MLOps Stacks: modellutvecklingsprocess som kod
Den här artikeln beskriver hur MLOps Stacks gör att du kan implementera utvecklingsprocessen och distributionsprocessen som kod i en källkontrollerad lagringsplats. Den beskriver också fördelarna med modellutveckling på Databricks Data Intelligence-plattformen, en enda plattform som förenar varje steg i modellutvecklings- och distributionsprocessen.
Vad är MLOps Stacks?
Med MLOps Stacks implementeras, sparas och spåras hela modellutvecklingsprocessen som kod på en källkontrollerad lagringsplats. Att automatisera processen på det här sättet underlättar mer repeterbara, förutsägbara och systematiska distributioner och gör det möjligt att integrera med din CI/CD-process. Genom att representera modellutvecklingsprocessen som kod kan du distribuera koden i stället för att distribuera modellen. När koden distribueras automatiseras möjligheten att skapa modellen, vilket gör det mycket enklare att träna om modellen vid behov.
När du skapar ett projekt med MLOps Stacks definierar du komponenterna i ml-utvecklingsprocessen, till exempel notebook-filer som ska användas för funktionsutveckling, utbildning, testning och distribution, pipelines för träning och testning, arbetsytor som ska användas för varje steg och CI/CD-arbetsflöden med GitHub Actions eller Azure DevOps för automatiserad testning och distribution av koden.
Miljön som skapats av MLOps Stacks implementerar MLOps-arbetsflödet som rekommenderas av Databricks. Du kan anpassa koden för att skapa staplar som matchar organisationens processer eller krav.
Hur fungerar MLOps Stacks?
Du använder Databricks CLI för att skapa en MLOps Stack. Stegvisa instruktioner finns i Databricks-tillgångspaket för MLOps Stacks.
När du initierar ett MLOps Stacks-projekt vägleder programvaran dig genom att mata in konfigurationsdetaljerna och sedan skapar en katalog som innehåller de filer som utgör projektet. Den här katalogen, eller stacken, implementerar det MLOps-arbetsflöde för produktion som rekommenderas av Databricks. Komponenterna som visas i diagrammet skapas åt dig och du behöver bara redigera filerna för att lägga till din anpassade kod.
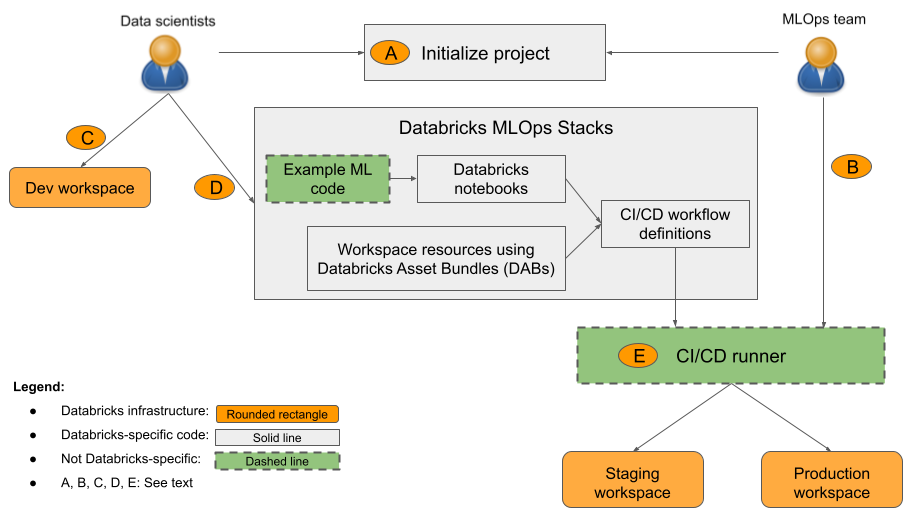
I diagrammet:
-
S: En dataexpert eller ML-tekniker initierar projektet med hjälp av
databricks bundle init mlops-stacks. När du initierar projektet kan du välja att konfigurera ML-kodkomponenterna (används vanligtvis av dataforskare), CI/CD-komponenterna (används vanligtvis av ML-tekniker) eller båda. - B: ML-tekniker konfigurerar Databricks-tjänstens huvudhemligheter för CI/CD.
- C: Dataforskare utvecklar modeller på Databricks eller i sitt lokala system.
- D: Data scientists skapar pull-begäranden för att uppdatera ML-kod.
- E: CI/CD-köraren kör notebook-filer, skapar jobb och utför andra uppgifter i test- och produktionsmiljöerna.
Din organisation kan använda standardstacken eller anpassa den efter behov för att lägga till, ta bort eller ändra komponenter så att de passar organisationens metoder. Mer information finns i GitHub-lagringsplatsens readme .
