Hur stöder Databricks CI/CD för maskininlärning?
CI/CD (kontinuerlig integrering och kontinuerlig leverans) avser en automatiserad process för att utveckla, distribuera, övervaka och underhålla dina program. Genom att automatisera skapandet, testningen och distributionen av kod kan utvecklingsteam leverera versioner oftare och mer tillförlitligt än manuella processer som fortfarande är vanliga i många datateknik- och datavetenskapsteam. CI/CD för maskininlärning sammanför tekniker för MLOps, DataOps, ModelOps och DevOps.
Den här artikeln beskriver hur Databricks stöder CI/CD för maskininlärningslösningar. I maskininlärningsprogram är CI/CD viktigt inte bara för kodtillgångar, utan tillämpas även på datapipelines, inklusive både indata och de resultat som genereras av modellen.
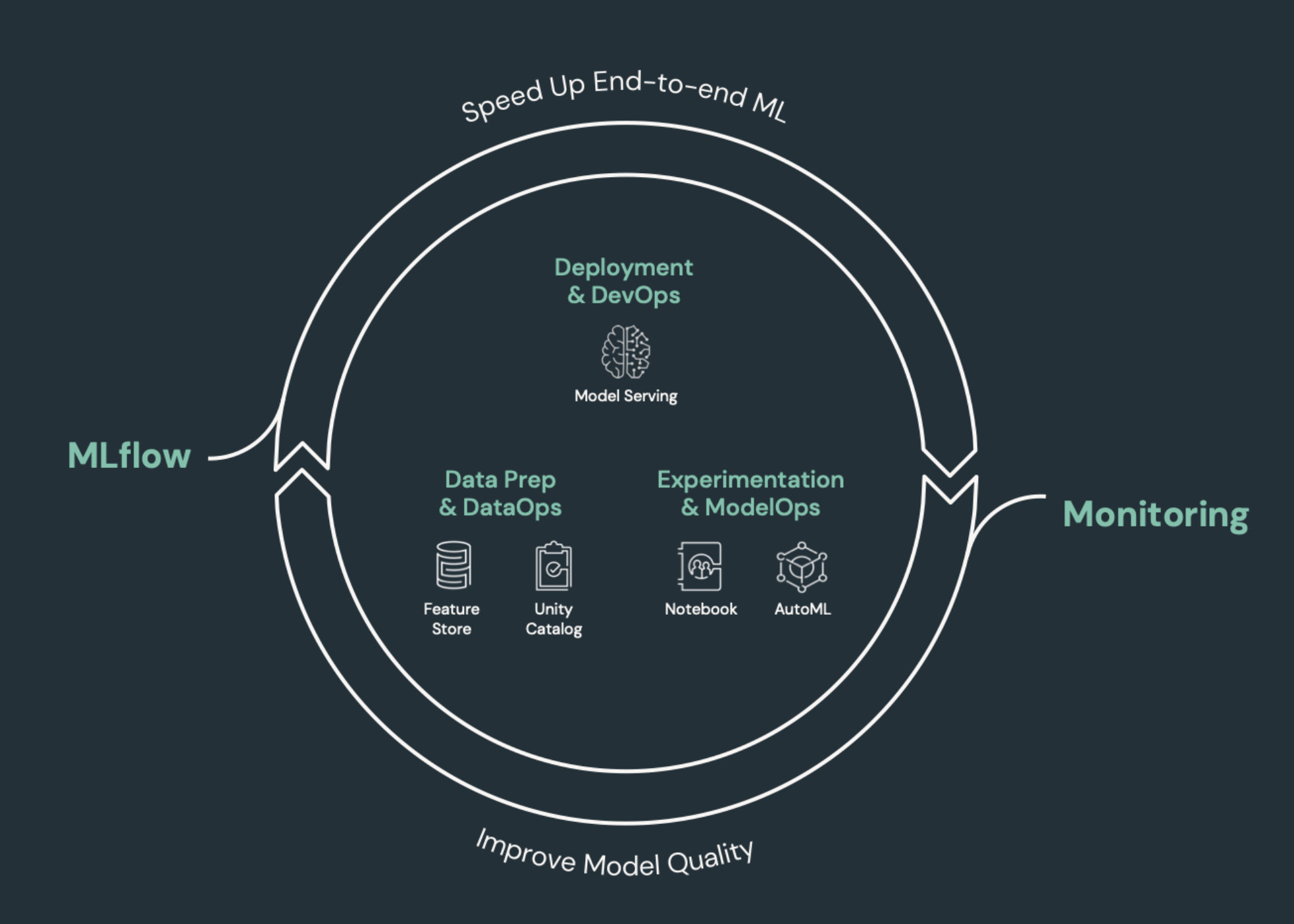
Maskininlärningselement som behöver CI/CD
En av utmaningarna med ML-utveckling är att olika team äger olika delar av processen. Teams kan förlita sig på olika verktyg och ha olika versionsscheman. Azure Databricks tillhandahåller en enda, enhetlig data- och ML-plattform med integrerade verktyg för att förbättra teamens effektivitet och säkerställa konsekvens och repeterbarhet för data och ML-pipelines.
