Visa träningsresultat med MLflow-körningar
Den här artikeln beskriver hur du använder MLflow-körningar för att visa och analysera resultatet av ett modellträningsexperiment och hur du hanterar och organiserar körningar. Mer information om MLflow-experiment finns i Organisera träningskörningar med MLflow-experiment.
En MLflow-körning motsvarar en enda körning av modellkod. Varje körning registrerar information såsom notebook-filen som startade körningen, eventuella modeller som skapats av körningen, modellparametrar och mått som sparats som nyckel/värde-par, taggar för körningsmetadata samt eventuella artefakter eller resultatfiler som skapats av körningen.
Alla MLflow-körningar loggas till det aktiva experimentet. Om du inte uttryckligen har angett ett experiment som det aktiva experimentet, loggas körningarna till notebook-experimentet.
Visa körningsinformation
Du kan komma åt körningens resultat från experimentets detaljsida eller direkt från anteckningsboken som skapade körningen.
På sidan med experimentdetaljer klickar du på körningsnamnet i körningstabellen.
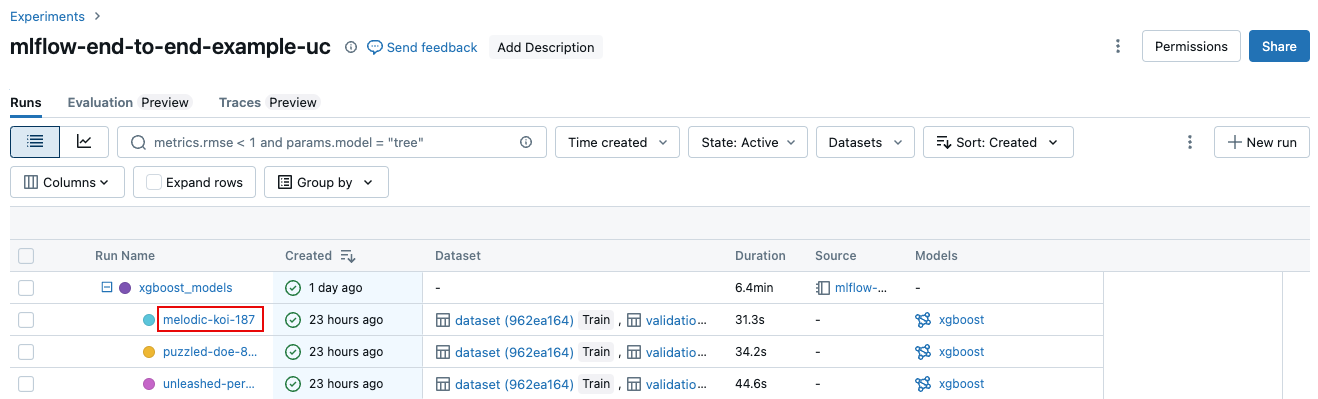
Från anteckningsboken klickar du på körningsnamnet i sidofältet Experimentkörningar.

Körskärmen visar körnings-ID, parametrarna som används för körningen, resultatmåtten för körningen samt detaljer om körningen, inklusive en länk till källanteckningsboken. Artefakter som sparats från körningen är tillgängliga på fliken Artefakter.