MLOps Stacks är utformat med en modulär struktur som gör att de olika ML-teamen kan arbeta självständigt i ett projekt samtidigt som de följer metodtips för programvaruutveckling och underhåller CI/CD i produktionsklass. Produktionstekniker konfigurerar ML-infrastruktur som gör det möjligt för dataforskare att utveckla, testa och distribuera ML-pipelines och modeller till produktion.
Som du ser i diagrammet innehåller standard-MLOps Stack följande tre komponenter:
- ML-kod. MLOps Stacks skapar en uppsättning mallar för ett ML-projekt, inklusive notebook-filer för träning, batchinferens och så vidare. Den standardiserade mallen gör det möjligt för dataexperter att komma igång snabbt, förenar projektstrukturen mellan teamen och framtvingar modulariserad kod som är redo för testning.
- ML-resurser som kod. MLOps Stacks definierar resurser som arbetsområden och pipelines för uppgifter som inkluderar träning och batchinferens. Resurser definieras i Databricks-tillgångspaket för att underlätta testning, optimering och versionskontroll för ML-miljön. Du kan till exempel prova en större instanstyp för automatisk modellträning och ändringen spåras automatiskt för framtida referens.
- CI/CD. Du kan använda GitHub Actions eller Azure DevOps för att testa och distribuera ML-kod och resurser, vilket säkerställer att alla produktionsändringar utförs via automatisering och att endast testad kod distribueras till prod.
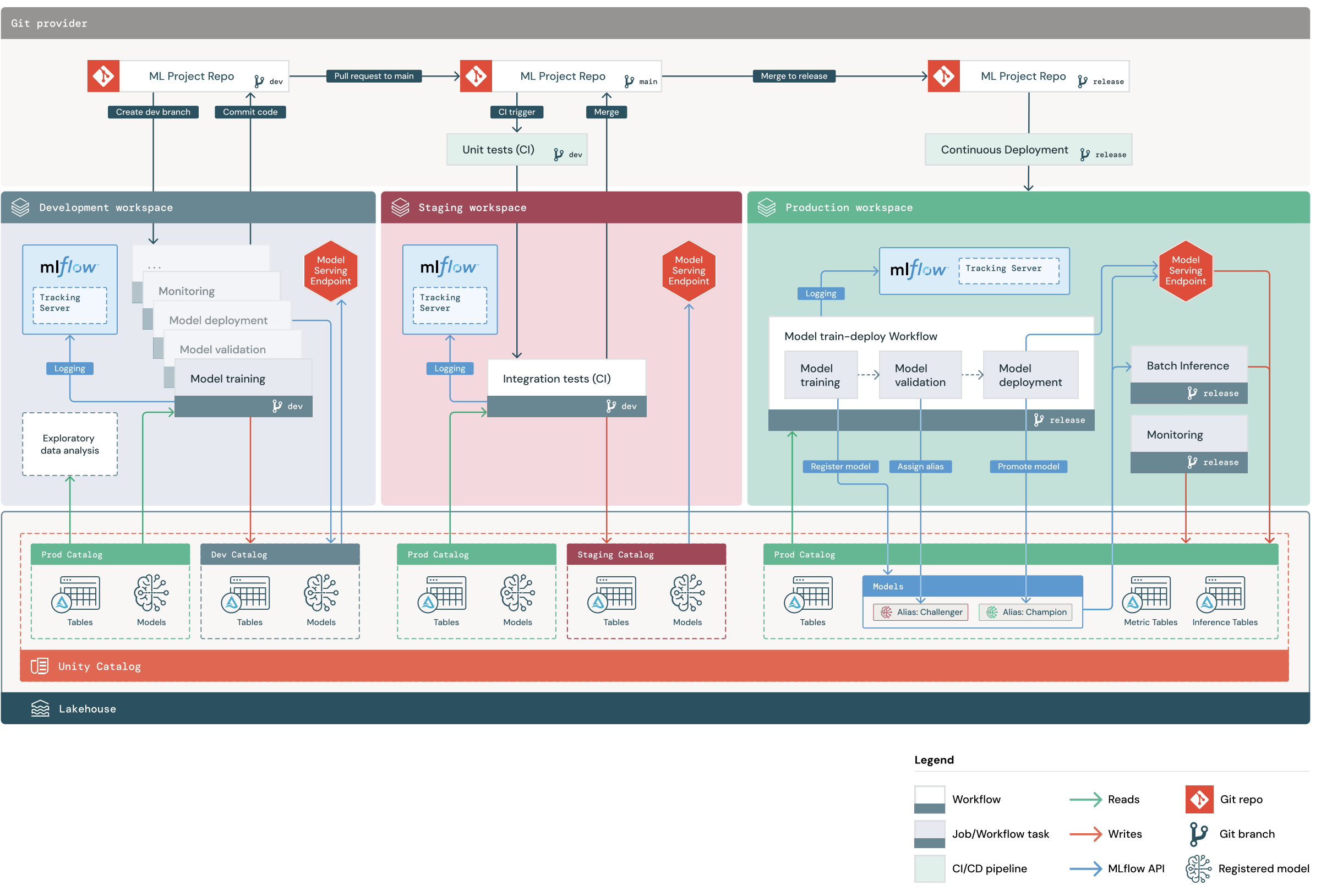
MLOps-projektflöde
Ett MLOps Stacks-standardprojekt innehåller en ML-pipeline med CI/CD-arbetsflöden för att testa och distribuera automatiserade modelltränings- och batchinferensjobb i arbetsytor för utveckling, mellanlagring och produktion av Databricks. MLOps Stacks kan konfigureras så att du kan ändra projektstrukturen så att den uppfyller organisationens processer.
