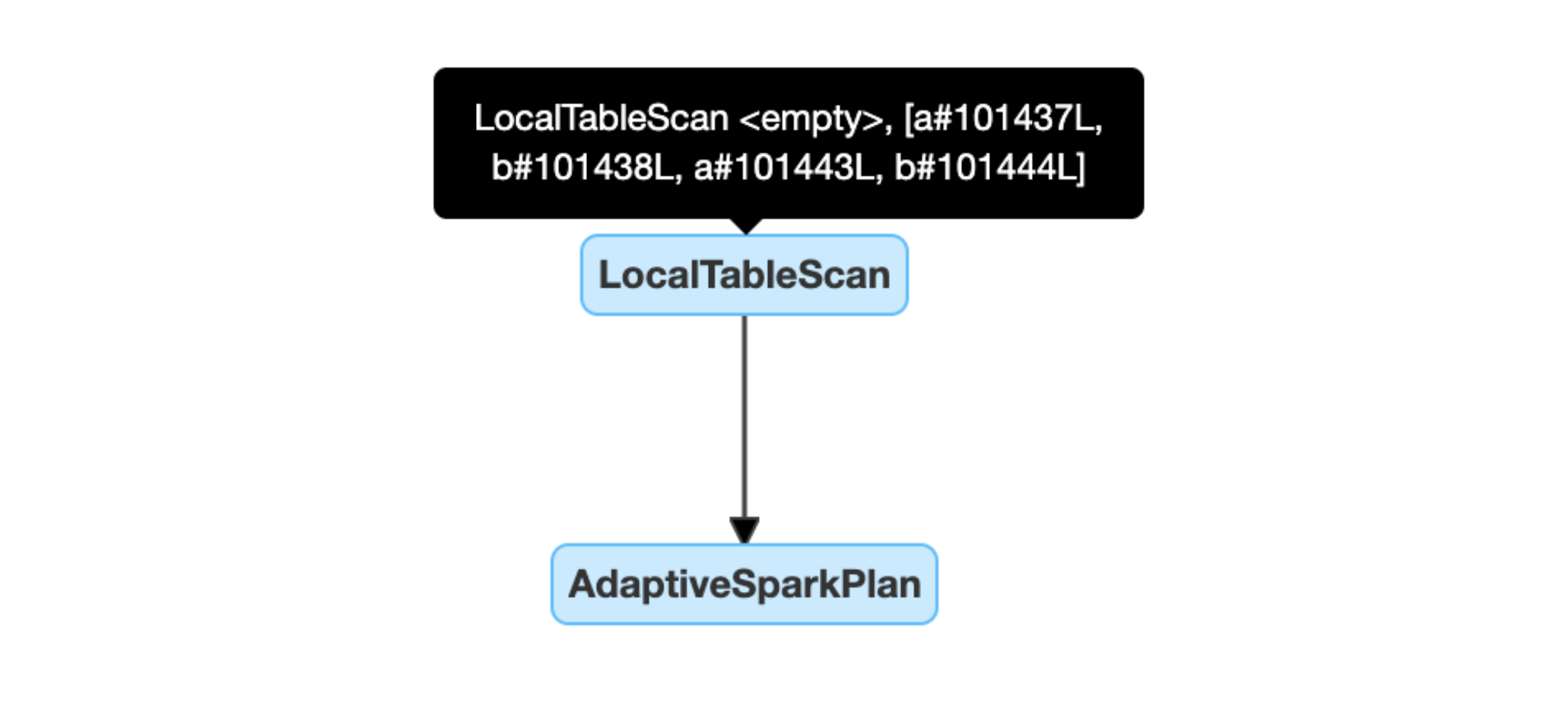
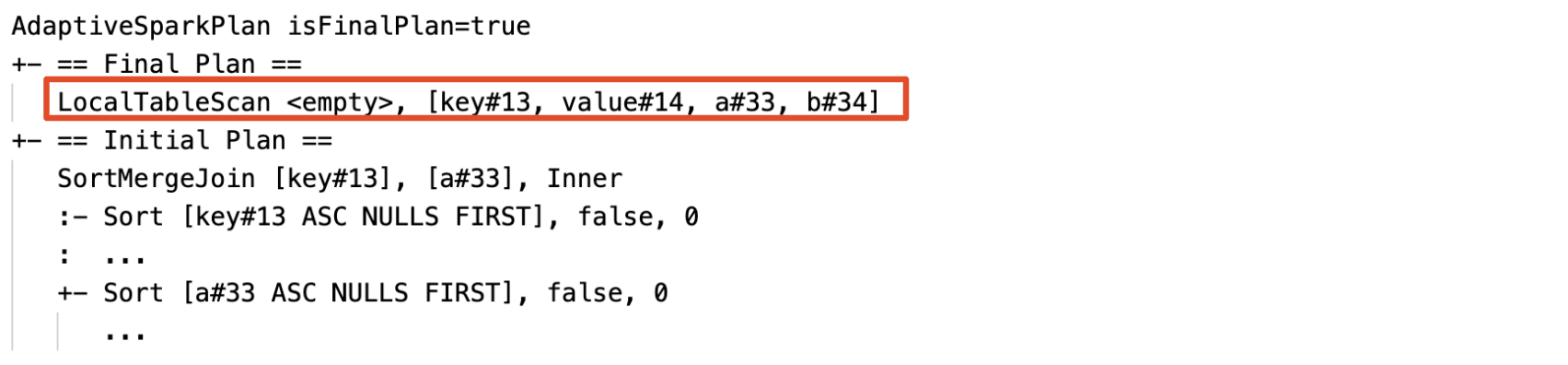
Identifiera och sprida tomma relationer dynamiskt: en del av (eller hela) planen ersätts av noden LocalTableScan med relationsfältet som tomt.
Konfiguration
I detta avsnitt:
- Aktivera och inaktivera anpassningsbar frågekörning
- Aktivera automatisk optimerad blandning
- Ändra sorteringskoppling dynamiskt till sändningshashkoppling
- Sammansejsa partitioner dynamiskt
- Hantera skev koppling dynamiskt
- Identifiera och sprida tomma relationer dynamiskt
Aktivera och inaktivera anpassningsbar frågekörning
| Property |
|---|
| spark.databricks.optimizer.adaptive.enabled Typ: BooleanOm du vill aktivera eller inaktivera anpassningsbar frågekörning. Standardvärde: true |
Aktivera automatisk optimerad blandning
| Property |
|---|
| spark.sql.shuffle.partitions Typ: IntegerStandardantalet partitioner som ska användas när data blandas för kopplingar eller sammansättningar. Om du anger värdet auto aktiveras automatiskt optimerad blandning, vilket automatiskt avgör det här talet baserat på frågeplanen och datastorleken för frågeindata.Obs! För Strukturerad direktuppspelning kan den här konfigurationen inte ändras mellan omstarter av frågor från samma kontrollpunktsplats. Standardvärde: 200 |
Ändra sorteringskoppling dynamiskt till sändningshashkoppling
| Property |
|---|
| spark.databricks.adaptive.autoBroadcastJoinThreshold Typ: Byte StringTröskelvärdet för att utlösa växling till sändningsanslutning vid körning. Standardvärde: 30MB |
Sammansejsa partitioner dynamiskt
| Property |
|---|