I allmänhet för maskininlärningsuppgifter bör följande spåras i ett automatiserat CI/CD-arbetsflöde:
- Träningsdata, inklusive datakvalitet, schemaändringar och distributionsändringar.
- Indatapipelines.
- Kod för träning, validering och servering av modellen.
- Modellförutsägelser och prestanda.
Integrera Databricks i dina CI/CD-processer
MLOps, DataOps, ModelOps och DevOps refererar till integreringen av utvecklingsprocesser med "åtgärder" – vilket gör processerna och infrastrukturen förutsägbara och tillförlitliga. Den här uppsättningen artiklar beskriver hur du integrerar principer för åtgärder ("ops") i dina ML-arbetsflöden på Databricks-plattformen.
Databricks innehåller alla komponenter som krävs för ML-livscykeln, inklusive verktyg för att skapa "konfiguration som kod" för att säkerställa reproducerbarhet och "infrastruktur som kod" för att automatisera etableringen av molntjänster. Den innehåller även loggnings- och aviseringstjänster som hjälper dig att identifiera och felsöka problem när de inträffar.
DataOps: Tillförlitliga och säkra data
Bra ML-modeller är beroende av tillförlitliga datapipelines och infrastruktur. Med Databricks Data Intelligence Platform finns hela datapipelinen från att mata in data till utdata från den betjänade modellen på en enda plattform och använder samma verktygsuppsättning, vilket underlättar produktivitet, reproducerbarhet, delning och felsökning.

DataOps-uppgifter och -verktyg i Databricks
Tabellen visar vanliga DataOps-uppgifter och -verktyg i Databricks:
| DataOps-uppgift | Verktyg i Databricks |
|---|---|
| Mata in och transformera data | Autoloader och Apache Spark |
| Spåra ändringar av data, inklusive versionshantering och ursprung | Deltatabeller |
| Skapa, hantera och övervaka pipelines för databearbetning | Delta Live-tabeller |
| Säkerställa datasäkerhet och styrning | Unity-katalog |
| Undersökande dataanalys och instrumentpaneler | Databricks SQL, instrumentpaneler och Databricks-notebook-filer |
| Allmän kodning | Databricks SQL - och Databricks-notebook-filer |
| Schemalägga datapipelines | Databricks-jobb |
| Automatisera allmänna arbetsflöden | Databricks-jobb |
| Skapa, lagra, hantera och identifiera funktioner för modellträning | Databricks-funktionslager |
| Dataövervakning | Lakehouse-övervakning |
ModelOps: Modellutveckling och livscykel
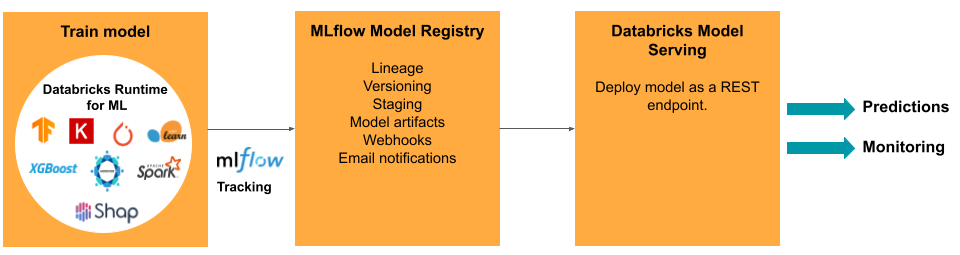
Att utveckla en modell kräver en serie experiment och ett sätt att spåra och jämföra villkoren och resultaten av dessa experiment. Databricks Data Intelligence Platform innehåller MLflow för modellutvecklingsspårning och MLflow Model Registry för att hantera modelllivscykeln, inklusive mellanlagring, servering och lagring av modellartefakter.
