Prognostisering (serverlös) med AutoML
Viktig
Den här funktionen finns i offentlig förhandsversion.
Den här artikeln visar hur du kör ett serverlöst prognosexperiment med hjälp av mosaic AI Model Training-användargränssnittet.
Mosaic AI Model Training – prognostisering förenklar prognostisering av tidsseriedata genom att automatiskt välja den bästa algoritmen och hyperparametrar, allt medan det körs på fullständigt hanterade beräkningsresurser.
Information om skillnaden mellan serverlös prognostisering och klassisk beräkningsprognos finns i Serverless forecasting vs. classic compute forecasting.
Krav
Träningsdata med en tidsserie column, sparad som Unity Catalogtable.
Om arbetsytan har säker utgående gateway (SEG) aktiverad måste
pypi.orgläggas till i Tillåtna domänerlist. Se Hantera nätverksprinciper för serverlös utgående kontroll.
Skapa ett prognosexperiment med användargränssnittet
Gå till din Azure Databricks-landningssida och klicka på Experiment i sidofältet.
I panelen Prognos rutan selectStart training.
Select Träningsdata från en list av Unity Catalogtables som du kan komma åt.
-
Time column: Selectcolumn som innehåller tidsperioderna för tidsserien.
columns måste vara av typen
timestampellerdate. - Prognosfrekvens: Select tidsenheten som representerar dina indatas frekvens. Till exempel minuter, timmar, dagar, månader. Detta avgör kornigheten för din tidsserie.
- Prognoshorisont: Ange hur många enheter av den valda frekvensen som ska prognostiseras in i framtiden. Tillsammans med prognosfrekvensen definierar detta både tidsenheterna och antalet tidsenheter som ska prognostiseras.
Not
Om du vill använda algoritmen Auto-ARIMA måste tidsserien ha en regelbunden frekvens where intervallet mellan två punkter måste vara detsamma under hela tidsserien. AutoML hanterar saknade tidssteg genom att fylla i de values med föregående värde.
-
Time column: Selectcolumn som innehåller tidsperioderna för tidsserien.
columns måste vara av typen
Select ett förutsägelsemål column som du vill att modellen ska förutsäga.
Du kan även ange en Unity-förutsägelsedatasökväg Catalogtable för att spara prognosresultaten.
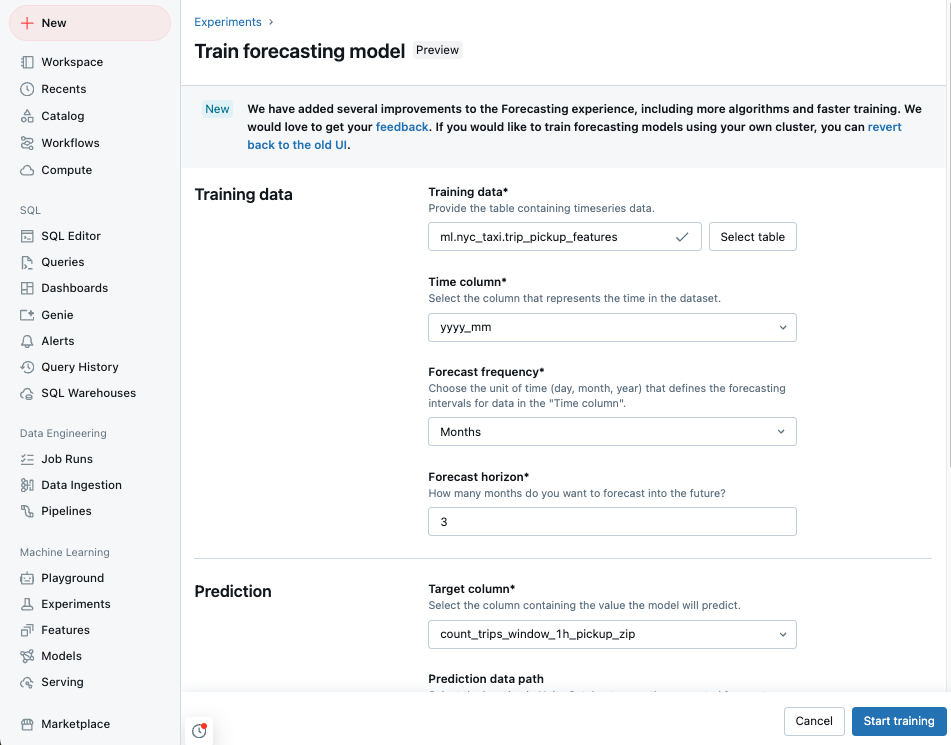
Select en modellregistrering Unity Catalog plats och namn.
Valfritt, setAvancerade alternativ:
- Experimentnamn: Ange ett MLflow-experimentnamn.
- Tidsserier identifiercolumns – För prognostisering av flera serier select de columnsom identifierar den enskilda tidsserien. Databricks grupperar data efter dessa columns som olika tidsserier och tränar en modell för varje serie oberoende av varandra.
- Primärt mått: Välj det primära mått som används för att utvärdera och select den bästa modellen.
- Training Framework: Välj de ramverk som AutoML ska utforska.
- Split column: Selectcolumn som innehåller anpassad datadelning. Values måste vara "träna", "validera", "testa"
- Weight column: Ange den column som ska användas för viktning av tidsserier. Alla prover för en viss tidsserie måste ha samma vikt. Vikten måste ligga inom intervallet [0, 10000].
- Semesterregion: Select semesterregionen som ska användas som samvariat i modellträningen.
- Timeout: Set en maximal varaktighet för AutoML-experimentet.
Kör experimentet och övervaka resultaten
Starta AutoML-experimentet genom att klicka på Starta träning. Från experimentträningssidan kan du göra följande:
- Stoppa experimentet när som helst.
- Övervaka processer.
- Navigera till körningssidan för valfri körning.
Visa resultat eller använd den bästa modellen
När träningen har slutförts lagras förutsägelseresultaten i angivna Delta table och den bästa modellen är registrerad på Unity Catalog.
På sidan experiment väljer du följande steg:
- Select Visa förutsägelser för att se prognosresultatet table.
- Select Batchinferens-notebook för att öppna ett automatiskt genererat notebook för batchinferens med hjälp av den bästa modellen.
- Select Skapa serverslutpunkt för att distribuera den bästa modellen till en modellserverslutpunkt.
Serverlös prognostisering jämfört med klassisk beräkningsprognos
Följande table sammanfattar skillnaderna mellan serverlös prognostisering och prognostisering med klassisk beräkning
| Funktion | Serverlös prognos | Klassisk beräkningsprognos |
|---|---|---|
| Beräkningsinfrastruktur | Azure Databricks hanterar beräkningskonfigurationen och optimerar automatiskt för kostnader och prestanda. | Användarkonfigurerad beräkning |
| Styrelseskick | Modeller och artefakter som är registrerade i Unity Catalog | Användarkonfigurerat filarkiv för arbetsytor |
| Algoritmval | Statistiska modeller plus algoritmen för neuralt nät för djupinlärning DeepAR | Statistiska modeller |
| Integrering av funktionellt datalager | Stöds inte | stöds |
| Automatiskt genererade anteckningsböcker | Anteckningsbok för batchslutsatser | Källkod för alla utvärderingsversioner |
| Enklicksmodell som betjänar distribution | Understödd | Ej stödd |
| Anpassade tränings-/validerings-/testuppdelningar | Understödd | Stöds inte |
| Anpassade vikter för enskilda tidsserier | Understödd | Stöds inte |