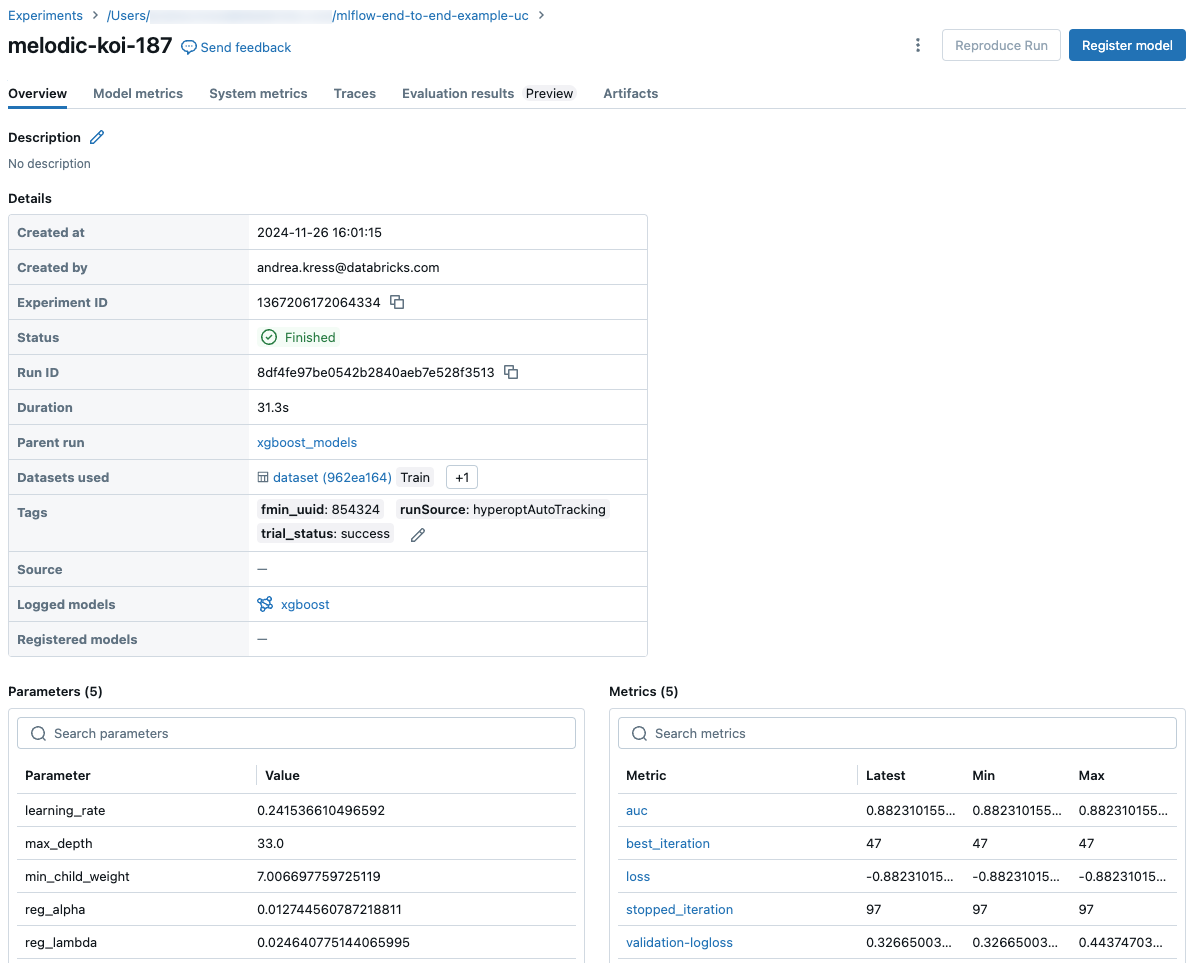
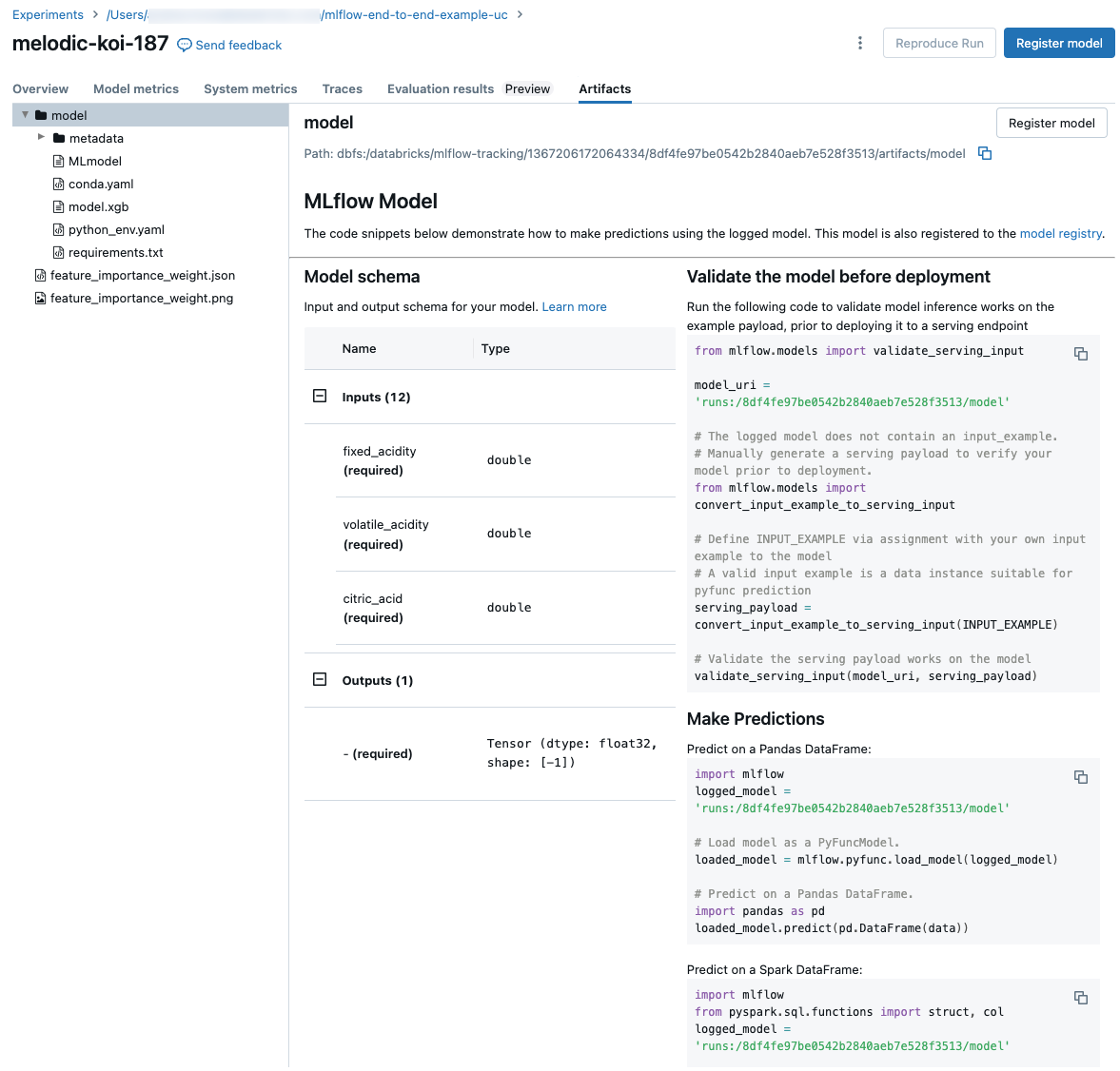
Kodfragment för förutsägelse
Om du loggar en modell från en körning visas modellen på fliken Artifacts, tillsammans med kodfragment som illustrerar hur du läser in och använder modellen för att göra förutsägelser på Spark- och Pandas DataFrames.
Visa anteckningsbok som används vid en körning
Så här visar du versionen av notebook-filen som skapade en körning:
- På sidan med experimentinformation klickar du på länken i kolumnen Source.
- På körningssidan klickar du på länken bredvid Källa.
- I sidofältet Experimentkörningar i anteckningsboken klickar du på anteckningsboksikonen
 i rutan för experimentkörningen.
i rutan för experimentkörningen.
Den version av anteckningsboken som är associerad med körningen visas i huvudfönstret med en markeringsrad som visar datum och tid för körningen.
Lägga till en tagg i en körning
Taggar är nyckel/värde-par som du kan skapa och använda senare för att söka efter körningar.