När en modell har släppts till produktion kan många saker ändras som kan påverka dess prestanda. Förutom att övervaka modellens förutsägelseprestanda bör du även övervaka indata för ändringar i kvalitet eller statistiska egenskaper som kan kräva omträning av modellen.
ModelOps-uppgifter och verktyg i Databricks
Tabellen innehåller vanliga ModelOps-uppgifter och verktyg som tillhandahålls av Databricks:
| ModelOps-uppgift | Verktyg i Databricks |
|---|---|
| Spåra modellutveckling | Spårning av MLflow-modell |
| Hantera modelllivscykel | Modeller i Unity-katalogen |
| Versionskontroll och delning av modellkod | Databricks Git-mappar |
| Utveckling utan kodmodell | AutoML |
| Modellövervakning | Lakehouse-övervakning |
DevOps: Produktion och automatisering
Databricks-plattformen stöder ML-modeller i produktion med följande:
- Data från slutpunkt till slutpunkt och modell härkomst: Från modeller i produktion tillbaka till rådatakällan på samma plattform.
- Modellservering på produktionsnivå: Skalas automatiskt upp eller ned baserat på dina affärsbehov.
- Jobb: Automatiserar jobb och skapar schemalagda arbetsflöden för maskininlärning.
- Git-mappar: Kodversioner och delning från arbetsytan hjälper även team att följa metodtips för programvaruutveckling.
- Databricks Terraform-provider: Automatiserar distributionsinfrastrukturen mellan moln för ML-slutsatsdragningsjobb, servering av slutpunkter och funktionaliseringsjobb.
Modellservering
För att distribuera modeller till produktion förenklar MLflow processen avsevärt, vilket ger distribution med ett enda klick som ett batchjobb för stora mängder data eller som en REST-slutpunkt i ett autoskalningskluster. Integreringen av Databricks Feature Store med MLflow säkerställer även konsekvens av funktioner för träning och servering. MLflow-modeller kan också automatiskt söka efter funktioner från funktionsarkivet, även för servering med låg svarstid online.
Databricks-plattformen stöder många distributionsalternativ för modeller:
- Kod och containrar.
- Batch-servering.
- Onlineservering med låg svarstid.
- Servering på enheten eller gränsen.
- Flera moln, till exempel, tränar modellen i ett moln och distribuerar den med ett annat.
Mer information finns i Mosaik AI-modellservering.
Projekt
Med Databricks-jobb kan du automatisera och schemalägga alla typer av arbetsbelastningar, från ETL till ML. Databricks stöder också integreringar med populära tredjepartsorkestratorer som Airflow.
Git-mappar
Databricks-plattformen innehåller Git-stöd på arbetsytan för att hjälpa team att följa metodtips för programvaruutveckling genom att utföra Git-åtgärder via användargränssnittet. Administratörer och DevOps-tekniker kan använda API:er för att konfigurera automatisering med sina favoritverktyg för CI/CD. Databricks stöder alla typer av Git-distributioner, inklusive privata nätverk.
Mer information om metodtips för kodutveckling med Hjälp av Databricks Git-mappar finns i CI/CD-arbetsflöden med Git-integrering och Git-mappar för Databricks och Använd CI/CD. Med de här teknikerna kan du tillsammans med Databricks REST API skapa automatiserade distributionsprocesser med GitHub Actions, Azure DevOps-pipelines eller Jenkins-jobb.
Unity Catalog för styrning och säkerhet
Databricks-plattformen innehåller Unity Catalog, som låter administratörer konfigurera detaljerad åtkomstkontroll, säkerhetsprinciper och styrning för alla data och AI-tillgångar i Databricks.