| spark.sql.adaptive.coalescePartitions.enabled Typ: BooleanOm du vill aktivera eller inaktivera partitionskolning. Standardvärde: true |
| spark.sql.adaptive.advisoryPartitionSizeInBytes Typ: Byte StringMålstorleken efter sammankoppling. De sammansejsade partitionsstorlekarna kommer att vara nära men inte större än den här målstorleken. Standardvärde: 64MB |
| spark.sql.adaptive.coalescePartitions.minPartitionSize Typ: Byte StringDen minsta storleken på partitioner efter sammankoppling. De sammansropade partitionsstorlekarna är inte mindre än den här storleken. Standardvärde: 1MB |
| spark.sql.adaptive.coalescePartitions.minPartitionNum Typ: IntegerDet minsta antalet partitioner efter sammankoppling. Rekommenderas inte eftersom inställningen uttryckligen åsidosätter spark.sql.adaptive.coalescePartitions.minPartitionSize.Standardvärde: 2x nej. av klusterkärnor |
Hantera skev koppling dynamiskt
| Property |
|---|
| spark.sql.adaptive.skewJoin.enabled Typ: BooleanOm du vill aktivera eller inaktivera snedkopplingshantering. Standardvärde: true |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor Typ: IntegerEn faktor som när den multipliceras med medianpartitionsstorleken bidrar till att avgöra om en partition är skev. Standardvärde: 5 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Typ: Byte StringEtt tröskelvärde som bidrar till att avgöra om en partition är skev. Standardvärde: 256MB |
En partition anses skev när både (partition size > skewedPartitionFactor * median partition size) och (partition size > skewedPartitionThresholdInBytes) är true.