I tabellen Detaljer på körsidan klickar du på Lägg till bredvid Taggar.

Dialogrutan Lägg till/redigera taggar öppnas. I fältet Key anger du ett namn på nyckeln och klickar på Lägg till tagg.
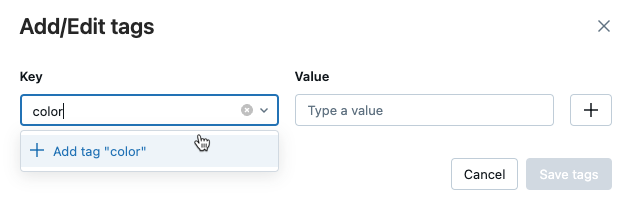
I fältet Värde anger du värdet för taggen.
Klicka på plustecknet för att spara nyckel/värde-paret som du nyss angav.
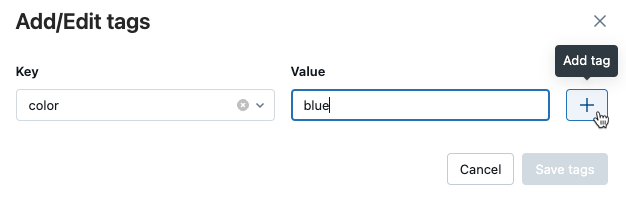
Om du vill lägga till ytterligare taggar upprepar du steg 2 till och med 4.
När du är klar klickar du på Spara taggar.
Redigera eller ta bort en tagg för en körning
I tabellen Detaljer på körsidanklickar du på
bredvid befintliga taggar.

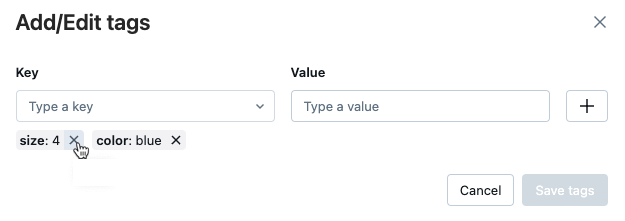
Dialogrutan Lägg till/redigera taggar öppnas.
Om du vill ta bort en tagg klickar du på X på taggen.
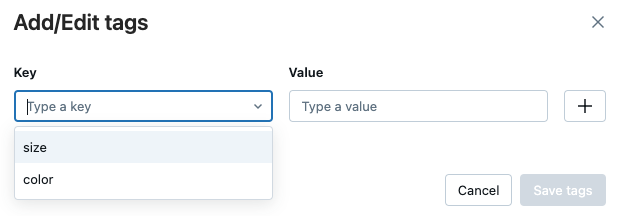
Om du vill redigera en tagg väljer du nyckeln i den nedrullningsbara menyn och redigerar värdet i fältet Värde. Klicka på plustecknet för att spara ändringen.
När du är klar klickar du på Spara taggar.
Återskapa programvarumiljön för en körning
Du kan återskapa den exakta programvarumiljön för körningen genom att klicka på Återskapa körning längst upp till höger på körningssidan. Följande dialogruta visas:
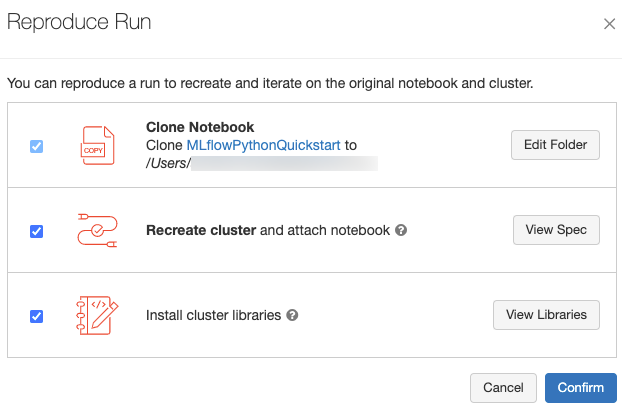
När du klickar på Bekräfta med standardinställningarna:
- Anteckningsboken klonas till den plats som visas i dialogrutan.