Diagrammet visar den process som implementeras av standard-MLOps Stack. På utvecklingsarbetsytan itererar dataexperter på ML-kod- och filhämtningsbegäranden (PR). PR:er utlöser enhetstester och integrationstester i en isolerad testmiljö för Databricks-arbetsyta. När en PR slås samman med main, uppdateras modelltränings- och batchinferensjobb som körs i stagingmiljön omedelbart för att använda den senaste koden. När du har sammanfogat en pr till main kan du klippa ut en ny versionsgren som en del av den schemalagda lanseringsprocessen och distribuera kodändringarna till produktion.
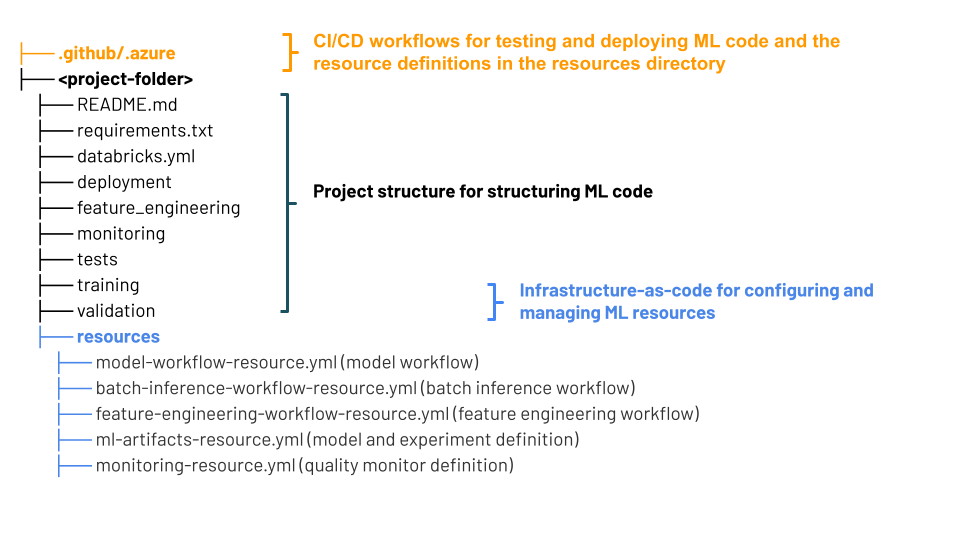
MLOps Stacks-projektstruktur
En MLOps Stack använder Databricks Asset Bundles – en samling källfiler som fungerar som en end-to-end-definition av ett projekt. Dessa källfiler innehåller information om hur de ska testas och distribueras. Genom att samla filerna som ett paket blir det enkelt att samversionera ändringar och använda bästa metoder för mjukvaruutveckling, till exempel källkodskontroll, kodgranskning, testning och CI/CD.
Diagrammet visar de filer som skapats för mlOps-standardstacken. Mer information om filerna som ingår i stacken finns i dokumentationen på GitHub-lagringsplatsen eller Databricks Asset Bundles för MLOps Stacks.
MLOps Stacks-komponenter
En "stack" refererar till den uppsättning verktyg som används i en utvecklingsprocess. Standard-MLOps Stack utnyttjar den enhetliga Databricks-plattformen och använder följande verktyg:
| Komponent | Verktyg i Databricks |
|---|---|
| ML-modellutvecklingskod | Databricks Notebooks, MLflow |
| Funktionsutveckling och hantering | Funktionsutveckling |
| ML-modelllagringsplats | modeller i Unity Catalog |
| Driftsättning av ML-modeller | Mosaic AI-modellhantering |
| Infrastruktur som kod | Databricks-tillgångspaket |
| Orkestrator | Databricks-jobb |
| CI/CD | GitHub Actions, Azure DevOps |
| Prestandaövervakning av data och modeller | Lakehouse-övervakning |
Nästa steg
Kom igång genom att läsa Databricks Asset Bundles for MLOps Stacks eller besök Databricks MLOps Stacks-repositoriet på GitHub.