Identifiera och sprida tomma relationer dynamiskt
| Property |
|---|
| spark.databricks.adaptive.emptyRelationPropagation.enabled Typ: BooleanOm du vill aktivera eller inaktivera dynamisk tom relationsspridning. Standardvärde: true |
Vanliga frågor (FAQ)
I detta avsnitt:
- Varför sände inte AQE en liten kopplingstabell?
- Ska jag fortfarande använda en strategitips för sändningskoppling med AQE aktiverat?
- Vad är skillnaden mellan snedkopplingstips och optimering av AQE-skev koppling? Vilken ska jag använda?
- Varför justerade inte AQE min kopplingsordning automatiskt?
- Varför identifierade inte AQE min datasnedvridning?
Varför sände inte AQE en liten kopplingstabell?
Om storleken på den relation som förväntas sändas faller under det här tröskelvärdet men fortfarande inte sänds:
- Kontrollera kopplingstypen. Sändning stöds inte för vissa kopplingstyper, till exempel kan den vänstra relationen för en
LEFT OUTER JOINinte sändas. - Det kan också vara så att relationen innehåller många tomma partitioner, i vilket fall majoriteten av uppgifterna kan slutföras snabbt med sorteringskoppling eller så kan den optimeras med snedkopplingshantering. AQE undviker att ändra sådana sorteringskopplingar till sändningshashkopplingar om procentandelen icke-tomma partitioner är lägre än
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
Ska jag fortfarande använda en strategitips för sändningskoppling med AQE aktiverat?
Ja. En statiskt planerad sändningskoppling är vanligtvis mer högpresterande än en dynamiskt planerad sändningskoppling av AQE eftersom AQE kanske inte växlar till sändningskoppling förrän efter att ha utfört shuffle för båda sidor av kopplingen (då de faktiska relationsstorlekarna erhålls). Så att använda ett sändningstips kan fortfarande vara ett bra val om du känner till din fråga väl. AQE respekterar frågetips på samma sätt som statisk optimering gör, men kan fortfarande tillämpa dynamiska optimeringar som inte påverkas av tipsen.
Vad är skillnaden mellan snedkopplingstips och optimering av AQE-skev koppling? Vilken ska jag använda?
Vi rekommenderar att du förlitar dig på AQE-skev kopplingshantering i stället för att använda snedkopplingstipset, eftersom AQE-skev koppling är helt automatisk och i allmänhet presterar bättre än ledtrådens motsvarighet.
Varför justerade inte AQE min kopplingsordning automatiskt?
Dynamisk kopplingsordning är inte en del av AQE.
Varför identifierade inte AQE min datasnedvridning?
Det finns två storleksvillkor som måste uppfyllas för att AQE ska kunna identifiera en partition som en skev partition:
- Partitionsstorleken
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytesär större än (standardvärdet 256 MB) - Partitionsstorleken är större än medianstorleken för alla partitioner gånger den skeva partitionsfaktorn
spark.sql.adaptive.skewJoin.skewedPartitionFactor(standard 5)
Dessutom är stödet för snedställningshantering begränsat för vissa kopplingstyper, till exempel i LEFT OUTER JOIN, kan endast skevhet på vänster sida optimeras.
Äldre
Termen "Adaptive Execution" har funnits sedan Spark 1.6, men den nya AQE i Spark 3.0 skiljer sig i grunden. När det gäller funktioner gör Spark 1.6 bara delen "dynamiskt sammanlänkade partitioner". När det gäller teknisk arkitektur är den nya AQE ett ramverk för dynamisk planering och omplanering av frågor baserat på körningsstatistik, som stöder en mängd olika optimeringar, till exempel de som vi har beskrivit i den här artikeln och kan utökas för att möjliggöra fler potentiella optimeringar.