- Om det ursprungliga klustret fortfarande finns är den klonade notebook-filen kopplad till det ursprungliga klustret och klustret startas.
- Om det ursprungliga klustret inte längre finns skapas och startas ett nytt kluster med samma konfiguration, inklusive alla installerade bibliotek. Anteckningsboken är kopplad till det nya klustret.
Du kan välja en annan plats för den klonade notebook-filen och granska klusterkonfigurationen och installerade bibliotek:
- Om du vill välja en annan mapp för att spara den klonade anteckningsboken klickar du på Redigera mapp.
- Om du vill se klusterspecifikationen klickar du på Visa specifikation. Om du bara vill klona notebook-filen och inte klustret avmarkerar du det här alternativet.
- Om det ursprungliga klustret inte längre finns kan du se biblioteken som är installerade i det ursprungliga klustret genom att klicka på Visa bibliotek. Om det ursprungliga klustret fortfarande finns är det här avsnittet nedtonat.
Byt namn på körning
Om du vill byta namn på en körning klickar du på menyn för kebab ![]() i det övre högra hörnet på körningssidan (bredvid knappen Behörigheter) och väljer Byt namn.
i det övre högra hörnet på körningssidan (bredvid knappen Behörigheter) och väljer Byt namn.
Välj kolumner som ska visas
Om du vill styra kolumnerna som visas i tabellen Körningar på sidan med experimentinformation, klicka på Kolumner och välj från rullgardinsmenyn.
Filterkörningar
Du kan söka efter körningar i tabellen på experimentinformationssidan utifrån parameter- eller metrikvärden. Du kan också söka efter körningar efter tagg.
Om du vill söka efter körningar som matchar ett uttryck som innehåller parameter- och måttvärden anger du en fråga i sökfältet och trycker på Retur. Några exempel på frågesyntax är:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Som standard filtreras måttvärden baserat på det senast loggade värdet. Med
MINellerMAXkan du söka efter körningar baserat på de lägsta respektive högsta måttvärdena. Endast körningar som loggats efter augusti 2024 har minimi- och maximivärden för metriker.Om du vill söka efter körningar efter tagg anger du taggar i formatet:
tags.<key>="<value>". Strängvärden måste omges av citattecken som visas.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Både nycklar och värden kan innehålla blanksteg. Om nyckeln innehåller blanksteg måste du omsluta den i backticks som du ser.
tags.`my custom tag` = "my value"
Du kan också filtrera körningar baserat på deras tillstånd (aktiv eller borttagen), när körningen skapades och vilka datauppsättningar som användes. Gör detta genom att göra dina val från Tid skapad, Stateeller Datauppsättningar rullgardinsmenyer.
Nedladdningskörningar
Du kan ladda ned körningar från sidan Experimentdetaljer på följande sätt:
Klicka på
 för att öppna kebabmenyn.
för att öppna kebabmenyn.
Om du vill ladda ned en fil i CSV-format som innehåller alla körningar som visas (upp till högst 100) väljer du Ladda ned
<n>körningar. MLflow skapar och laddar ned en fil med en körning per rad, som innehåller följande fält för varje körning:Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...Om du vill ladda ned fler än 100 körningar eller vill ladda ned körningar programmatiskt väljer du Ladda ned alla körningar. En dialogruta öppnas som visar ett kodfragment som du kan kopiera eller öppna i en notebook-fil. När du har kört den här koden i en notebook-cell väljer du Ladda ned alla rader från utdata för cellen.
Ta bort körningar
Du kan ta bort körningar från detaljsidan för experimentet genom att följa dessa steg:
- I experimentet väljer du en eller flera processer genom att klicka i kryssrutan till vänster om processen.
- Klicka på Ta bort.
- Om körningen är en överordnad körning bestämmer du om du också vill ta bort underordnade körningar. Det här alternativet är markerat som standard.
- Bekräfta genom att klicka på Ta bort . Borttagna körningar sparas i 30 dagar. Om du vill visa borttagna körningar väljer du Borttagen i fältet Status.
Massborttagningskörningar baserat på skapandetiden
Du kan använda Python för att massradera körningar av ett experiment som skapades före eller vid en UNIX-tidsstämpel.
Med Databricks Runtime 14.1 eller senare kan du anropa API:et mlflow.delete_runs för att ta bort körningar och returnera antalet borttagna körningar.
Följande är de mlflow.delete_runs parametrarna:
-
experiment_id: ID:t för experimentet som innehåller de körningar som ska tas bort. -
max_timestamp_millis: Den maximala tidsstämpeln för skapande i millisekunder sedan UNIX-epoken för att ta bort körningar. Endast körningar som skapats före eller vid den här tidsstämpeln tas bort. -
max_runs:Valfri. Ett positivt heltal som anger det maximala antalet körningar som ska tas bort. Det högsta tillåtna värdet för max_runs är 10000. Om det inte angesmax_runsär standardvärdet 10000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Med Databricks Runtime 13.3 LTS eller tidigare kan du köra följande klientkod i en Azure Databricks Notebook.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Se dokumentationen för API:et för Azure Databricks-experiment för parametrar och returnera värdespecifikationer för borttagning av körningar baserat på skapandetid.
Återställningskörningar
Du kan återställa tidigare borttagna körningar från användargränssnittet på följande sätt:
- På sidan Experiment, välj Borttagen i fältet State så att borttagna körningar visas.
- Markera en eller flera körningar genom att klicka i kryssrutan till vänster om varje körning.
- Klicka på Återställ.
- Bekräfta genom att klicka på Återställ. De återställda körningarna visas nu när du väljer Aktiv i fältet Tillstånd.
Massåterställning sker utifrån tiden för borttagning
Du kan också använda Python för att återställa flera körningar av ett experiment som togs bort vid eller efter en UNIX-tidsstämpel.
Med Databricks Runtime 14.1 eller senare kan du anropa mlflow.restore_runs API för att återställa körningar och returnera antalet återställda körningar.
Följande är de mlflow.restore_runs parametrarna:
-
experiment_id: ID:t för experimentet som innehåller de körningar som ska återställas. -
min_timestamp_millis: Den minsta tidsstämpeln för borttagning i millisekunder sedan UNIX-epoken för återställning av körningar. Endast körningar som tas bort vid eller efter att den här tidsstämpeln har återställts. -
max_runs:Valfri. Ett positivt heltal som anger det maximala antalet körningar som ska återställas. Det högsta tillåtna värdet för max_runs är 10000. Om det inte anges max_runs standardvärdet 10000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Med Databricks Runtime 13.3 LTS eller tidigare kan du köra följande klientkod i en Azure Databricks Notebook.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Se dokumentationen för API:et för Azure Databricks-experiment för parametrar och returvärdespecifikationer för återställning av körningar baserat på borttagningstid.
Jämföra körningar
Du kan jämföra körningar från ett enda experiment eller från flera experiment. Sidan Jämföra körningar visar information om de valda körningarna i tabellformat. Du kan också skapa visualiseringar av körningsresultat och tabeller med körningsinformation, körningsparametrar och mått. Se Jämför MLflow-körningar med hjälp av grafer och diagram.
Tabellerna Parameters och Metrics visar körningsparametrar och mått från alla valda körningar. Kolumnerna i dessa tabeller anges av Körningsdetaljer tabellen direkt ovanför. För enkelhetens skull kan du dölja parametrar och mått som är identiska i alla markerade körningar genom att växla knappen  .
.
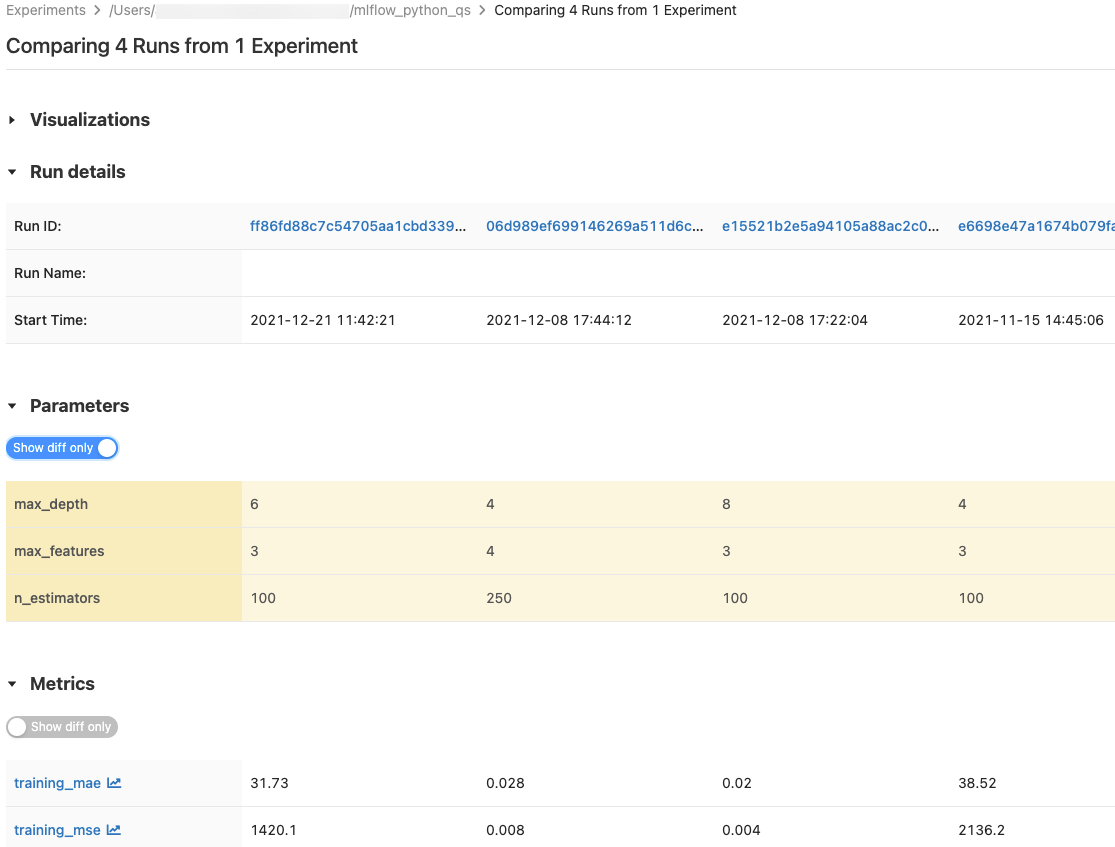
Jämföra körningar från ett enda experiment
- På sidan experimentinformationmarkerar du två eller flera körningar genom att klicka i kryssrutan till vänster om körningen eller markera alla körningar genom att markera kryssrutan överst i kolumnen.
- Klicka på Jämför. Skärmen Jämföra
<N>körningar visas.
Jämföra körningar från flera experiment
- På sidan experimentväljer du de experiment som du vill jämföra genom att klicka i rutan till vänster om experimentnamnet.
- Klicka på Jämför (n) (n är antalet experiment som du har valt). En skärm visas som visar alla körningar från experimenten som du har valt.
- Markera två eller flera körningar genom att klicka i kryssrutan till vänster om körningen eller markera alla körningar genom att markera kryssrutan överst i kolumnen.
- Klicka på Jämför. Skärmen Jämföra
<N>körningar visas.
Kopiera körningar mellan arbetsytor
Om du vill importera eller exportera MLflow-körningar till eller från databricks-arbetsytan kan du använda det communitydrivna öppen källkod projektet MLflow Export-Import.